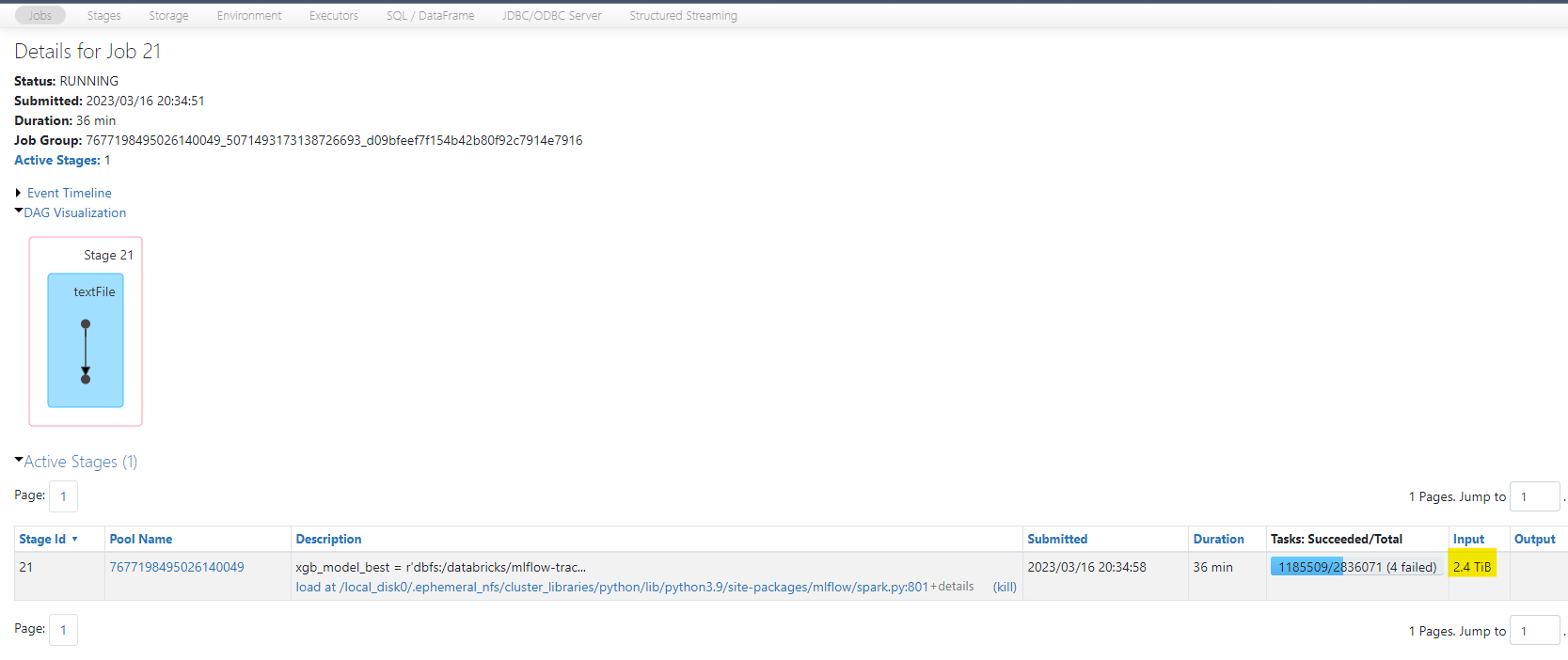
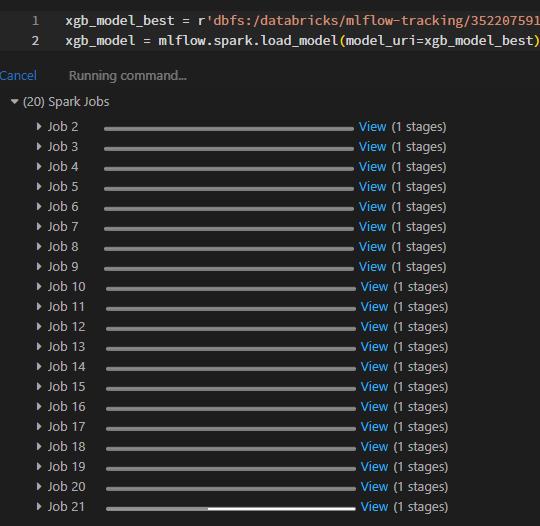
When loading an xgboost model from mlflow following the provided instructions in Databricks hosted MLflow the input sizes I am showing on the job are over 1 TB. Is anyone else using an xgboost.spark model and noticing the same behavior?
Below are some screenshots showing the input size. The job has been running over 15 minutes just to load the model from MLflow.










{kind=link}
{kind=link}
{kind=link}