- 12437 Views
- 4 replies
- 1 kudos
Permission denied: Lightning Logs
I'm doing parameter tuning for a NeuralProphet model (you can see in the image the parameters and code for training)When I try to parallelize the training, it gives me Permission Error.Why can't I access the folder '/databricks/spark/work/*'? Do I ne...
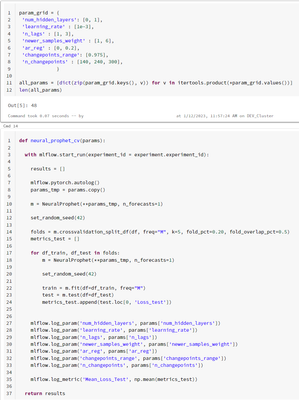
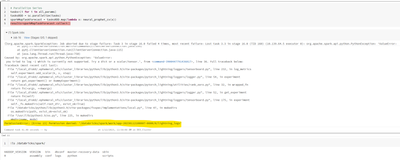
- 12437 Views
- 4 replies
- 1 kudos
- 1 kudos
Hi Ruben!I am facing exactly the same error running a similar approach when using runtime 16.2 ML. I didn't have this issue when using runtime 12.2 LTS ML or 13.3 ML. Did you find a solution?Many thanks!
- 1 kudos
- 3547 Views
- 2 replies
- 0 kudos
Rollback cluster changes
Is it possible to rollback changes made to a cluster? The problem I'm trying to solve is to recover from an accidental change made by a user on a cluster that affects interactive and job runs. Cluster policies help, but the policy still provides the ...
- 3547 Views
- 2 replies
- 0 kudos
- 0 kudos
@User16826990884 Along with what @sajith_appukutt mentioned, we can achive this viaVersion Control for Cluster Configurations: Store cluster configurations in JSON files in GitHub or another version control system.In case of accidental changes, you c...
- 0 kudos
- 2440 Views
- 1 replies
- 7 kudos
Train machine learning models: How can I take my ML lifecycle from experimentation to production?
Note: the following guide is primarily for Python users. For other languages, please view the following links: • Table batch reads and writes • Create a table in SQL • Visualizing data with DBSQLThis step-by-step guide will get your data...




- 2440 Views
- 1 replies
- 7 kudos
- 7 kudos
I got good knowledge by your post . It is very clear . Thank you . Keep sharing like this posts .It will be helpful
- 7 kudos
- 8861 Views
- 1 replies
- 0 kudos
Failed to add 1 container to the cluster. will attempt retry: false. reason: bootstrap timeout
Hi Team,When creating a new cluster in a workspace within a VNET receiving this error:Failed to add 1 container to the cluster. will attempt retry: false. reason: bootstrap timeoutCluster terminated. Reason: Bootstrap TimeoutCheers.Gil
- 8861 Views
- 1 replies
- 0 kudos
- 0 kudos
@Gil Gonong :The error message you are receiving suggests that the creation of the new cluster has failed due to a bootstrap timeout. The bootstrap process is responsible for setting up the initial configuration of the cluster, and if it takes too l...
- 0 kudos
- 8448 Views
- 6 replies
- 7 kudos
How are dashboards served and what would happen to them if the cluster attached to the notebook terminates?
I have two dashboards in presentation mode both from notebooks being run on the same compute cluster. Last night the cluster terminated due to idle time and in the morning one of my dashboards was fine but the other one was set to the default stab di...
- 8448 Views
- 6 replies
- 7 kudos
- 7 kudos
If your query were scheduled, it's automatically started the cluster at the scheduled time Or might be possible that the portion that is still visible doesn't need to be generated so it looks like it's working but it is just left over from the prior...
- 7 kudos
- 5506 Views
- 3 replies
- 2 kudos
How to solve cluster break down due to GC when training a pyspark.ml Random Forest
I am trying to train and optimize a random forest. At first the cluster handles the garbage collection fine, but after a couple of hours the cluster breaks down as Garbage Collection has gone up significantly.The train_df has a size of 6,365,018 reco...
- 5506 Views
- 3 replies
- 2 kudos
- 2 kudos
The cache is expensive and wants to save that data to memory and disk (id there is no more space left in memory). I know that, in theory, it should improve, but it can make things worse. I would just putscaled_train_data = pipeline_data.transform(tra...
- 2 kudos
- 2805 Views
- 3 replies
- 0 kudos
No saved model after stopping the cluster.
