- 560 Views
- 1 replies
- 3 kudos
Databricks Bundle Inspector: A VS Code extension for local bundle review
Hi all,I have been working with Databricks Asset Bundles (now Declarative Automation Bundles) and kept running into the same friction point: there is no easy way to visually inspect a bundle locally before you deploy.Of course, you can read the YAML,...
- 560 Views
- 1 replies
- 3 kudos
- 3 kudos
Hi @eniwoke !Glad to see that ! I will try it for sure If you need any contribution from my side please let me know !
- 3 kudos
- 486 Views
- 0 replies
- 1 kudos
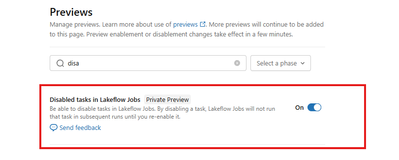
Finally! Databricks lets you disable tasks without hacks
For years, there was no simple way to disable a single task in a Databricks workflow. Let that sink in If you wanted to skip a task, you had to get creative - Add custom flags - Wrap logic in if/else blocks - Or build your own workaround just to not...
- 486 Views
- 0 replies
- 1 kudos
- 11077 Views
- 7 replies
- 13 kudos
Attribute-Based Access Control (ABAC) in Databricks Unity Catalog
What Is ABAC and Why Does It Matter?Attribute-Based Access Control (ABAC) is a data governance model now available in Databricks, designed to offer fine-grained, dynamic, and scalable access control for data, AI assets, and files managed through Data...




- 11077 Views
- 7 replies
- 13 kudos
- 13 kudos
I wanted to check if ABAC (Attribute-Based Access Control) policies can be applied to metric views in Databricks.I have successfully applied ABAC policies on a fact table, and they are working as expected. However, when I query a metric view that use...
- 13 kudos
- 672 Views
- 0 replies
- 1 kudos
DataHacks 2026: University Alliance in Action at UCSD
DataHacks 2026: University Alliance in Action at UCSD How a single weekend of hands on exposure creates the next generation of Databricks advocates Workshop Lead: Anjana Sriram Why University Alliances Matters in the Field Early in my career, the ...




- 672 Views
- 0 replies
- 1 kudos
- 1778 Views
- 0 replies
- 1 kudos
Databricks Metric Views - Power BI - BI compatibility mode Removal
BI compatibility mode allows us to query Unity Catalog Metric Views from external BI tools. It allows Databricks to rewrite queries generated by tools like Power BI, ensuring complex metric view logic is executed correctly while appearing as standard...
- 1778 Views
- 0 replies
- 1 kudos
- 3167 Views
- 3 replies
- 2 kudos
Unity Catalog-only workspace for new Azure Databricks deployments
Big shift coming for Azure Databricks usersStarting 30 September 2026, all new Azure Databricks workspaces will be Unity Catalog only.- No DBFS root.- No Hive Metastore.- No legacy runtimes below 13.3 LTS.- No “old way” of doing things.Disabling DBFS...

- 3167 Views
- 3 replies
- 2 kudos
- 2 kudos
Hi guys,There was an email message sent by Azure Databricks with this information. So no direct link, just information sent by Databricks to users.
- 2 kudos
- 485 Views
- 0 replies
- 1 kudos
How we solved the "18-Hour Running Job" problem with Data-Driven Timeouts
Hi everyone,I recently dealt with a frustrating scenario: a Databricks job that usually takes minutes ran for 18 hours without failing, quietly consuming compute and blocking downstream pipelines.The driver hadn't crashed, and the job hadn't failed—i...
- 485 Views
- 0 replies
- 1 kudos
- 847 Views
- 0 replies
- 3 kudos
Lakeflow Spark Declarative Pipelines now decouples pipeline and tables lifecycle
Ever deleted a pipeline… and accidentally wiped out the data with it? Databricks just introduced a beta feature that lets you decouple pipelines from the tables they manage.Lakeflow Spark Declarative Pipelines were desinged with data-as-code approach...

- 847 Views
- 0 replies
- 3 kudos
- 3020 Views
- 2 replies
- 1 kudos
Databricks Vector Search Integration: Powering Claude Desktop with MCP
https://medium.com/@bijumathewt/databricks-vector-search-integration-powering-claude-desktop-with-mcp-838c591b50b5

- 3020 Views
- 2 replies
- 1 kudos
- 1 kudos
Good Question Edonaire. There 2 options here. Continuous and Triggered. If continuous, it will take care of incrimental load automatically, but costly.Triggered can be filed by setting up job with a task to run the "Refresh" code.
- 1 kudos
- 1232 Views
- 0 replies
- 1 kudos
From Data to Deck — Auto-Generate PowerPoint from Databricks
Creating PowerPoint decks from data is usually manual and repetitive:Export charts → take screenshots → format slides → repeat.Not anymore.You can now generate a complete PowerPoint directly from a Databricks table — in one notebook run. What this do...

