Hi,
I am loading a JSON file into Databricks by simply doing the following:
from pyspark.sql.functions import *
from pyspark.sql.types import *
bronze_path="wasbs://....../140477.json"
df_incremental = spark.read.option("multiline","true").json(bronze_path)
display(df_incremental)
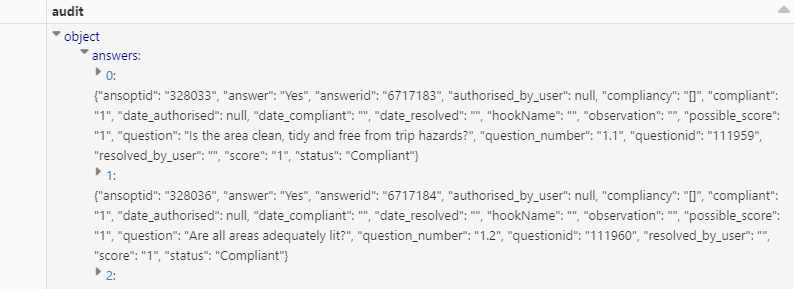
My JSON file is complicated and is displayed:

I want to be able to load this data into a delta table.
My schema is:
type AutoGenerated struct {
Audit struct {
Refno string `json:"refno"`
Formid string `json:"formid"`
AuditName string `json:"audit_name"`
AuditorName string `json:"auditor_name"`
Location string `json:"location"`
Fulllocation string `json:"fulllocation"`
Published string `json:"published"`
Date string `json:"date"`
Compliant string `json:"compliant"`
Archived string `json:"archived"`
Score string `json:"score"`
PossibleScore string `json:"possible_score"`
Percentage string `json:"percentage"`
Answers []struct {
QuestionNumber string `json:"question_number"`
Question string `json:"question"`
Status string `json:"status"`
Answerid string `json:"answerid"`
Questionid string `json:"questionid"`
Answer string `json:"answer"`
Ansoptid string `json:"ansoptid,omitempty"`
Observation string `json:"observation"`
Compliant string `json:"compliant"`
Score string `json:"score"`
PossibleScore string `json:"possible_score"`
DateResolved string `json:"date_resolved"`
ResolvedByUser string `json:"resolved_by_user"`
DateCompliant string `json:"date_compliant"`
Compliancy []interface{} `json:"compliancy"`
HookName string `json:"hookName"`
DateAuthorised string `json:"date_authorised,omitempty"`
AuthorisedByUser string `json:"authorised_by_user,omitempty"`
} `json:"answers"`
} `json:"audit"`
}
Any idea how to do this?







{kind=link}