I have saved a keras model in some directories in dbfs to load and retrain that with more data, etc. The problem is that when cluster stops and restarts, seems those directories and model are no longer available there and it starts training a new mod...
- 2805 Views
- 3 replies
- 0 kudos
- 0 kudos
Hi @Vidula Khanna I figured it out by replacing OS library module with dbutils utilities. It looks like mre compatible with DBFS.
- 0 kudos
- 6041 Views
- 4 replies
- 2 kudos
Resolved! Cluster setup for ML work for Pandas in Spark, and vanilla Python.
My setup:Worker type: Standard_D32d_v4, 128 GB Memory, 32 Cores, Min Workers: 2, Max Workers: 8Driver type: Standard_D32ds_v4, 128 GB Memory, 32 CoresDatabricks Runtime Version: 10.2 ML (includes Apache Spark 3.2.0, Scala 2.12)I ran a snowflake quer...
- 6041 Views
- 4 replies
- 2 kudos
- 2 kudos
Hey there @Vivek Ranjan Checking in. If Joseph's answer helped, would you let us know and mark the answer as best? It would be really helpful for the other members to find the solution more quickly.Thanks!
- 2 kudos
- 31944 Views
- 2 replies
- 4 kudos
Resolved! Problem with spinning up a cluster on a new workspace
Error: Please check network connectivity from the data plane to the control plane.{ "reason": { "code": "BOOTSTRAP_TIMEOUT", "parameters": { "databricks_error_message": "[id: InstanceId(i-0457092c), status: INSTANCE_INITIALIZING, workerEnvId:...
- 31944 Views
- 2 replies
- 4 kudos
- 4 kudos
Can you please get the system logs from AWS EC2 console as soon the cluster fails - System Logs for the failed instance will be accessible from the AWS console up to an hour after the shutdown.AWS console clears the references of terminated clusters ...
- 4 kudos
- 4186 Views
- 4 replies
- 0 kudos
How do you control the cost of provisioning a cluster?
How do you govern the cost of running clusters in Databricks so you're not sticker shocked?
- 4186 Views
- 4 replies
- 0 kudos
- 0 kudos
Less use of Interactive cluster and more use of job cluster can one of the way above others
- 0 kudos
-
Access control
3 -
Access Data
2 -
AccessKeyVault
1 -
ADB
2 -
Airflow
1 -
Amazon
2 -
Apache
1 -
Apache spark
3 -
APILimit
1 -
Artifacts
1 -
Audit
1 -
Autoloader
6 -
Autologging
2 -
Automation
2 -
Automl
45 -
Aws databricks
1 -
AWSSagemaker
1 -
Azure
32 -
Azure active directory
1 -
Azure blob storage
2 -
Azure data lake
1 -
Azure Data Lake Storage
3 -
Azure data lake store
1 -
Azure databricks
32 -
Azure event hub
1 -
Azure key vault
1 -
Azure sql database
1 -
Azure Storage
2 -
Azure synapse
1 -
Azure Unity Catalog
1 -
Azure vm
1 -
AzureML
2 -
Bar
1 -
Beta
1 -
Better Way
1 -
BI Integrations
1 -
BI Tool
1 -
Billing and Cost Management
1 -
Blob
1 -
Blog
1 -
Blog Post
1 -
Broadcast variable
1 -
Business Intelligence
1 -
CatalogDDL
1 -
Centralized Model Registry
1 -
Certification
2 -
Certification Badge
1 -
Change
1 -
Change Logs
1 -
Check
2 -
Classification Model
1 -
Cloud Storage
1 -
Cluster
10 -
Cluster policy
1 -
Cluster Start
1 -
Cluster Termination
2 -
Clustering
1 -
ClusterMemory
1 -
CNN HOF
1 -
Column names
1 -
Community Edition
1 -