- 1232 Views
- 0 replies
- 1 kudos
- 2229 Views
- 2 replies
- 8 kudos
Congratulations to Matei Zaharia - CTO Databricks on the ACM Prize in Computing
When I saw the news that Matei Zaharia received the 2025 ACM Prize in Computing, I felt genuinely happy. It was not just another award announcement. It felt like a proud moment for the whole data engineering community. His work has helped shape the w...

- 2229 Views
- 2 replies
- 8 kudos
- 8 kudos
@Brahmareddy, what a beautiful tribute! It’s so inspiring to hear how that meeting at the Summit stayed with you.We’re so lucky to have contributors like you who recognize the heart behind the tech. Cheers to Matei and the whole Databricks family!
- 8 kudos
- 777 Views
- 1 replies
- 2 kudos
Austin’s Practical Data + AI Meetup
Austin data community, this one looks worth attending. Databricks DevConnect Austin is happening on Tuesday, April 14, 2026, from 5:00 PM to 9:00 PM at Qubika Office in Austin. It is a technical meetup built for data and AI practitioners who want rea...
- 777 Views
- 1 replies
- 2 kudos
- 2 kudos
Great opportunity to connect with amazing and like minded minds.Would love to see more such events in India as well, specially in Lucknow, Noida, Bhopal -- Events Team
- 2 kudos
- 466 Views
- 0 replies
- 1 kudos
Solution Proposal (Cost-Optimized Architecture)
Core IdeaDon’t let “1 pipeline = 1 always-on cluster” become your cost trap.Instead, design for controlled parallelism + shared compute + smart grouping. A. Pipeline Sharding Strategy (Not Blind Splitting)Instead of randomly splitting 6,700 tables i...
- 466 Views
- 0 replies
- 1 kudos
- 2846 Views
- 1 replies
- 6 kudos
MCP Servers on Databricks
MCP Servers on DatabricksGenerative AI is evolving rapidly, and one of the most exciting developments is standardizing how models interact with external systems. Let me walk you through how we got here and why the Model Context Protocol (MCP)—especia...


- 2846 Views
- 1 replies
- 6 kudos
- 6 kudos
Insightful, detailed and incisive guide @VinayKumarB. Keep posting!
- 6 kudos
- 577 Views
- 2 replies
- 3 kudos
Notifications for scheduled refreshes - now in Beta
If you’ve ever worked with scheduled refreshes for Materialized Views or Streaming Tables, you probably know this pain. If your DDL-scheduled MV or ST refresh failed, nothing happened. No email, no alert, no indication that your data was stale (until...

