Cluster libraries are supported from version 15.0 - Databricks Runtime 15.0 | Databricks on AWS.How can I specify requirements.txt file path in the libraries in a job cluster in my workflow? Can I use relative path? Is it relative from the root of th...
Hi,Are there any plans to build native slack integration? I'm envisioning a one-time connector to Slack that would automatically populate all channels and users to select to use for example when configuring an alert notification. It is does not seem ...
Have been running into an issue when running a pymc-marketing model in a Databricks notebook. The cell that fits the model gets hung up and the progress bar stops moving, however the code completes and dumps all needed output into a folder. After the...
Hello everyone,There isn't an official document outlining the step-by-step procedure for enabling Unity Catalog in Azure Databricks.If anyone has created documentation or knows the process, please share it here.Thank you in advance.
Hello,I am running a job that depends on the information provided in column storage_sub_directory in system.information_schema.tables .... and it worked until 1-2 weeks ago.Now I discovered in the doc that this column is deprecated and always null , ...
In a pyspark application, I am using set of python libraries. In order to handle python dependencies while running pyspark application, I am using the approach provided by spark : Create archive file of Python virtual environment using required set o...
Hi,
I have not tried it but based on the doc you have to go by this approach. ./environment/bin/pythonmust be replaced with the correct path.
import os
from pyspark.sql import SparkSession
os.environ['PYSPARK_PYTHON'] = "./environment/bin/python"
sp...
I am trying to reading json from aws s3 using with open in databricks notebook using shared cluster.Error message:No such file or directory:'/dbfs/mnt/datalake/input_json_schema.json'In single instance cluster the above error is not found.
Hi @Nagarathna ,
I just tried it on a shared cluster and did not face any issue. What is the exact error that you are facing? Complete stacktrace might help. Just to confirm are you accessing the "/dbfs/mnt/datalake/input.json" from the same workspac...
Hello:)as part of deploying an app that previously ran directly on emr to databricks, we are running experiments using LTS 9.1, and getting the following error: PythonException: An exception was thrown from a UDF: 'pyspark.serializers.SerializationEr...
Hi @liormayn ,
Are you still facing the issue? This was faced in mid March and issue was fixed. It can happen for some pip install when the libraries are in Workspace. But if you are still facing the issue, I would suggest you to create a support ti...
Hi All,we are executing databricks notebook activity inside the child pipeline thru ADF. we are getting child pipeline name in job name while executing databricks job. Is it possible to get master pipeline name as job name or customize job name thr...
I think we should raise a Request/Product Feedback.
Not sure if it would be Databricks that would own it or Microsoft but you may submit feedback for Databricks here - https://docs.databricks.com/en/resources/ideas.html
I have encountered a technical issue on Databricks.While executing commands both in Spark and SQL within the Databricks environment, I’ve run into permission-related errors from selecting files from DBFS. "org.apache.spark.SparkSecurityException: [IN...
Hi @MOUNIKASIMHADRI ,
Workspace admins get ANY FILE granted by default. They can explicitly grant it to non-admin users.
Hence as suggested in the kb,
GRANT SELECT ON ANY FILE TO `<user@domain-name>`
How do I impersonate a user? I can't find any documentation that explains how to do this or even hint that it's possible.Use case: I perform administrative tasks like assign grants and roles to catalogs, schemas, and tables for the benefit of busines...
Hidbx_687_3__1b3Q,
Actually, I have seen impersonation, is this something that you are looking for? https://docs.gcp.databricks.com/en/dev-tools/google-id-auth.html#step-5-impersonate-the-google-cloud-service-account
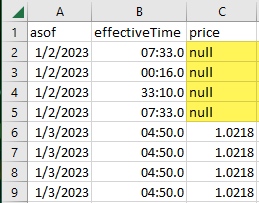
After running a sql script, when downloading the results to a csv file, the file includes a null string for blank cells (see screenshot). Is ther a setting I can change to simply get empty cells instead?
Hi AlexG,
I tested with the table content containing null and with empty data and it works as expected in the download option too.
Here is an eg:
CREATE TABLE my_table_null_test1 (
id INT,
name STRING
);
INSERT INTO my_table_null_test1 (id, name)...
Hi,I am getting FilereadException Error while reading JSON file using REST API Connector.It comes when data is huge in Json File and it's not able to handle more than 1 Lac records.Error details:org.apache.spark.SparkException: Job aborted due to sta...
Hello @DataBricks_Use1 ,
It would great if you could add the entire stack trace, as Jose mentioned. But there should be a "Caused by:" section below which would give you an idea of what's the reason for this failure and then you can work on that.
fo...
We have to generate over 70 intermediate tables. Should we use temporary tables or dataframes, or should we create delta tables and truncate and reload? Having too many temporary tables could lead to memory problems. In this situation, what is the mo...
Hi Phani1,
It would be a use case specific answer, so if it is possible I would suggest to work with the Solution Architect on this or share some more insights for a better guidance.
When I say that, I just would want to understand would we really ne...