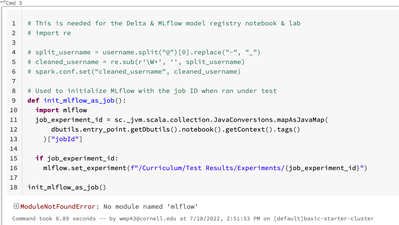
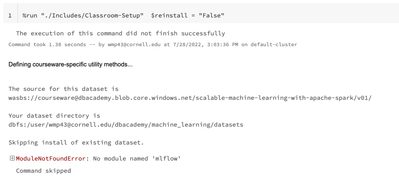
I new to the scalable machine learning with apache spark course. I am in the notebook ML 00a - Install Datasets it includes one cell (attached) which throws an error 'no module named 'mlflow''. It attempts to run the Classroom-Setup file. Error is th...
Hello everyone,We are experimenting with several approaches in a Machine Learning project ( binary classification), and we would like to keep track of those using MLFlow. We are using the feature store to build, store, and retrieve the features, and ...
I am running into an error within the Databricks notebook (on Databricks website) environment where MLFlow will not load:
MLflow autologging encountered a warning: "/databricks/python/lib/python3.8/site-packages/mlflow/utils/autologging_utils/safet...
Install the Databricks SQL Connector for Python library on your development machine by running pip install databricks-sql-connector .Query data. Insert data. Query metadata. Cursor and connection management. Configure logging.Regards,Willjoe
I am planning to deploy MLFlow server deployed in AWS ECS as a centralised repositories for my machine learning experiments and runs and to strore events and artifacts. I would like to use MLflow Tracking Server enabled with proxied artifact storage ...
Hi @Naveen Marthala, Just a friendly follow-up. Do you still need help, or @Joseph Kambourakis 's response help you to find the solution? Please let us know.
Hi Team,I am getting the following error (mlflow.utils.databricks_utils._NoDbutilsError) while trying to register model using applyInPandas to another databricks workspace. I have already set the secret scope and prefix to authenticate against the 2n...
Would it be possible to somehow save the data, metrics of all experiments captured by self-managed mlflow using A/mazon RDS, S3 as backend and then load it to databricks managed mlflow and make it available in the UI? This is required as a part of mi...
I am logging runs from jupyter notebook. the cells which has `mlflow.sklearn.autlog()` behaves as expected. but, the cells which has .fit() method being called on sklearn's estimators are also being logged as runs without explicitly mentioning `mlflo...
Is it possible to create mlflow model as a docker image with REST api endpoint and use it for inferencing within databricks or hosting the image in azure container instances?
Databricks Roadmap AzureThere are a lot of excitement new features coming in 2022. I tried to put them all on one list:Unity catalog (seems that it will exists next to hive metastore and it will be possible to migrate)Control metastore, unity creatio...
Hi @Hubert Dudek , We know the world is full of choices. Thank you for choosing us! We would like to thank excellent customers like you for your support. We couldn’t do it without you!
It looks like you can via MLflow but I wanted to check before diving deeper?Also it seems like if it is possible, it's just for small scale experimentation?Thank you!
As I am moving my first steps within the Databricks Machine Learning Workspace, I am getting confused by some features that by "documentation" seem to overlap. Does autolog for spark on mlflow provide different tracking than using a training set crea...
Hi @Edmondo Porcu , FeatureStoreClient.log_model() logs an MLflow model packaged with feature lookup information.Sourcemlflow.spark.autolog(disable=False, silent=False) enables (or disables) and configures logging of Spark data source paths, versio...
I'm fitting multiple models in parallel. For each one, I'm logging lots of params and metrics to MLflow. I'm hitting rate limits, causing problems in my jobs.
The first thing to try is to log in batches. If you are logging each param and metric separately, you're making 1 API call per param and 1 per metric. Instead, you should use the batch logging APIs; e.g. use "log_params" instead of "log_param" http...
I am facing an issue in loading a ML artifact for a specific run by search the experiment runs to get a specific run_id as follows:https://www.mlflow.org/docs/latest/rest-api.html#search-runsAPI request to https://eastus-c3.azuredatabricks.net/api/2....
Yes, you will hit rate limits if you try to query the API so fast in parallel. Do you just want to manipulate the run data in an experiment with Spark? you can simply load all that data in a DataFrame with spark.read.format("mlflow-experiment").load(...
Hi,I am trying to follow this simple document to be able to run MLFlow within Databricks: https://docs.microsoft.com/en-us/azure/databricks/applications/mlflow/projectsI try to run it from: A Databricks notebook within Azure DatabricksBy use of the m...
Maybe this answer will help:https://community.databricks.com/s/question/0D53f00001UOu7rCAD/mlflow-resourcealreadyexistsas @Prabakar Ammeappin wrote " it’s not recommended to “link” the Databricks and AML workspaces, as we are seeing more problems"