Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Training Job Failure (Driver Error)
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Training Job Failure (Driver Error)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-30-2024 05:50 PM
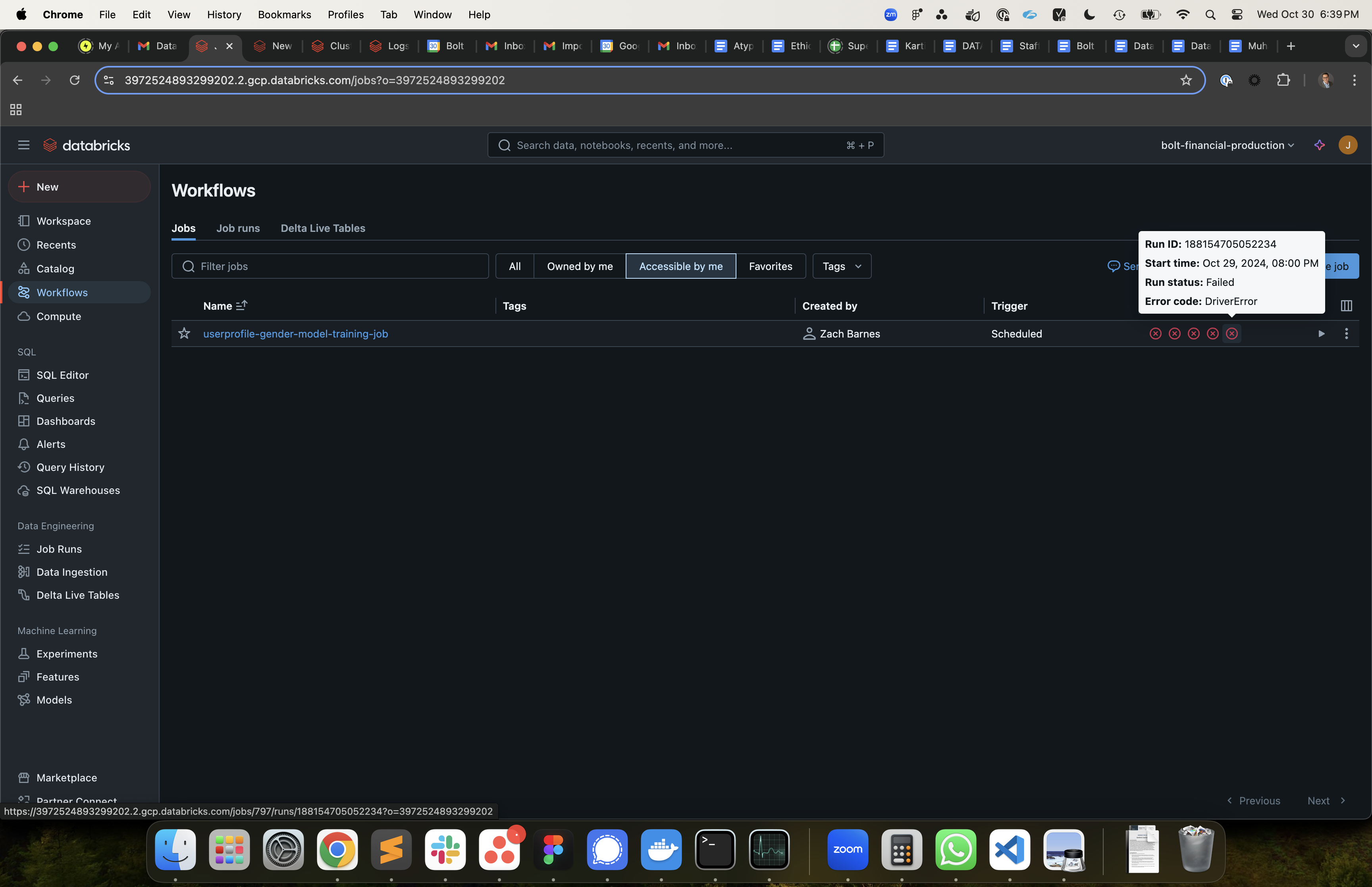
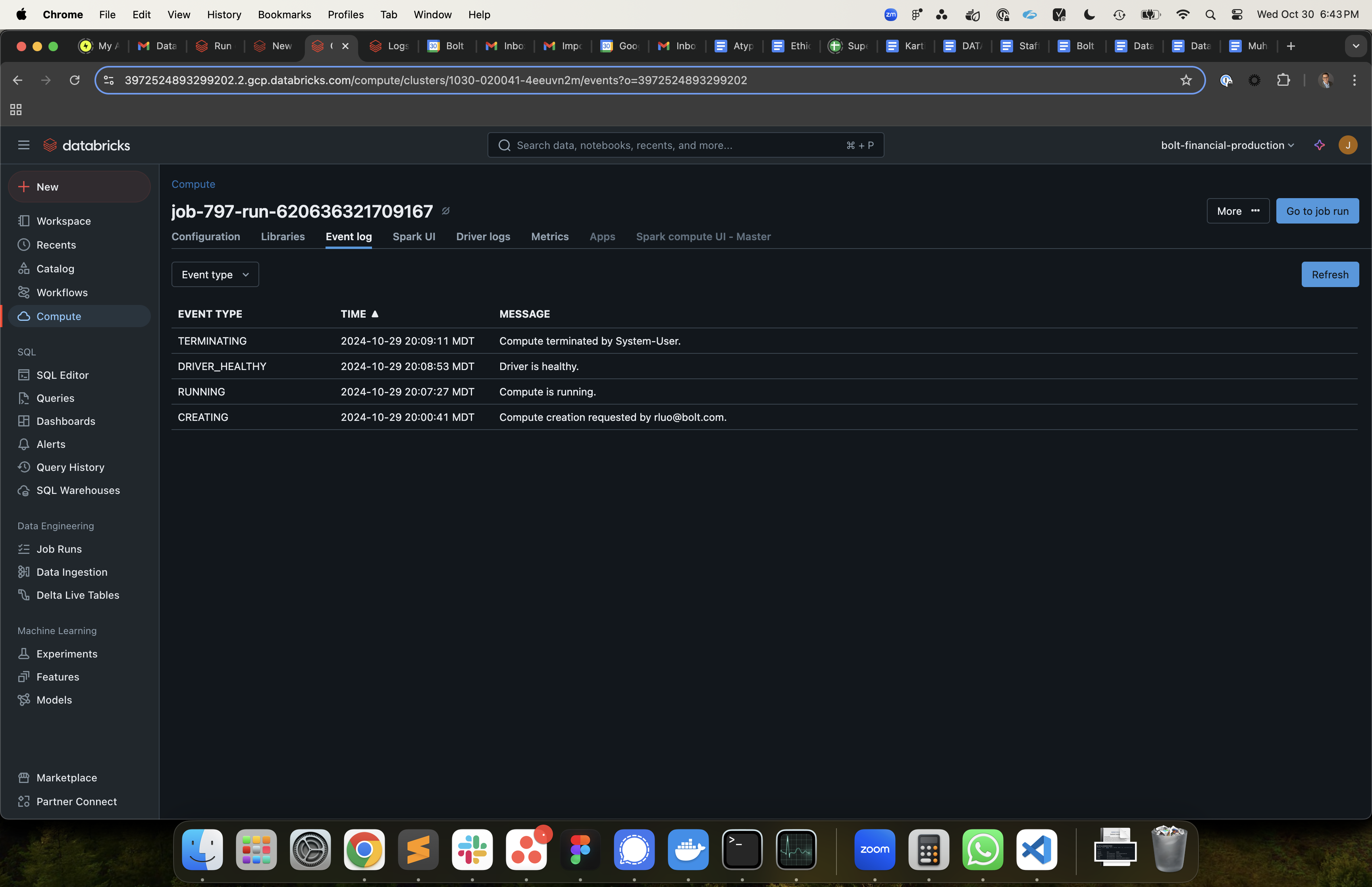
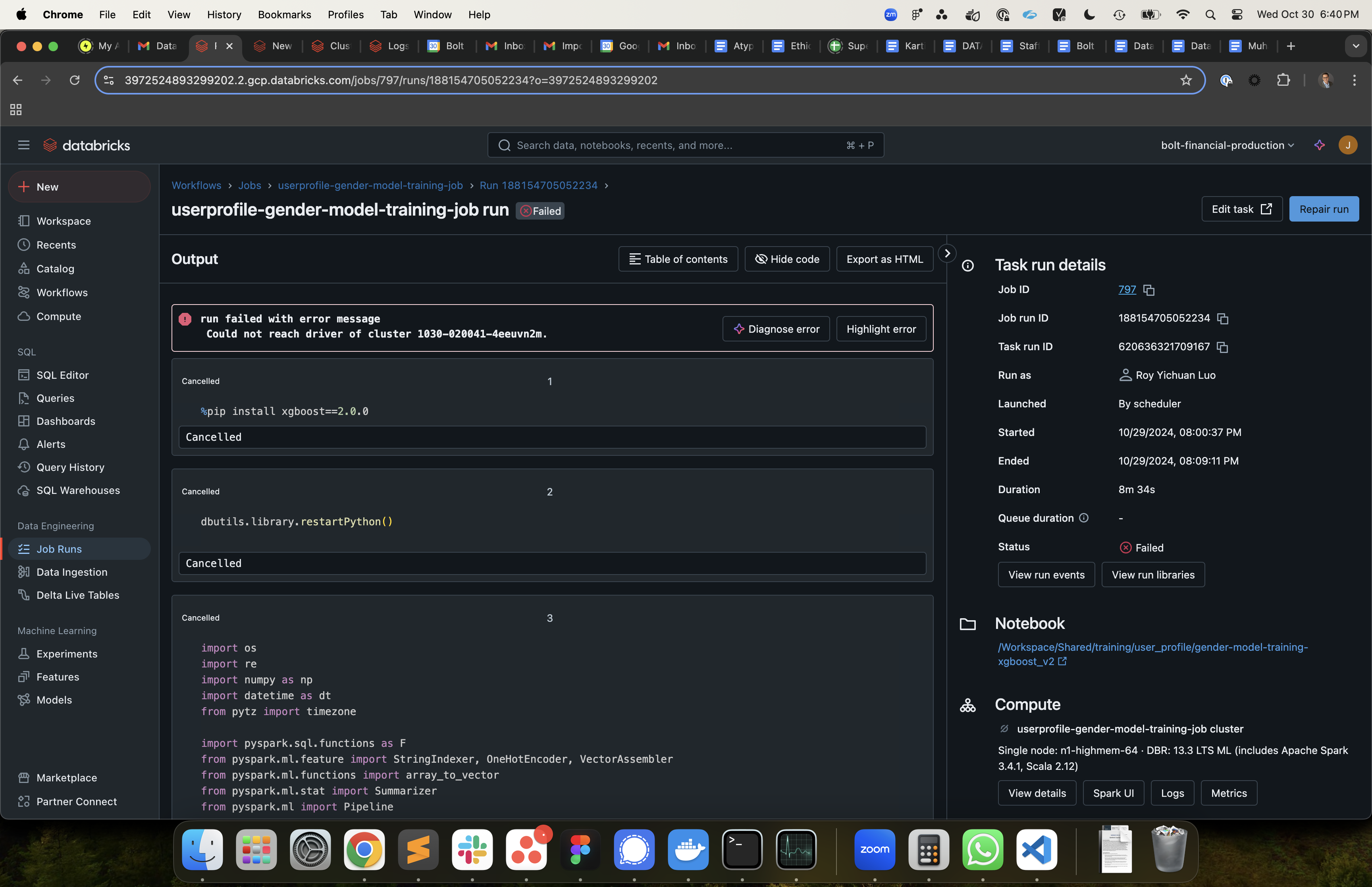
We have a new model training job that was running fine for a few days and then started failing. I have attached images for more details.
I am wondering if 'can't reach driver cluster' is a red herring. It says the driver is healthy right before execution
When I look into the logs, it looks like a library problem potentially with numpy.
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
Traceback (most recent call last):
from pandas._libs.interval import Interval
File "pandas/_libs/interval.pyx", line 1, in init pandas._libs.interval
Has anyone seen this before and have any ideas or suggestions?


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-30-2024 05:51 PM
Sorry here is the full stack trace and one additional screen shot:
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
Traceback (most recent call last):
File "/databricks/python_shell/scripts/db_ipykernel_launcher.py", line 37, in <module>
