Engage in discussions on data warehousing, analytics, and BI solutions within the Databricks Community. Share insights, tips, and best practices for leveraging data for informed decision-making.
Here's your Data + AI Summit 2024 - Warehousing & Analytics recap as you use intelligent data warehousing to improve performance and increase your organization’s productivity with analytics, dashboards and insights.
Keynote: Data Warehouse presente...
Hi,I want to remove duplicate rows from my managed delta table in my unity catalog. I use a query on a SQL warehouse similar to this: WITH cte AS (
SELECT
id, ROW_NUMBER() OVER (PARTITION BY id,##,##,## ORDER BY ts) AS row_num
FROM
catalog.sch...
I have first tried to use _metadata.row_index to delete the correct rows but also this resulted in an error. My solution was now to use spark and overwrite the table.table_name = "catalog.schema.table"
df = spark.read.table(table_name)
count_df = df....
Recently, it seems that there has been an intermittent issue where the output of a notebook cell doesn't display, even though the code within the cell executes successfully. For instance, there are times when simply printing a dataframe yields no out...
select {{user_defined_variable}} as my_var, count(*) as cntfrom my_tablewhere {{user_defined_variable}} = {{value}} for user_defined_variable, I use query based dropdown list to get a column_name I'd like ...
Hey,I've managed to add my SQL Warehouse as a data source in Pycharm using the JDBC driver and can query the warehouse from an SQL console within Pycharm. This is great, however, what I'm struggling with is getting the catalogs and schemas to show in...
You need to explicitly tell your JetBrains tool to introspect the database using JDBC metadata.I think the reason it (sometimes) works in Datagrip but not PyCharm, IntelliJ, etc is because the default settings can be different across tools and even v...
I am currently trying to write a dataframe to s3 likedf.write.partitionBy("col1","col2").mode("overwrite").format("json").save("s3a://my_bucket/")The path becomes `s3a://my_bucket/col1=abc/col2=opq/`But I want to path to be `s3a://my_bucket/abc/opq/`...
Hi @Jennifer ,
The default behavior of the .partitionBy() function in Spark is to create a directory structure with partition column names. This is similar to Hive's partitioning scheme and is done for optimization purposes. Hence, you cannot directl...
I am in the process of connecting Looker to one of my Databricks databases. To reduce startup time on my SQL warehouse cluster I would like to change the type from "Pro" to "Serverless". I cannot find a way to do that and "Serverless" is not an optio...
Hi,I am trying to connect to databricks from tableau server and facing this error OAuth error response, generally means someone clicked cancel: access_denied (errorCode=180002)I have added it in "app connections" under account console. Any pointers w...
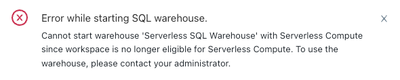
Hello, We have a workspace in West Europe, which we were using with multiple Serverless SQL Warehouses. Recently it suddenly stopped working and presented with the following error when trying to restart an existing serverless warehouse. I am an adm...
Raised a ticket with Azure support but they haven't been very helpful so far to be honest. No uncleared bills and serverless seems disabled for all workspaces in the subscription. Someone mentioned accepting terms and conditions for serverless comp...
Hi All!Has anyone encountered a situation where we need to setup data access for Unity Catalog tables for read access such as external data marts, dashboard tools and etc.We are currently using Databricks to serve data to people in our organisation t...
I see there’s a “test” capability within a DAB, but I’d like to know more about how this should/could be used. Does anyone know of any documentation or examples which might provide insights into its intended use?
Hi @EWhitley
You can check and validate whether the Asset Bundle configuration is valid or not by using the below command
databricks bundle validate
If a JSON representation of the bundle configuration is returned, then the validation succeed...
While setting up metastore in GCP Databricks, I added the bucket name and then service account permissons as well. Still my catalog dont have base root location. This deters me from creating table in my catalog. Root storage credential for metastore...
Hi @manish05485 , Good Day!
Error:Root storage credential for metastore XXXXXX does not exist. Please contact your Databricks representative or consider updating the metastore with a valid storage
Error states that the data access configuration for ...
Hi,I cannot see the query execution time in the response to the "api/2.0/sql/history/queries" request.Basically, I get only the following fields:{"next_page_token":...,"has_next_page":...,"res":[ { "query_id":..., "status":.., "query_tex...
I am attempting to recreate a legacy dashboard in Lakeview. The bar graph in no way resembles what I created in the SQL visualization editor. Lakeview has far fewer formatting options for one thing.How do I recreate the graph so that it resembles the...
Hi Team,I have a delta table in databricks which contains a encrypted column. For encrypting I am using databricks "aes_encrypt" function. For reference: https://docs.databricks.com/en/sql/language-manual/functions/aes_encrypt.html#aes_encrypt-functi...
you can create two cloumns , and display base on userDisplay different columns in Power BI based on logged in user | Paige Liu’s Posts (liupeirong.github.io)