Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Does partition pruning / partition elimination...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Does partition pruning / partition elimination not work for folder partitioned JSON files? (Spark 3.1.2)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-13-2022 07:59 AM
Imagine the following setup:
I have log files stored as JSON files partitioned by year, month, day and hour in physical folders:
"""
/logs
|-- year=2020
|-- year=2021
`-- year=2022
|-- month=01
`-- month=02
|-- day=01
|-- day=...
`-- day=13
|-- hour=0000
|-- hour=...
`-- hour=0900
|-- log000001.json
|-- <many files>
`-- log000133.json
""""Spark supports partition discovery for folder structures like this ("All built-in file sources (including Text/CSV/JSON/ORC/Parquet) are able to discover and infer partitioning information automatically" https://spark.apache.org/docs/latest/sql-data-sources-parquet.html#partition-discovery).
However, in contrast to PARQUET files, I found that Spark does not uses this meta information for partition pruning / partition elimination when reading JSON files.
In my use case I am only interested in logs from a specific time window (see filter😞
(spark
.read
.format('json')
.load('/logs')
.filter('year=2022 AND month=02 AND day=13 AND hour=0900')
)I'd expect that Spark would be able to apply the filters on the partition columns "early" and only scan folders matching the filters (e.g. Spark would not need to scan folders and read files under '/logs/year=2020').
However, in practice the execution of my query takes a lot of time. It looks to me as if Spark scans first the whole filesystem starting at '/logs' reads all files and then applies the filters (on the already read data). Due to the nested folder structure and the large number of folders/files this is very expensive.
Apparently Spark does not push down the filter (applies partition pruning / partition elimination).
For me it is weird that the behavior for processing JSON files differs from Parquet.
Is this as-designed or a bug?
For now, I ended up implementing partition pruning myself in a pre-processing step by using dbutils.fs.ls for scanning the "right" folders iteratively and assembling an explicit file list that I then pass on to the spark read command.
Labels:
- Labels:
-
Pyspark


16 REPLIES 16
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-13-2022 02:16 PM
Instead of nested directories, could you try single level partition and have you partition names as `year_month_day_hour` (assuming that you have your JSON files in hour directory only). In that way spark knows in one shot which partition it has to look at.
Querying could be expensive if your JSON files are very small in size (in KBs probably).
Maybe check the file sizes and instead of having log files per hour, you would be better off by having them partitioned by per day.
Last, maybe try querying using col function. Not sure if it'll help, but worth giving a try.
from pyspark.sql.functions import col
spark
.read
.format('json')
.load('/logs')
.filter( (col('year')=2022) & (col('month')=02) & (col('day')=13) & (col('hour')=0900'))Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-14-2022 11:19 AM
Hi @Aman Sehgal ,
thanks for your advice.
Unfortunately I have no influence on the partitioning of the data, I'm just a consumer 😣
Anyhow, I'd like to know why you think that Spark would be able to apply partition elimination if there would be just one partitioning level.
Imagine there would be data of 3 years, this would mean, that there would be 3*365*24=26,280 folders under \logs. As far as I can tell, Spark would still discover all those directories and load all found JSON files to memory before applying the filter.
Or are you suggesting determining the right folder manually and then loading from the correct folder?
This would be "manual" partition elimination, in my opinion.
(spark
.read
.format('json')
.load('/logs/2022_02_13_0900')
)I also tried using the col function in the filter. Unfortunately it had no performance impact over specifying the filter als "SQL condition string". 😟
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2022 06:10 AM
Spark wouldn't discover all the directories. It'll straightaway go to partition value.
Could you give more proof of your hypothesis? Like spark logs or DAG?
My next guess would be that the files in log files are small in size. Could you check that and post the file size in the final partition?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-15-2022 10:31 AM
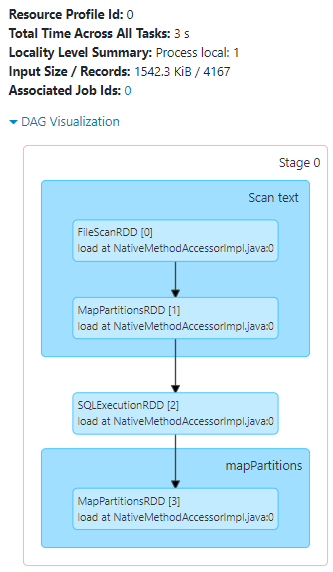
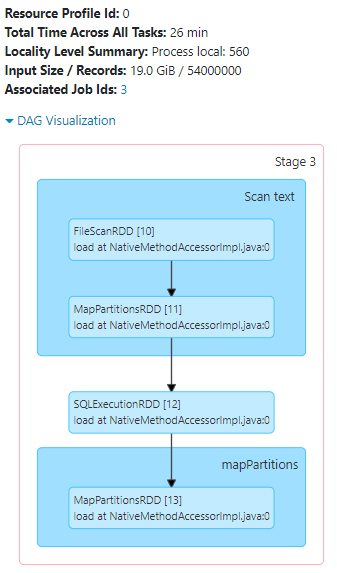
I created a test setup.
I generated lots of exemplary rows simulating log entries; for 90 days, each day with 600,000 log entries (=54,000,000 rows). Each entry has a log timestamp. I created another column for "binning" all entries in the nearest "5 minute" window.
I saved this data frame as JSON, partitioned by the 5min-timestamp column.
So I ended up with 12,960 folders containing each one JSON file.
Then I tried:
(
spark
.read
.format('json')
.load(f'{path_base_folder}/some_timestamp_bin_05m=2022-03-23 18%3A00%3A00')
.explain(extended=True)
)
As well as
(
spark
.read
.format('json')
.load(f'{path_base_folder}')
.filter( F.col('some_timestamp_bin_05m')=="2022-03-23 18:00:00")
.explain(extended=True)
)
Interestingly, prior to the read job, two more jobs are carried out; to scan the file system:

