Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Did any one in the community create Permanent ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2021 06:37 PM
Hi Team, When i am trying to register a permanant function i am getting the below error.
%sql
CREATE FUNCTION simple_udf AS 'SimpleUdf'
USING JAR '/tmp/SimpleUdf.jar';
%sql
select simple_udf(2)
Error Details :
com.databricks.backend.common.rpc.DatabricksExceptions$SQLExecutionException: org.apache.spark.sql.AnalysisException: Can not load class 'SimpleUdf' when registering the function 'default.simple_udf', please make sure it is on the classpath;
Labels:
- Labels:
-
Create function
-
Error Details


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 03:21 PM
Hi @Werner Stinckens , Yes i followed the same instructions and was trying to solve this with a java program then later planning to convert python script to a jar file.
Below is the program that i used , Using Eclipse i was able to generate the .jar file successfully by adding "org.apache.hadoop.hive.ql.exec.UDF" this class related jar into the project,
Code :
import org.apache.hadoop.hive.ql.exec.UDF;
public class SimpleUdf extends UDF {
public int evaluate(int value) {
return value + 10;
}
}
Jar file Link :
http://www.java2s.com/Code/Jar/h/Downloadhive041jar.htm
And then tried the below commands
%sql
CREATE FUNCTION simple_udf AS 'SimpleUdf'
USING JAR '/tmp/SimpleUdf.jar';
AND
%sql
CREATE FUNCTION simple_udf AS 'SimpleUdf'
USING JAR '/dbfs/tmp/SimpleUdf.jar';
%sql
select simple_udf(2)
I placed it on the File Store of data bricks cluster and it kept throwing the same error, please make sure the class path is correct.
13 REPLIES 13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 08:44 AM
Hi @Kaniz Fatma , Nice meeting you! Have you got a chance to create permanent functions in data bricks using python scripts, I am trying to anonymize the data using permanent views and permanent functions.. but i am having trouble in creating permanent functions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 03:23 PM
Hi @Werner Stinckens , Yes i followed the same instructions and was trying to solve this first for java program then later planning to convert python script to a jar file.
Below is the program that i used , Using Eclipse i was able to generate the .jar file successfully by adding "org.apache.hadoop.hive.ql.exec.UDF" this class file related jar into the project,
Code :
import org.apache.hadoop.hive.ql.exec.UDF;
public class SimpleUdf extends UDF {
public int evaluate(int value) {
return value + 10;
}
}
Jar file Link :
http://www.java2s.com/Code/Jar/h/Downloadhive041jar.htm
I placed it on the File Store of data bricks cluster and kept throwing the same error, please make sure the class path is correct.
I see you are from Data Bricks did you guys any documentation that helps me understand with an example...
Below is there but its not clear
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 12:14 AM
it seems the cluster cannot find the jar. My guess is your path is incorrect/incomplete or as the error says it: you have to let the cluster know where the jar can be found (classpath)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 03:19 AM
probably correct path is /dbfs/tmp/SimpleUdf.jar
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 08:19 AM
hi @Manoj Kumar Rayalla ,
Like @Hubert Dudek mentioned, make sure to check what is the exact location for your Jar file. Make sure to list your path first to check if the file it located in the right location.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 08:41 AM
Thanks for the Suggestions @Werner Stinckens @Jose Gonzalez
@Hubert Dudek . No luck in changing the path
Did anyone else got the same error while creating permanent functions using python script? I see java and scala has documentation but not python.
Thanks,
Manoj
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 09:15 AM
ok now I see the issue: you want to use python, but provide a jar (for java/scala).
I remember another post asking for sql functions in python:
I would think the USING FILE would work.
As long as you follow the class_name requirements.
The implementing class should extend one of the base classes as follows:
- Should extend UDF or UDAF in org.apache.hadoop.hive.ql.exec package.
- Should extend AbstractGenericUDAFResolver, GenericUDF, or GenericUDTF in org.apache.hadoop.hive.ql.udf.generic package.
- Should extend UserDefinedAggregateFunction in org.apache.spark.sql.expressions package.
Also the docs literally state python is possible:
In addition to the SQL interface, Spark allows you to create custom user defined scalar and aggregate functions using Scala, Python, and Java APIs. See User-defined scalar functions (UDFs) and User-defined aggregate functions (UDAFs) for more information.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 03:21 PM
Hi @Werner Stinckens , Yes i followed the same instructions and was trying to solve this with a java program then later planning to convert python script to a jar file.
Below is the program that i used , Using Eclipse i was able to generate the .jar file successfully by adding "org.apache.hadoop.hive.ql.exec.UDF" this class related jar into the project,
Code :
import org.apache.hadoop.hive.ql.exec.UDF;
public class SimpleUdf extends UDF {
public int evaluate(int value) {
return value + 10;
}
}
Jar file Link :
http://www.java2s.com/Code/Jar/h/Downloadhive041jar.htm
And then tried the below commands
%sql
CREATE FUNCTION simple_udf AS 'SimpleUdf'
USING JAR '/tmp/SimpleUdf.jar';
AND
%sql
CREATE FUNCTION simple_udf AS 'SimpleUdf'
USING JAR '/dbfs/tmp/SimpleUdf.jar';
%sql
select simple_udf(2)
I placed it on the File Store of data bricks cluster and it kept throwing the same error, please make sure the class path is correct.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 11:15 PM
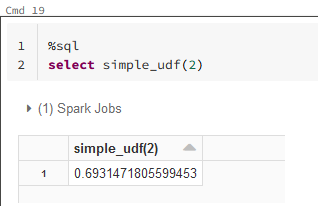
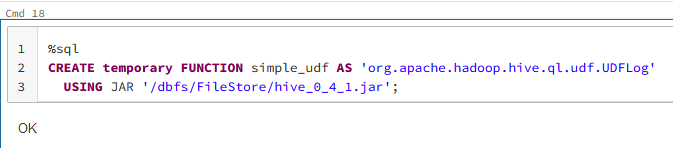
Ok, so I tried your example myself.
The issue lies within your jar.
- the jar you provide is not called 'SimpleUdf.jar' but 'hive_0_4_1.jar'.
- your jar should contain a class called 'SimpleUdf', but there is no such function in there.
So I used your jar and tried myself, using a class which is in the jar:


What this function does, I have no idea. But it is important that you point to an existing class, and take the complete name, not only the last part (so in this case org.apache.hadoop.hive.ql.udf.UDFLog and not just UDFLog).
Hope this helps.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-26-2022 01:45 PM
hi @Werner Stinckens @Jose Gonzalez @Hubert Dudek @Kaniz Fatma
Thanks for all the help, Appreciate it. I was able to create permanent functions and use eclipse to create the runnable jar. However, Does anyone have any idea on how to deploy the jar on SQL End Point Cluster.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2022 12:14 AM
I doubt if that is possible at the moment, it would also go against the use of photon (which is C++).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2022 05:10 AM
As SQL End Point is serverless I doubt it is possible
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-14-2022 11:24 AM
Hi @Manoj Kumar Rayalla Would you please share how did you manage to resolve the issue at your side. I am facing the same error. I already had tried the above suggested details but no luck so far.
Thanks in advance!
Announcements





{kind=link}
{kind=link}
Related Content
- Databricks Runtime, Pyspark and Spark Versions in Data Engineering
- Genie Code severely regressed over the past 2 days — no longer behaves as before in Generative AI
- Running Spark Tests in Data Engineering
- Databricks orchestration job in Data Engineering
- Cost-Effective Databricks Pipeline for API Ingestion - Best Practices? in Data Engineering