Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Older Spark Version loaded into the spark notebook
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Older Spark Version loaded into the spark notebook
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 08:47 AM
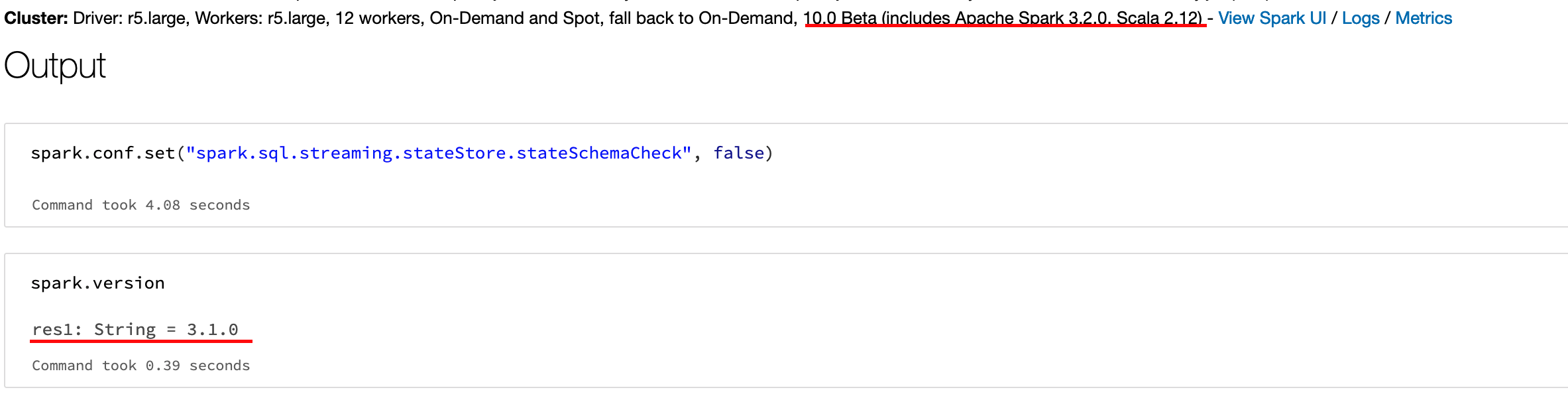
I have databricks runtime for a job set to latest 10.0 Beta (includes Apache Spark 3.2.0, Scala 2.12) .
In the notebook when I check for the spark version, I see version 3.1.0 instead of version 3.2.0
I need the Spark version 3.2 to process workloads as that version has the fix for https://github.com/apache/spark/pull/32788
Screenshot with the cluster configuration and the older spark version in notebook attached.

Labels:
10 REPLIES 10
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 09:11 AM
If you use pool please check what preloaded version is set also in pool.
If it is not that problem I can not help as I even don't see yet 10.0 (and after all it is Beta)
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 09:27 AM
I got the same thing when I tested it out. I guess that's why it's Beta, should get fixed soon I imagine.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 09:54 AM
I am not using the pool. Thanks for the update though. Hopefully this gets fixed soon.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 11:17 AM
This is due to some legalese related to Open-Source Spark and Databricks' Spark. Since Open-Source Spark has not released v3.2 yet, we are not allowed to call the one on DBR 10 v3.2 yet. It may have that patch already in there though.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 11:45 AM
Thanks for the update @Dan Zafar .
Just ran the job again and still seeing spark version 3.1.0. Should I be using spark32 (or something similar) when invoking spark session for me to pick up the correct spark version?
Any ETA on the spark 3.2 version availability will be great.
Thanks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 12:11 PM
It should have all the features you need. Check it out. Legally we can't call it Spark 3.2 yet.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 12:25 PM
I do not think it is loading Spark 3.2. I am still seeing the issue with writeUTF which has been fixed in Spark 3.2 -> https://github.com/apache/spark/pull/32788
Caused by: java.io.UTFDataFormatException: encoded string too long: 97548 bytes
at java.io.DataOutputStream.writeUTF(DataOutputStream.java:364)
at java.io.DataOutputStream.writeUTF(DataOutputStream.java:323)Anyways, I will wait for the databricks runtime to correctly reflect the correct version.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-20-2021 02:44 PM
Yes- this version probably has the Databricks internal features slated for Spark 3.2, but the features/patches contributed by the open-source community may still be coming. Sorry this isn't available yet. I'm sure it will be very soon. Happy coding!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2021 05:32 AM
I just noticed that (on Azure anyway) 10.0 is NOT in beta anymore.
So 'very soon' was indeed very soon.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2021 09:47 AM
hi @Dhaivat Upadhyay ,
Good news, DBR 10 was release yesterday October 20th. You can find more details in the release notes website
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- SqlContext in DBR 14.3 in Data Engineering
- AssertionError Failed to create the catalog in Machine Learning
- DLT Autoloader stuck in reading Avro files from Azure blob storage in Data Engineering
- Can't run Delta Live Tables pipeline while using Mosaic in Data Engineering
- DBR CLI v0.216.0 failed to pass bundle variable for notebook task in Machine Learning