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-28-2022 08:55 AM
Any thoughts, @Aman Sehgal ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2022 12:32 PM
At this stage the only thing I can think of is the file format -JSON. Since you've the test setup can you write all the data in Parquet format or Delta format and then run the query?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2022 02:45 AM
Hi @Aman Sehgal ,
Yes, when I change the test setup to Parquet format, the partition elimination works.
This is my original question: Is the partition elimination supposed to work only for Parquet / ORC or also for JSON?
My findings show that it does not work for JSON - is this a bug or a not supported feature?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-11-2022 07:58 AM
Hi @Kaniz Fatma ,
Yes, I'd like to open a feature request.
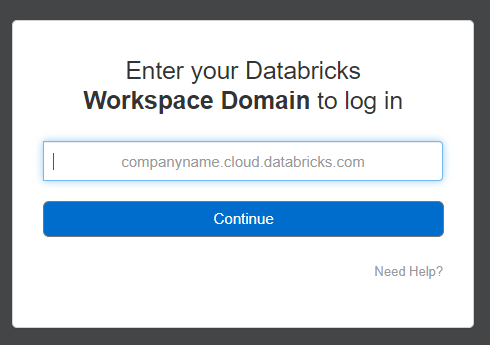
However, I cannot access the ideas portal.
I'm just a Community Edition user and don't have a workspace domain...

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-11-2022 08:55 AM
Hi @Kaniz Fatma ,
Are you positive that the ideas portal should work for Community Edition users?
When I try to log into the ideas portal using "community" workspace I always get an error message:

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-17-2022 10:30 AM
Hi @Kaniz Fatma , any updates?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-23-2022 10:14 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-15-2022 03:42 AM
Hi @Kaniz Fatma ,
Any updates on this one?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2022 05:49 AM
Hi @Kaniz Fatma ,
Yes I did. This time no more error is displayed as before.
But following your link https://databricks.com/feedback I end up on the landing page in my community workspace; I had expected a feedback portal.
I my workspace, under "help" there is another "feedback" button:

Is this the intended way to make feature requests?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2022 01:02 PM
Hi @Kaniz Fatma ,
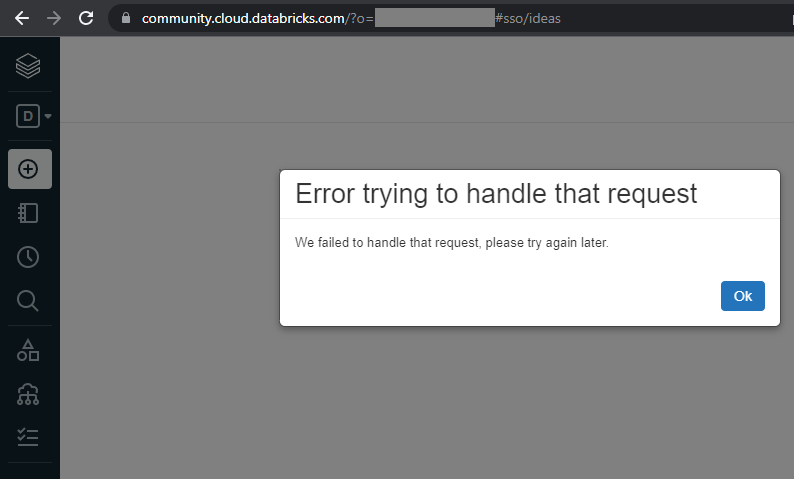
When I try to access https://ideas.databricks.com/ the situation just as I described a month ago: after the login an error is displayed:

Are you positive that Databricks community edition (=free) users are allowed to access the ideas portal?
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Lakeflow SDP partition error in Data Engineering
- Partition optimization strategy for task that massively inflate size of dataframe in Data Engineering
- Partition cols for a temporary table in Lakefow SDP in Data Engineering
- DLT table reading not performing file pruning on partition column in Data Engineering
- Liquid Clustering and S3 Performance in Data Engineering