Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks
- Data Engineering
- Databricks Issue:- assertion failed: Invalid shuff...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 12:41 AM
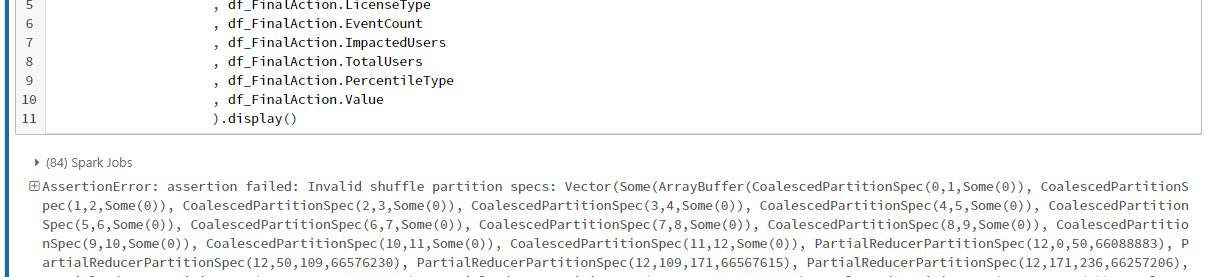
I hv a complex script which consuming more then 100GB data and have some aggregation on it and in the end I am simply try simply write/display data from Data frame. Then i am getting issue (assertion failed: Invalid shuffle partition specs: ).
Pls help me here, if any one have some idea.

Labels:
1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2022 07:54 AM
Thanks Dudek, Finally I found the query where that have issue. As you suggested I debug step by step and run each every cell. And add the (spark.conf.set("spark.sql.shuffle.partitions",100)) at that cell. Its resolved 😀
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 03:42 AM
It is hard to help in that case without seeing the whole code.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 04:02 AM
Added ".py" file in attachment, Pls have a look.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 06:10 AM
Please use
display(df_FinalAction)Spark is lazy evaluated but "display" not, so you can debug by displaying each dataframe at the end of each cell.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2022 07:54 AM
Thanks Dudek, Finally I found the query where that have issue. As you suggested I debug step by step and run each every cell. And add the (spark.conf.set("spark.sql.shuffle.partitions",100)) at that cell. Its resolved 😀
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2022 04:10 AM
Thanks, it is excellent. If you want you can select my answer as the best one 🙂
Announcements





{kind=link}
Welcome to Databricks Community: Lets learn, network and celebrate together
Join our fast-growing data practitioner and expert community of 80K+ members, ready to discover, help and collaborate together while making meaningful connections.
Click here to register and join today!
Engage in exciting technical discussions, join a group with your peers and meet our Featured Members.
Related Content
- exposing RAW files using read_files based views, partition discovery and skipping, performance issue in Warehousing & Analytics
- What is the bestway to handle huge gzipped file dropped to S3 ? in Data Engineering
- Pyspark Dataframes orderby only orders within partition when having multiple worker in Data Engineering
- How to do perform deep clone for data migration from one Datalake to another? in Data Engineering
- Error when accessing rdd of DataFrame in Machine Learning