Community Edition Password
1 -
Community Members
1 -
Company Email
1 -
Condition
1 -
Config
1 -
Configure
3 -
Confluent Cloud
1 -
Container
2 -
ContainerServices
1 -
Control Plane
1 -
ControlPlane
1 -
Copy
1 -
Copy into
2 -
CosmosDB
1 -
Courses
2 -
Csv files
1 -
Dashboards
1 -
Data
8 -
Data Engineer Associate
1 -
Data Engineer Certification
1 -
Data Explorer
1 -
Data Ingestion
2 -
Data Ingestion & connectivity
11 -
Data Quality
1 -
Data Quality Checks
1 -
Data Science & Engineering
2 -
databricks
5 -
Databricks Academy
3 -
Databricks Account
1 -
Databricks AutoML
9 -
Databricks Cluster
3 -
Databricks Community
5 -
Databricks community edition
4 -
Databricks connect
1 -
Databricks dbfs
1 -
Databricks Feature Store
1 -
Databricks Job
1 -
Databricks Lakehouse
1 -
Databricks Mlflow
4 -
Databricks Model
2 -
Databricks notebook
10 -
Databricks ODBC
1 -
Databricks Platform
1 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Runtime
9 -
Databricks SQL
8 -
Databricks SQL Permission Problems
1 -
Databricks Terraform
1 -
Databricks Training
2 -
Databricks Unity Catalog
1 -
Databricks V2
1 -
Databricks version
1 -
Databricks Workflow
2 -
Databricks Workflows
1 -
Databricks workspace
2 -
Databricks-connect
1 -
DatabricksContainer
1 -
DatabricksML
6 -
Dataframe
3 -
DataSharing
1 -
Datatype
1 -
DataVersioning
1 -
Date Column
1 -
Dateadd
1 -
DB Notebook
1 -
DB Runtime
1 -
DBFS
5 -
DBFS Rest Api
1 -
Dbt
1 -
Dbu
1 -
DDL
1 -
DDP
1 -
Dear Community
1 -
DecisionTree
1 -
Deep learning
4 -
Default Location
1 -
Delete
1 -
Delt Lake
4 -
Delta lake table
1 -
Delta Live
1 -
Delta Live Tables
6 -
Delta log
1 -
Delta Sharing
3 -
Delta-lake
1 -
Deploy
1 -
DESC
1 -
Details
1 -
Dev
1 -
DevOps
1 -
Df
1 -
Different Notebook
1 -
Different Parameters
1 -
DimensionTables
1 -
Directory
3 -
Disable
1 -
Distribution
1 -
DLT
6 -
DLT Pipeline
3 -
Dolly
5 -
Dolly Demo
2 -
Download
2 -
EC2
1 -
Emr
2 -
Ensemble Models
1 -
Environment Variable
1 -
Epoch
1 -
Error handling
1 -
Error log
2 -
Eventhub
1 -
Example
1 -
Experiments
4 -
External Sources
1 -
Extract
1 -
Fact Tables
1 -
Failure
2 -
Feature Lookup
2 -
Feature Store
62 -
Feature Store API
2 -
Feature Store Table
1 -
Feature Table
6 -
Feature Tables
4 -
Features
2 -
FeatureStore
2 -
File Path
2 -
File Size
1 -
Fine Tune Spark Jobs
1 -
Forecasting
2 -
Forgot Password
2 -
Garbage Collection
1 -
Garbage Collection Optimization
1 -
Github
2 -
Github actions
2 -
Github Repo
2 -
Gitlab
1 -
GKE
1 -
Global Init Script
1 -
Global init scripts
4 -
Governance
1 -
Hi
1 -
Horovod
1 -
Html
1 -
Hyperopt
4 -
Hyperparameter Tuning
2 -
Iam
1 -
Image
3 -
Image Data
1 -
Inference Setup Error
1 -
INFORMATION
1 -
Input
1 -
Insert
1 -
Instance Profile
1 -
Int
2 -
Interactive cluster
1 -
Internal error
1 -
Invalid Type Code
1 -
IP
1 -
Ipython
1 -
Ipywidgets
1 -
JDBC Connections
1 -
Jira
1 -
Job
4 -
Job Parameters
1 -
Job Runs
1 -
Join
1 -
Jsonfile
1 -
Kafka consumer
1 -
Key Management
1 -
Kinesis
1 -
Lakehouse
1 -
Large Datasets
1 -
Latest Version
1 -
Learning
1 -
Limit
3 -
LLM
3 -
LLMs
3 -
Local computer
1 -
Local Machine
1 -
Log Model
2 -
Logging
1 -
Login
1 -
Logs
1 -
