Hello, I am trying to replicate this motebook in my environment: mlflow-end-to-end-example - Databricks However, I am getting the following error when I run "import mlflow": "TypeError: bases must be types"How can I solve this issue? Thank you, Tanji...
Can you share the specific cell of the notebook where you are receiving this error? Have you modified the code or it is the same? Do you have any particular libraries installed on the cluster you are using for the testing?
I am getting the following error while saving a delta table in the feature storeWARNING databricks.feature_store._catalog_client_helper: Failed to record data sources in the catalog. Exception: {'error_code': 'INVALID_PARAMETER_VALUE', 'message': 'To...
Hi @yorabhir,
Verify how many sources you’re trying to record in the catalog. If it exceeds 100, you’ll need to reduce the number of sources.Ensure that the feature table creation process is correctly configured. In your code snippet, you’re creatin...
Hi, I am using multiple feature stores in my workflow using feature lookups. In my logged pipeline, I have several stages, including Assembler, Standard Scaler, Indexer and then Model. However, I am facing an issue during inference using the `score b...
Hi @NaeemS , Handling null values in feature stores is crucial to ensure robustness and reliability in your machine learning pipelines.
Let’s explore some strategies to address this issue:
Custom Transformer Stage:
You’ve already considered addin...
Hi Everyone. I have a couple of questions about the feature store log model and score batch. After you log a model with the feature store then use fs.score_batch is it possible to pass the env_manager to predict with the same env as training as descr...
I am trying to track the lineage of model and tables using the FeatureEngineeringClient. The table lineage shows the relevant tables and notebooks but the model lineage shows only the model. No notebook and tables. here is my code fe = FeatureEngine...
ok I realized something else. That although I used FeatureEngineeringCient, MLflow model artifact suggest I used FeatureStoreClient. Please see attachment.
I have a pyfunc model that I can use to get predictions. It takes time series data with context information at each date, and produces a string of predictions. For example:The data is set up like below (temp/pressure/output are different than my inpu...
Our small team has just finished the data preparation phase of our project and started data analysis in Databricks. As we go deeper into this field, we're trying to understand the distinctions and appropriate uses for a Feature Store versus a Unity C...
Hi @Northp Good day!1.) A Feature Store is a centralized repository that enables data scientists to find and share features, ensuring that the same code used to compute the feature values is used for model training and inference. It is particularly...
Yes, Databricks feature tables can be stored outside of Databricks File System (DBFS). You can store your feature tables in external storage systems such as Amazon S3, Azure Blob Storage, Azure Data Lake Storage, or Hadoop Distributed File System (HD...
I've created a dataset that I want to create a feature store table for. I created a database in my dev unity catalog to store the feature tables, but each time I try to create the table I get this error:ValueError: Invalid catalog 'dev' or schema 'fe...
Hello,The error message suggests that there might be an issue with the catalog or schema name you are using when trying to create the feature store table. Here are a few tips to help you troubleshoot this problem:Verify the catalog and schema names: ...
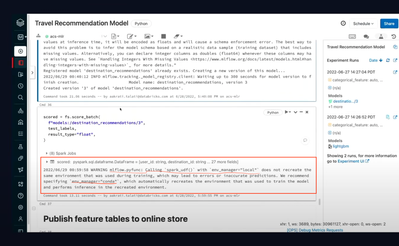
When I try to serve a model stored with FeatureStoreClient().log_model using the feature-store-online-example-cosmosdb tutorial Notebook, I get errors suggesting that the primary key schema is not configured properly. However, if I look in the Featur...
Hello @Thomas Michielsen , this error seems to occur when you may have created the table yourself. You must use publish_table() to create the table in the online store. Do not manually create a database or container inside Cosmos DB. publish_table()...
Could someone explain the practical advantages of using a feature store vs. Delta Lake. apparently they both work in the same manner and the feature store does not provide additional value. However, based on the documentation on the databricks page, ...
Hi @Saeid Hedayati Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answer...
Hi everyone,Would it be possible to change the default storage path of deature store, during creation and/or after creation? If you could also provide the python script to that I would appreciate. The current default path is:"dbfs/user/hive/warehouse...
Hi @Saeid Hedayati Hope everything is going great.Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us s...
I'm using databricks. Trying to log a model to MLflow using the Feature Store log_model function. but I have this error: TypeError: join() argument must be str, bytes, or os.PathLike object, not 'dict' I'am using the Databricks runtime ml (10.4 LTS M...
Yes You can. With Databricks Runtime 12.2 LTS ML and above, you can use existing feature tables in Feature Store to augment the original input dataset for all of your AutoML problems: classification, regression, and forecasting.This capability requi...
We are building an machine learning application with feature store enabled. Once the model is built, we are trying to move the model artifacts and deploy it in azure ml as online endpoint. Does it possible to access the online store in azure ml endpo...
if you want databricks to use the feature store, which is in Cosmos DB, yes, it is possible https://learn.microsoft.com/en-us/azure/databricks/machine-learning/feature-store/online-feature-storessuppose you want to consume a future store in Databrick...