Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Safe Update Strategy for Online Feature Store With...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Safe Update Strategy for Online Feature Store Without Endpoint Disruption
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-23-2025 03:45 AM
Hi Team,
We are implementing Databricks Online Feature Store using Lakebase architecture and have run into some constraints during development:
Requirements:
- Deploy an offline table as a synced online table and create a feature spec that queries from this online table.
- During development, schema changes occur frequently (columns renamed or removed).
- After schema changes, we need to redeploy the endpoint with the updated online table and feature spec.
Problem: When an endpoint is running and we delete/recreate the online table and feature spec (to reflect schema changes), the endpoint breaks. In some cases, it even becomes irrecoverable.
Constraints:
- Cannot create two online tables for the same offline table.
- Deleting and recreating binding resources (online table + feature spec) disrupts the endpoint.
- We need to keep a stable endpoint URL for consumers (cannot create multiple shadow endpoints).
Question: What is the recommended approach to safely update the online store and feature spec without causing downtime or breaking the endpoint? Is there a supported pattern for atomic updates or versioning in Databricks Feature Store?
Thanks for your guidance!
#lakehouse #databricksonlinefeaturestore #syncedtable #postgres #onlinefeaturestore


3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-23-2025 06:36 AM
Additional Context:
- The feature spec created from the synced table is served through an endpoint, and we need to keep the same endpoint URL for consumers.
- After schema changes, we currently recreate the synced table and feature spec with the same names before updating the endpoint.
- Even after updates, the endpoint sometimes breaks or becomes irrecoverable.
- We have steps in place to clean up the Postgres datastore during synced table deletions, so the issue is not with leftover data but with the binding between the endpoint and feature spec.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-24-2025 07:09 AM
The recommended way to safely update an online Databricks Feature Store without breaking the serving endpoint or causing downtime involves a version-controlled, atomic update pattern that preserves schema consistency and endpoint stability.
Key Issue
When an online feature table is deleted and recreated due to a schema change, the associated endpoint and feature spec lose binding references, rendering the endpoint unstable. Databricks currently does not support true in-place schema replacement for synced online tables — any schema change to the offline Delta source requires synchronization through a publish or merge update, not recreation.
Recommended Approach
1. Use Incremental Schema Evolution
Databricks Delta Tables support schema evolution, allowing columns to be added or updated without deleting the table. You can use:
python
fs.write_table(
name="catalog.schema.feature_table",
df=new_feature_df,
mode="merge" # merges updates safely
)
This approach updates the schema and data without breaking existing bindings between the offline and online tables.
2. Republish or Refresh Features Atomically
Instead of deleting the online table, use:
python
fe.publish_table(
source_table_name="catalog.schema.feature_table",
online_table_name="catalog.schema.online_table",
online_store=online_store,
mode="merge"
)
mode="merge" ensures the online table schema and data are updated incrementally while keeping its identity (and thus the endpoint bindings) intact. This prevents downtime and maintains endpoint stability.
3. Use Lakeflow Jobs for Continuous Sync
If schema changes or feature updates are frequent, schedule Lakeflow Jobs to regularly call publish_table. This approach makes the feature update process continuous and fault-tolerant without manual deletion or recreation.
4. Maintain Versioned Feature Specs
Databricks recommends maintaining versioned feature specifications (for example, feature_spec_v1, feature_spec_v2), while keeping a constant endpoint mapping. During deployment, update the endpoint’s configuration reference to the new spec version atomically. The endpoint name and URL remain unchanged.
Practical Schema Evolution Workflow
-
Update offline Delta table schema (enable CDF if not already set).
-
Write or merge new features using schema evolution.
-
Republish the updated offline table to the online store using
mode="merge". -
Update the feature spec version — do not delete the online table.
-
Redeploy endpoint referencing the new feature spec (same URL).
Summary Table
| Problem | Corrective Practice |
|---|---|
| Schema change causes endpoint breakage | Use Delta schema evolution with mode="merge" |
| Need uninterrupted endpoint (stable URL) | Reuse endpoint, only version feature spec |
| Frequent schema changes | Use Lakeflow jobs for automated sync |
| Avoid dual tables for one offline source | Use incremental publish_table to preserve online identity |
This workflow ensures atomic updates, zero downtime, and endpoint continuity while enabling schema flexibility under Databricks’ Online Feature Store using Lakebase architecture.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-27-2025 01:42 AM
Hi Mark,
Thanks for your response. I followed the steps you suggested:
- Created the table and set primary key + time series key constraints.