Long Time
2 -
Low Latency APIs
2 -
LTS ML
3 -
Machine
3 -
Machine Learning
24 -
Machine Learning Associate
1 -
Managed Table
1 -
Max Retries
1 -
Maximum Number
1 -
Medallion Architecture
1 -
Memory
3 -
Metadata
1 -
Metrics
3 -
Microsoft azure
1 -
ML Lifecycle
4 -
ML Model
4 -
ML Practioner
3 -
ML Runtime
1 -
MlFlow
75 -
MLflow API
5 -
MLflow Artifacts
2 -
MLflow Experiment
6 -
MLflow Experiments
3 -
Mlflow Model
10 -
Mlflow registry
3 -
Mlflow Run
1 -
Mlflow Server
5 -
MLFlow Tracking Server
3 -
MLModels
2 -
Model Deployment
4 -
Model Lifecycle
6 -
Model Loading
2 -
Model Monitoring
1 -
Model registry
5 -
Model Serving
29 -
Model Serving Cluster
2 -
Model Serving REST API
6 -
Model Training
2 -
Model Tuning
1 -
Models
8 -
Module
3 -
Modulenotfounderror
1 -
MongoDB
1 -
Mount Point
1 -
Mounts
1 -
Multi
1 -
Multiline
1 -
Multiple users
1 -
Nested
1 -
New Feature
1 -
New Features
1 -
New Workspace
1 -
Nlp
3 -
Note
1 -
Notebook
6 -
Notification
2 -
Object
3 -
Onboarding
1 -
Online Feature Store Table
1 -
OOM Error
1 -
Open Source MLflow
4 -
Optimization
2 -
Optimize Command
1 -
OSS
3 -
Overwatch
1 -
Overwrite
2 -
Packages
2 -
Pandas udf
4 -
Pandas_udf
1 -
Parallel
1 -
Parallel processing
1 -
Parallel Runs
1 -
Parallelism
1 -
Parameter
2 -
PARAMETER VALUE
2 -
Partner Academy
1 -
Pending State
2 -
Performance Tuning
1 -
Photon Engine
1 -
Pickle
1 -
Pickle Files
2 -
Pip
2 -
Points
1 -
Possible
1 -
Postgres
1 -
Pricing
2 -
Primary Key
1 -
Primary Key Constraint
1 -
Progress bar
2 -
Proven Practices
2 -
Public
2 -
Pymc3 Models
2 -
PyPI
1 -
Pyspark
6 -
Python
21 -
Python API
1 -
Python Code
1 -
Python Function
3 -
Python Libraries
1 -
Python Packages
1 -
Python Project
1 -
Pytorch
3 -
Reading-excel
2 -
Redis
2 -
Region
1 -
Remote RPC Client
1 -
RESTAPI
1 -
Result
1 -
Runtime update
1 -
Sagemaker
1 -
Salesforce
1 -
SAP
1 -
Scalability
1 -
Scalable Machine
2 -
Schema evolution
1 -
Script
1 -
Search
1 -
Security
2 -
Security Exception
1 -
Self Service Notebooks
1 -
Server
1 -
Serverless
1 -
Serving
1 -
Shap
2 -
Size
1 -
Sklearn
1 -
Slow
1 -
Small Scale Experimentation
1 -
Source Table
1 -
Spark config
1 -
Spark connector
1 -
Spark Error
1 -
Spark MLlib
2 -
Spark Pandas Api
1 -
Spark ui
1 -
Spark Version
2 -
Spark-submit
1 -
SparkML Models
2 -
Sparknlp
3 -
Spot
1 -
SQL
19 -
SQL Editor
1 -
SQL Queries
1 -
SQL Visualizations
1 -
Stage failure
2 -
Storage
3 -
Stream
2 -
Stream Data
1 -
Structtype
1 -
Structured streaming
2 -
Study Material
1 -
Summit23
2 -
Support
1 -
Support Team
1 -
Synapse
1 -
Synapse ML
1 -
Table
4 -
Table access control
1 -
Tableau
1 -
Task
1 -
Temporary View
1 -
Tensor flow
1 -
Test
1 -
Timeseries
1 -
Timestamps
1 -
TODAY
1 -
Training
6 -
Transaction Log
1 -
Trying
1 -
Tuning
2 -
UAT
1 -
Ui
1 -
Unexpected Error
1 -
Unity Catalog
12 -
Use Case
2 -
Use cases
1 -
Uuid
1 -
Validate ML Model
2 -
Values
1 -
Variable
1 -
Vector
1 -
Versioncontrol
1 -
Visualization
2 -
Web App Azure Databricks
1 -
Weekly Release Notes
2 -
Whl
1 -
Worker Nodes
1 -
Workflow
2 -
Workflow Jobs
1 -
Workspace
2 -
Write
1 -
Writing
1 -
Z-ordering
1 -
Zorder
1
- « Previous
- Next »