from dbruntime.PipMagicOverrides import PipMagicOverrides
File "/databricks/python_shell/dbruntime/PipMagicOverrides.py", line 8, in <module>
from pyspark.sql.connect.session import SparkSession as RemoteSparkSession
File "/databricks/spark/python/pyspark/sql/connect/session.py", line 19, in <module>
check_dependencies(__name__)
File "/databricks/spark/python/pyspark/sql/connect/utils.py", line 33, in check_dependencies
require_minimum_pandas_version()
File "/databricks/spark/python/pyspark/sql/pandas/utils.py", line 27, in require_minimum_pandas_version
import pandas
File "/databricks/python/lib/python3.10/site-packages/pandas/__init__.py", line 22, in <module>
from pandas.compat import is_numpy_dev as _is_numpy_dev
File "/databricks/python/lib/python3.10/site-packages/pandas/compat/__init__.py", line 15, in <module>
from pandas.compat.numpy import (
File "/databricks/python/lib/python3.10/site-packages/pandas/compat/numpy/__init__.py", line 4, in <module>
from pandas.util.version import Version
File "/databricks/python/lib/python3.10/site-packages/pandas/util/__init__.py", line 1, in <module>
from pandas.util._decorators import ( # noqa:F401
File "/databricks/python/lib/python3.10/site-packages/pandas/util/_decorators.py", line 14, in <module>
from pandas._libs.properties import cache_readonly # noqa:F401
File "/databricks/python/lib/python3.10/site-packages/pandas/_libs/__init__.py", line 13, in <module>
from pandas._libs.interval import Interval
File "pandas/_libs/interval.pyx", line 1, in init pandas._libs.interval
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2024 11:34 AM
@jonathanhodges By any chance did you manage to solve this issue?
We are also having same issue
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2024 01:14 PM
In our case, we needed to correct our dependent libraries. We had an incorrect path referenced.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-30-2024 06:27 AM
Same in my case as well. It was related to Numpy version 2. Reducing the version fixed the issue. Error messages from Databricks were pretty confusing.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Init Script to Install ODBC Driver Causes Cluster Crash (JVM Thread Dump) in Administration & Architecture
- Connecting DBeaver to Databricks Lakebase — Setup & Troubleshooting in Data Engineering
- Cluster crashes occasionally but not all of the time in Data Engineering
- Can’t save results to target table – out-of-memory error in Data Engineering
- Databricks Nested Json Flattening in Data Engineering