- Enabled Change Data Feed.
- Created the feature table and deployed the online endpoint — this worked fine.
- Removed some columns from the offline table and updated it using:
spark_df.write.mode("overwrite").option("overwriteSchema", "true").saveAsTable(f"{table_name}") - Updated the feature table using:
fe.write_table(name=feature_store_name, df=df, mode="merge") - Tried re-publishing to the online store using:
fe.publish_table(source_table_name=feature_store_list, online_table_name="catlog_dev.abcd.fs_table_online", online_store=pg_store, mode="merge")
— this step failed.
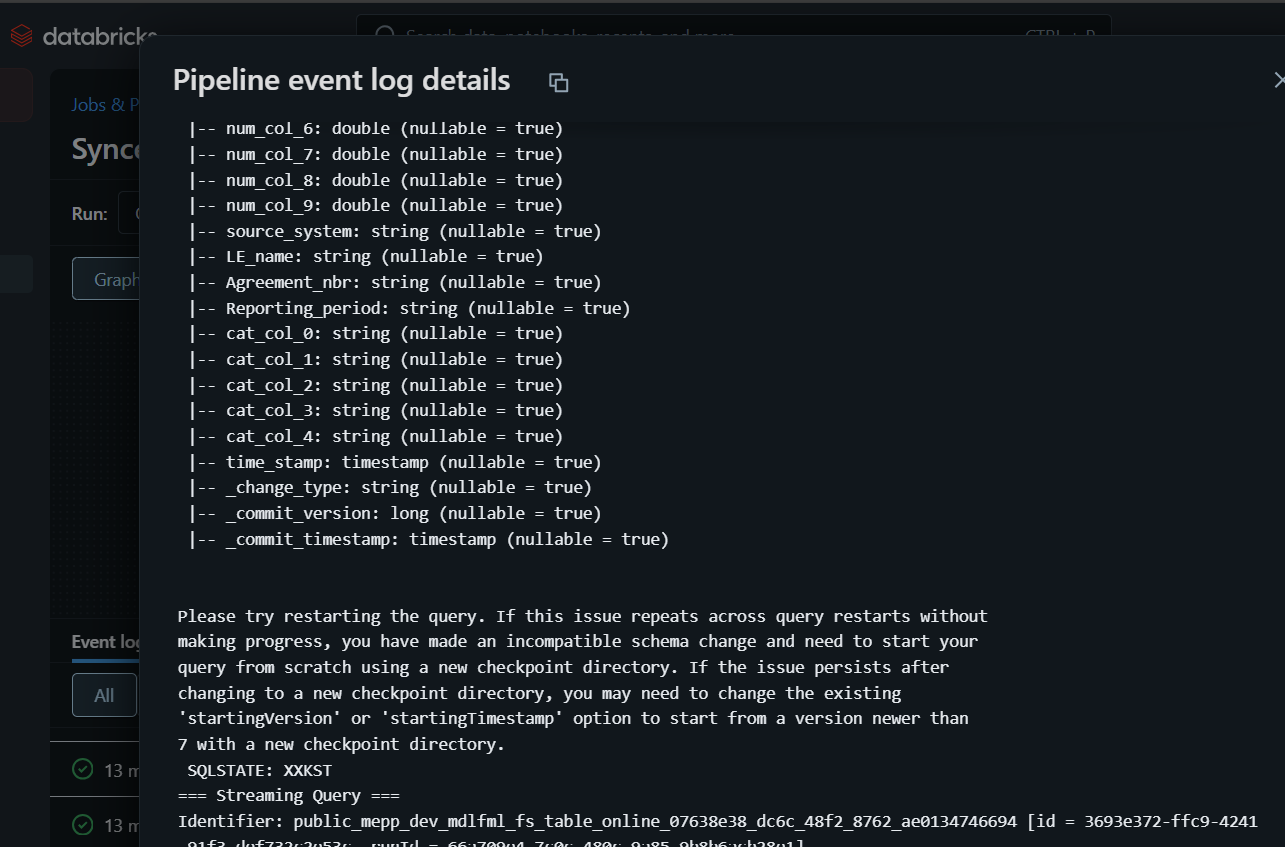
A LakeFlow pipeline was triggered and threw the following error:
org.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] ... [DELTA_SCHEMA_CHANGED_WITH_STARTING_OPTIONS] Detected schema change in version 7
It seems the schema change isn’t being handled during re-publication. I’ve attached the full error message. Let me know if you need more details or logs.
Announcements





{kind=link}