Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Databricks Issue:- assertion failed: Invalid s...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 12:41 AM
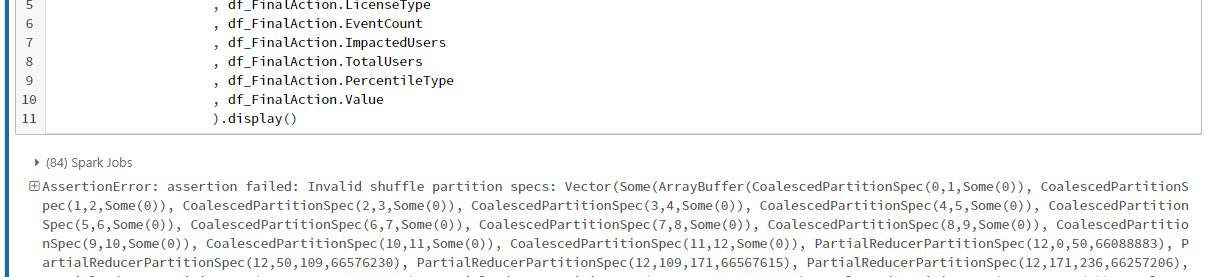
I hv a complex script which consuming more then 100GB data and have some aggregation on it and in the end I am simply try simply write/display data from Data frame. Then i am getting issue (assertion failed: Invalid shuffle partition specs: ).
Pls help me here, if any one have some idea.

Labels:


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2022 07:54 AM
Thanks Dudek, Finally I found the query where that have issue. As you suggested I debug step by step and run each every cell. And add the (spark.conf.set("spark.sql.shuffle.partitions",100)) at that cell. Its resolved 😀
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 03:42 AM
It is hard to help in that case without seeing the whole code.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 04:02 AM
Added ".py" file in attachment, Pls have a look.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-27-2022 06:10 AM
Please use
display(df_FinalAction)Spark is lazy evaluated but "display" not, so you can debug by displaying each dataframe at the end of each cell.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2022 07:54 AM
Thanks Dudek, Finally I found the query where that have issue. As you suggested I debug step by step and run each every cell. And add the (spark.conf.set("spark.sql.shuffle.partitions",100)) at that cell. Its resolved 😀
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2022 04:10 AM
Thanks, it is excellent. If you want you can select my answer as the best one 🙂
My blog: https://databrickster.medium.com/
Announcements





{kind=link}
Related Content
- Getting 'Unauthorized Access' when Serverless compute is trying to read s3 bucket data in Data Engineering
- How to get MLflow OpenAI autolog traces from PySpark mapInPandas workers (and some pitfalls) in Generative AI
- Streaming Table data leakage to historical permanent table in Data Engineering
- Python DataSource API utilities/ Import Fails in Spark Declarative Pipeline in Data Engineering
- Why is spark creating 5 jobs and 200 tasks? in Data Engineering