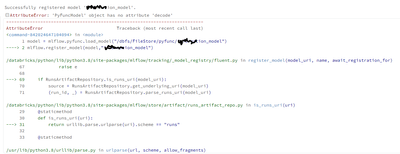
Hi,I have a PyTorch model which I have pushed into the dbfs now I want to serve the model using MLflow. I saw that the model needs to be in python_function model.To do that I did the following methods1. load the model from dbfs using torch load optio...
I think you want to use mflow to load the model not pytorch. There is a function in mlflow to load pytorch models https://www.mlflow.org/docs/latest/python_api/mlflow.pytorch.html#mlflow.pytorch.load_modelThen once it's loaded, you can log it and re...
ML flow model serving in Databricks docs details the options to enable and disable from the UIhttps://docs.databricks.com/applications/mlflow/model-serving.html
Please find below the REST APIs to enable and disable Model-ServingBelow are the examples in PythonYou need to use the token to interact with Rest APItoken = "dxxxxxx"instance = "https://<workspacexxx>.cloud.databricks.com"headers = {'Authorization':...
2021-09 webinar: Automating the ML Lifecycle With Databricks Machine Learning (Post 2 of 2)Thank you to everyone who joined! You can access the on-demand recording here and the code in this Github repo.We're sharing a subset of the questions asked an...
2021-09 webinar: Automating the ML Lifecycle With Databricks Machine Learning (post 1 of 2)Thank you to everyone who joined the Automating the ML Lifecycle With Databricks Machine Learning webinar! You can access the on-demand recording here and the ...
I have run a few MLflow experiments and I can see them in the experiment history, but none of the metrics have been logged along with them. I thought this was supposed to be automatically included. Any idea why they wouldn't be showing up?
Hi @ trevor.bishop! My name is Kaniz, and I'm the technical moderator here. Great to meet you, and thanks for your question! Let's see if your peers on the Forum have an answer to your question first. Or else I will follow up shortly with a response.
Wondering about best practices for how to handle collaboration between multiple ML practitioners working on a single experiment. Do we have to share the same notebook between people or is it possible to have individual notebooks going but still work ...
Yes, multiple users could work on individual notebooks and still use the same experiment via mlflow.set_experiment(). You could also assign different permission levels to experiments from a governance point of view
The default location or MLflow artifacts is on dbfs, but I would like to save my models to an alternative location. Is this supported, and if it is how can I accomplish it?
You could mount an s3 bucket in the workspace and save your model using the mounts DBFS path For e.gmodelpath = "/dbfs/my-s3-bucket/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
I'm trying to create a new experiment on mlflow but I have this problem:Exception: Run with UUID l142ae5a7cf04a40902ae9ed7326093c is already active. snippet mlflow.set_experiment("New experiment 2")
mlflow.set_tracking_uri('http://mlflow:5000')
...
If you are hosting your own mlflow tracking server, the framework supports database dialects mysql, mssql, sqlite, and postgresql. It'd be your responsibility to take backups ( systems like RDS with automated backup makes this easier )If you are us...
Good question! I'll divide my suggestions into 2 parts:(1) In terms of MLflow Tracking, clustering is pretty similar to other ML workflows, so not much changes.(2) In terms of specific parameters, metrics, etc. to track, clustering is very different...
I am using ML flow and my need of the hour is to delete an experiment and want to create another experiment with same run.client = MlflowClient(tracking_uri=server)
client.delete_experiment(1)This deletes the experiment, but when I run a new experim...
SQL Database:This is more tricky, as there are dependencies that need to be deleted. I am using MySQL, and these commands work for me:USE mlflow_db; # the name of your database
DELETE FROM experiment_tags WHERE experiment_id=ANY(
SELECT experime...
You can find a lot more info on this at this MLflow product page, including a comparison table at the bottom. I'd summarize that comparison as: Databricks provides three key things in its managed MLflow service.Security: MLflow experiments, models, ...
You can find the MLflow version in the runtime release notes, along with a list of every other library provided. E.g., for DBR 8.3 ML, you can look at the release notes for AWS, Azure, or GCP.The MLflow client API (i.e., the API provided by installi...
The following resources provide more detail on this:Databricks model registry example notebook: https://docs.databricks.com/_static/notebooks/mlflow/mlflow-model-registry-example.htmlDatabricks model lifecycle - https://docs.databricks.com/applicatio...