- 577 Views
- 2 replies
- 3 kudos
- 3 kudos
Welcome back, @szymon_dybczak! That silent failure pain was real. These alerts are a massive win for everyone’s sanity. Thanks for the heads-up!
- 3 kudos
-
Access Data
1 -
Access Delta Tables
1 -
ADF Linked Service
1 -
ADF Pipeline
1 -
Advanced Data Engineering
6 -
agent bricks
2 -
Agentic AI
3 -
AI
2 -
AI Agents
5 -
AI Readiness
1 -
AIBI
1 -
Analytics
1 -
Analytics Engineering
1 -
Apache spark
3 -
Apache Spark 3.0
2 -
ApacheSpark
1 -
Aqe
1 -
Architecture
5 -
Associate Certification
2 -
Audit
1 -
Auto-loader
1 -
Automation
1 -
AWSDatabricksCluster
2 -
Azure
3 -
Azure databricks
3 -
Azure Databricks Delta Table
3 -
Azure Databricks Job
2 -
Azure Delta Lake
3 -
Azure devops integration
1 -
Azure Unity Catalog
2 -
AzureDatabricks
2 -
BI Integrations
1 -
Big data
1 -
Billing and Cost Management
2 -
Blog
1 -
BroadcastJoin
1 -
Bronze Layer
1 -
Bronze Table
1 -
Caching
2 -
CDC
3 -
CDF
1 -
Certification
1 -
Certification Badge
1 -
Certification Exam
1 -
CICD
2 -
CICDForDatabricksWorkflows
1 -
Cluster
1 -
Cluster Policies
1 -
Cluster Pools
1 -
Collect
1 -
Community Event
1 -
CommunityArticle
2 -
Cost Optimization Effort
2 -
CostOptimization
3 -
custom compute policy
1 -
CustomLibrary
1 -
DABs
2 -
DAIS 0206
3 -
DAIS 2026
2 -
Dashboards
2 -
Data
1 -
Data Analysis with Databricks
1 -
Data Architecture
2 -
Data Driven AI Roadmap
1 -
Data Engineering
16 -
Data Governance
5 -
Data Ingestion
2 -
Data Ingestion & connectivity
1 -
data layout
1 -
Data Mesh
1 -
data optimization
1 -
Data Processing
1 -
Data Quality
2 -
Data warehouse
1 -
Data Warehousing
1 -
databricks
3 -
Databricks App
1 -
Databricks Apps
2 -
Databricks Assistant
2 -
Databricks Certified
1 -
Databricks Community
1 -
Databricks Dashboard
2 -
Databricks Delta Table
3 -
Databricks Demo Center
1 -
Databricks genAI associate
1 -
Databricks Job
2 -
Databricks Lakeflow
3 -
Databricks Lakehouse
2 -
Databricks Migration
3 -
Databricks Mlflow
1 -
Databricks News
1 -
Databricks Notebooks
1 -
Databricks Partner
1 -
Databricks Pyspark
3 -
Databricks Serverless
1 -
Databricks Support
1 -
Databricks Training
1 -
Databricks Unity Catalog
3 -
Databricks Workflows
3 -
DatabricksAutomation
1 -
DatabricksML
1 -
DatabricksOptimization
1 -
DataEngineering
1 -
DBR Versions
1 -
Declartive Pipelines
2 -
DeepLearning
1 -
Delta Lake
12 -
Delta Lake Files
1 -
Delta Live Table
2 -
Delta Live Tables
1 -
Delta Time Travel
1 -
Delta-lake
1 -
DeltaLake
1 -
DevOps
2 -
DimensionTables
1 -
DLT
3 -
DLT Pipeline
1 -
DLT Pipelines
3 -
DLT-Meta
1 -
Dns
1 -
Dynamic
1 -
Dynamic Partition
1 -
ETL Pipelines
2 -
fastapi
1 -
Free Databricks
3 -
Free Edition
1 -
GenAI
1 -
GenAI agent
2 -
GenAI and LLMs
4 -
GenAIGeneration AI
2 -
Generation AI
1 -
Generative AI
2 -
Generative AI Engineer
1 -
Genie
2 -
Git
1 -
GoldLayer
1 -
Google Bigquery
1 -
Google cloud
1 -
Governance
2 -
Governed Tag
1 -
hackathon
1 -
Hive metastore
1 -
Hubert Dudek
42 -
Hybrid Lakehouse
1 -
Kafka streaming
2 -
LakeBase
4 -
Lakeflow
1 -
Lakeflow Pipelines
1 -
Lakehouse
3 -
Lakehouse Migration
1 -
Langchain
1 -
LangGraph
1 -
Lazy Evaluation
1 -
Learning
1 -
Library Installation
1 -
Lineage
2 -
LiquidClustering
2 -
Live Tables CDC
1 -
Llama
1 -
LLM
1 -
LLMs
1 -
Machine Learning
1 -
mcp
2 -
Medallion Architecture
4 -
MERGE Performance
2 -
Metadata
2 -
Metric Views
2 -
Migration
1 -
Migrations
1 -
mosic ai search
1 -
MSExcel
3 -
Multi-Table Transactions
1 -
Multiagent
3 -
Networking
2 -
New Features
1 -
NotMvpArticle
1 -
Optimization
1 -
Optimize Command
1 -
Partitioning
3 -
Partner
1 -
Performance
2 -
Performance Tuning
3 -
PII
1 -
Powerbi
1 -
PredictiveOptimization
1 -
Private Link
1 -
Pyspark
6 -
Pyspark Code
1 -
Pyspark Databricks
1 -
Pytest
1 -
Python
1 -
Reading-excel
2 -
Row Level Security
1 -
SAP
2 -
Sap Hana Driver
1 -
Scala Code
1 -
Scd Type 2
1 -
Scripting
1 -
SDK
1 -
Security
1 -
Semantic Layer
1 -
Serverless
2 -
Spark
6 -
Spark Caching
1 -
Spark Performance
1 -
SparkSQL
1 -
SQL
3 -
Sql Scripts
2 -
SQL Serverless
1 -
streaming
1 -
streamlit
1 -
Structured streaming
1 -
Students
2 -
Support Ticket
1 -
Sync
1 -
Training
1 -
Tutorial
3 -
UCSD
1 -
Unit Test
1 -
Unity Catalog
12 -
Unity Cataloge
1 -
Unity Catlog
1 -
University Alliance
1 -
VACUUM Command
1 -
Variant
1 -
Warehousing
1 -
Workflow Jobs
1 -
Workflows
9 -
Zerobus
2 -
Zorder
1 -
Zordering
2
- « Previous
- Next »
| User | Count |
|---|---|
| 85 | |
| 75 | |
| 71 | |
| 60 | |
| 42 |