- 21377 Views
- 5 replies
- 6 kudos
Resolved! Fix Hanging Task in Databricks
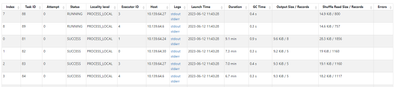
I am applying a pandas UDF to a grouped dataframe in databricks. When I do this, a couple tasks hang forever, while the rest complete quickly.I start by repartitioning my dataset so that each group is in one partition:group_factors = ['a','b','c'] #m...


- 21377 Views
- 5 replies
- 6 kudos
Latest Reply
- 6 kudos
Thank you Suteja. I had watched the resources and had never reached capacity for any. The data was evenly distributed across partitions and groups as well. I did end up taking your advice in (1). I set a timer and killed the process if the group took...
- 6 kudos