Recommend checking out Amperity. Listed on Databricks marketplace, support delta sharing and unity catalog. Patented AI approach to ID resolution https://docs.amperity.com/stitch.html
I've signed up for the module for certification on Large Language Models: Application through Production.Follow the Github instructions and install the notebooks provided.Unfortunately none of the workbooks are working due to the- Badly setup file pa...
No further instructions on the Read-me here: https://github.com/databricks-academy/large-language-models/tree/publishedFollowed all the setup steps, but the file paths in /include are not working fine.Why does not Databricks provide the direct links ...
It keeps on failing with this error:HTTPError: 503 Server Error: Service Unavailable for url: https://community.cloud.databricks.com/api/2.0/feature-store/feature-tables/search?max_results=200 Response from server: { 'error_code': 'TEMPORARILY_UNAVAI...
Hi All,Can we customize the mail subject and body that we receive from Azure Databricks workflow upon failure jobs? Kindly help me, if we can do so.Thanks,Moshe
I have three workspaces and the alerts sent by the jobs running are not referencing the workspace for example. So if I run the job to dev environemnt I get an alert like if the job has been executed from the prod. This si a huge issue for our admins....
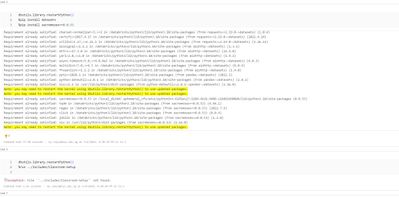
Running a python function in the notebook, i am getting the following InvalidConfigurationError: You haven't configured the CLI yet! Please configure by entering `/databricks/python_shell/scripts/db_ipykernel_launcher.py configure`When i try to run...
Facing the same issuefor me the error comes up when mlflow.get_experiment_by_name is called.I am running a custom docker image built on databricksruntime/standard:13.3-LTScustom image so my packages are installed.
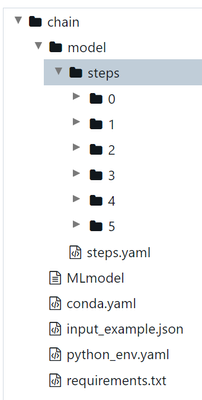
I am trying to find a way to locally download the model artifacts that build a chatbot chain registered with MLflow in Databricks, so that I can preserve the whole structure (chain -> model -> steps -> yaml & pkl files).There is a mention in a contri...
OK, eventually I found a solution. I write it below, whether somebody will need it. Basically, if in the download_artifacts method the local directory is an existing and accessible one in the DBFS, the process will work as expected.import os
# Con...
Hi,We are facing an mlflow.exceptions.MlflowException when mlflow is called from stream,when we load the model outside the stream, its loaded fine, while when we load it from within stream it fails with exception. to emphasize that it was working til...
We have deployed Dolly (https://huggingface.co/databricks/dolly-v2-3b) as a REST API endpoint on our infrastructure. The notebook we used to do this is included in the text below my question.The Databricks infra used had the following config - (13.2...
I had a similar problem when I used HuggingFacePipeline(pipeline=generate_text) with langchain. It worked to me when I tried to use HuggingFaceHub instead. I used the same dolly-3b model.
I´m facing this exception after use mlflow.langchain.log_model and test the logged model using the following commandprint(loaded_model.predict([{"query": "how does the performance of llama 2 compare to other local LLMs?"}]))tasks failed. Errors: {0: ...
I verified all steps @Kaniz and the objects and structure were looking good. As far as I understood on tests. Langchain Rag features such as RetrievalQA.from_chain_type does not work well with llm = HuggingFacePipeline instantiation steps. The probl...
Trying to start an ML experiment on data in an extant metastore within a catalogue (SQL querys run fine on the database). I can start an ML cluster, then attempt to start an AutoML expirement but I get stuck selecting training data - there are no da...
Hey there! Thanks a bunch for being part of our awesome community! We love having you around and appreciate all your questions. Take a moment to check out the responses – you'll find some great info. Your input is valuable, so pick the best solution...
I am trying to finetune llama2_lora model using the xTuring library, while facing this error. (batch size is 1). I am working on a cluster having 1 Worker (28 GB Memory, 4 Cores) and 1 Driver (110 GB Memory, 16 Cores). I am facing this error: OutOfMe...
Hi @hv129,
The error message you’re encountering indicates that your CUDA memory is running out while trying to allocate additional memory for your model.
Let’s break down the details:
Total Capacity: The 15.57 GiB mentioned in the error message ...
I'm trying to upgrade Tensorflow version from 2.8 to 2.13 on Databricks notebook that is attached to a cluster with Databricks Runtime 10.4. How can I upgrade cuDNN from 8.0 to at least 8.6 to be compatible with the Tensorflow new version?
Hi @Kaniz , Thanks for your response. When I run '!conda list cudnn' on databricks notebook, I get the following error: '/bin/bash: conda: command not found'
I upgraded Tensorflow on Databricks notebook using %pip command. Now when running the training job, I get this error: "DNN library initialization failed."
Hi @Amoozegar,
Check TensorFlow Version: Ensure that the TensorFlow version you upgraded to is compatible with your existing code and dependencies. Sometimes, upgrading TensorFlow can lead to compatibility issues. You might want to verify if the sp...
Hello! I am fairly new to Databricks. I'm trying to do a proof of concept with AutoML in Databricks at my organization, and the dataset I am using is a project management dataset. Here's a sample: project_idmarketgeneral_contractorproject_typepermit_...
Hi @ProtonMix, Let’s break down your requirements and tackle them step by step.
Reducing Completion Date Period:
To understand how different factors impact the completion date, you can use regression analysis. Specifically, you want to predict th...