Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Re: com.amazonaws.services.s3.model.AmazonS3Except...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
com.amazonaws.services.s3.model.AmazonS3Exception: The bucket is in this region: *** when using S3 Select
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 10:02 AM
Hello,
I have a cluster running in us-east-1 region.
I hava a Spark job loading data in a DataFrame using s3select format on a bucket in eu-west-1 region.
Access and Secret keys are encoded in URI s3a://$AccessKey:$SecretKey@bucket/path/to/dir
Job fails with followong stacktrace
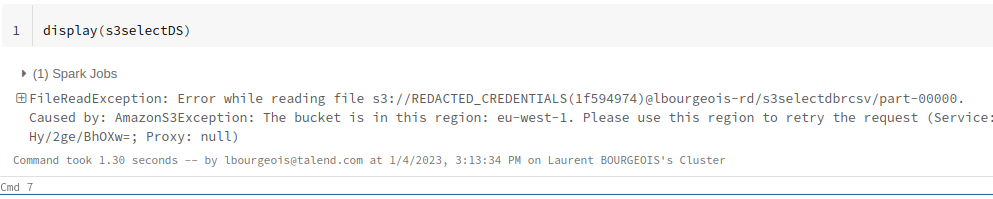
Caused by: com.amazonaws.services.s3.model.AmazonS3Exception: The bucket is in this region: eu-west-1. Please use this region to retry the request (Service: Amazon S3; Status Code: 301; Error Code: PermanentRedirect; Request ID: 1TTFZ54B0757A901; S3 Extended Request ID: TMqeVLFYG/b1mLVoLlSRqCMYuNbYj+cSSKneAde2/Lis7WSBvSuq98KsTcdc6SGvZHwET8GOnRs=; Proxy: null), S3 Extended Request ID: TMqeVLFYG/b1mLVoLlSRqCMYuNbYj+cSSKneAde2/Lis7WSBvSuq98KsTcdc6SGvZHwET8GOnRs=
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1862)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1415)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1384)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1154)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:811)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:779)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:753)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:713)
at com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:695)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:559)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:539)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5453)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5400)
at com.amazonaws.services.s3.AmazonS3Client.selectObjectContent(AmazonS3Client.java:3221)
at com.databricks.io.s3select.S3SelectDataSource$.readFileFromS3(S3SelectDataSource.scala:238)
at com.databricks.io.s3select.S3SelectDataSource$.readFile(S3SelectDataSource.scala:284)
at com.databricks.io.s3select.S3SelectFileFormat.$anonfun$buildReader$2(S3SelectFileFormat.scala:88)
at org.apache.spark.sql.execution.datasources.FileFormat$$anon$1.apply(FileFormat.scala:157)
at org.apache.spark.sql.execution.datasources.FileFormat$$anon$1.apply(FileFormat.scala:144)
at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:525)
... 37 moreI tried to set spark.hadoop.fs.s3a.bucket.<my-bucket>.endpoint to s3.eu-west-1.amazonaws.com in cluster config without success.
Any advice ?


8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 01:35 PM
Maybe these resources will help:
Access S3 buckets with URIs and AWS keys https://docs.databricks.com/external-data/amazon-s3.html#access-s3-buckets-with-uris-and-aws-keys
If you are using the unity catalog and S3 buckets are inside the same account you can register them as external locations https://docs.databricks.com/data-governance/unity-catalog/manage-external-locations-and-credentials....
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 03:13 AM
Thanks @Hubert Dudek for having a look.
I don't use unity catalog, I actually use 3.Encode keys in URI option for S3 Auth as described in https://docs.databricks.com/external-data/amazon-s3-select.html#s3-authentication
Strange thing is that if I change format to csv in DataFrameReader I don't face this issue (even without specifying any region or endpoint). What I wonder is :
- is there any limitation around region when using s3 select connector ?
- if know how to specify a different region to avoid this exception ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 03:23 AM
Maybe share your code as I haven't noticed s3select format and even don't know what is it 🙂
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 06:14 AM
Sure, I reproduced the issue on a notebook. Here is the code snippet to create a Dataset with s3select and csv formats :
val s3selectDS = spark.read.format("s3select").schema(mySchema)
.load("s3://"+accessKey+":"+secretKey+"@lbourgeois-rd/s3selectdbrcsv")
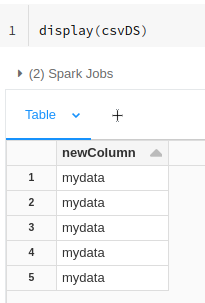
val csvDS = spark.read.format("csv").schema(mySchema)
.load("s3://"+accessKey+":"+secretKey+"@lbourgeois-rd/s3selectdbrcsv")As you can see only the format arg is different.
Displaying csvDS works fine


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2023 02:01 AM
You can try to set S3 Gateway so that it will be in the VPC network. that feature is for free https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints-s3.html
https://www.databricks.com/blog/2022/11/08/optimizing-aws-s3-access-databricks.html
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 10:25 AM
Hi @Hubert Dudek and @47kappal ,
Sorry for the delay. As suggested I'm trying to setup a gateway endpoint for s3 following https://docs.aws.amazon.com/vpc/latest/privatelink/vpc-endpoints-s3.html
I am a bit confused by
A gateway endpoint is available only in the Region where you created it. Be sure to create your gateway endpoint in the same Region as your S3 buckets.In my case the vpc used by the cluster (and in which the gateway will be created) is us-east-1 while s3 bucket is in eu-west-1 so above statement can't be respected (bucket and gateway won't be in same region)
I am also confused by the fact that iw works with format(csv) but not with format(s3select). I wonder about limitations with s3 select connector.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-23-2023 11:10 AM
It seems that you need to create vpc in another region and peer it with your main region https://aws.amazon.com/premiumsupport/knowledge-center/vpc-endpoints-cross-region-aws-services/
s3select is a completely different connector, optimized to take only part of the file from s3 bucket so it is different library
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-26-2023 12:31 AM
Hello,
I tried your suggestion by setting up the peering connection between the 2 VPC but issue remains the same.
The error message
The bucket is in this region: .... please use this region to retry the request
makes me think that the root cause is not at network level but at S3 Select Spark connector level which does not use correct regional s3 enpoint.
The connector does not seem to have such property : https://docs.databricks.com/external-data/amazon-s3-select.html doc
Then I tried to set following properties at Spark level as usually suggested in such situation without any effect :
spark.conf.set("fs.s3a.endpoint","s3.eu-west-1.amazonaws.com")
spark.conf.set("fs.s3n.endpoint","s3.eu-west-1.amazonaws.com")
spark.conf.set("fs.s3.endpoint","s3.eu-west-1.amazonaws.com")
It seems that the S3 Select connector does not forward this endpoint setting to the underlying AWS S3 SDK
Announcements





{kind=link}
{kind=link}
Related Content
- Databricks Apps - "App Not Available" error with locationId parameter missing in Data Engineering
- oreign Iceberg tables via HMS federation fail with browse_only_table on all compute — request Public in Data Engineering
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Administration & Architecture
- Can I connect Fabric Data Agent With Databricks Genie One as external connection in Data Governance
- VOID column inside STRUCT fails to cast to VARIANT in Data Engineering