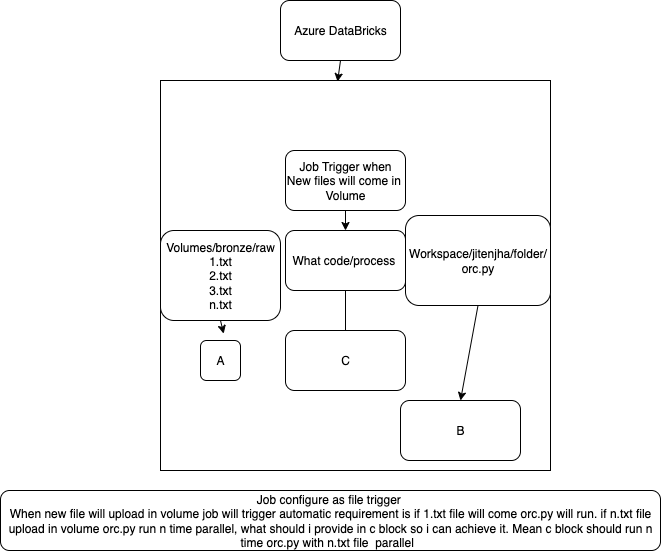
Hello @jitenjha11 : You can do it same manner they way it has highlighted by @MujtabaNoori but you have to call the process process twice.
Sharing the sample reference code below :
Iterating through the files in each directory.
for directory in directories:
# Read files using Autoloader
df = spark.readStream.format("cloudFiles") \
.option("cloudFiles.format", "csv") \
.load(directory)
# # Process the data (e.g., write to Delta table)
df.writeStream.format("delta") \
.option("checkpointLocation", f"<<Location>>") \
.start(f"/mnt/delta/<<location>>")
2nd Process
directories = ["/mnt/data/src1", "/mnt/data/src2"]
for directory in directories:
# Call external Python script with arguments
subprocess.run(["python", "process_data.py", directory])
I would request you to use the workflow which provide you the flexibility to run the process in for each loop and when new files arrived you pass the new file name as parameter and call the second notebook.
Please go through the below link this might help.
For Each In Databricks Workflows. One For Each, Each For All! | by René Luijk | Medium
BR







{kind=link}