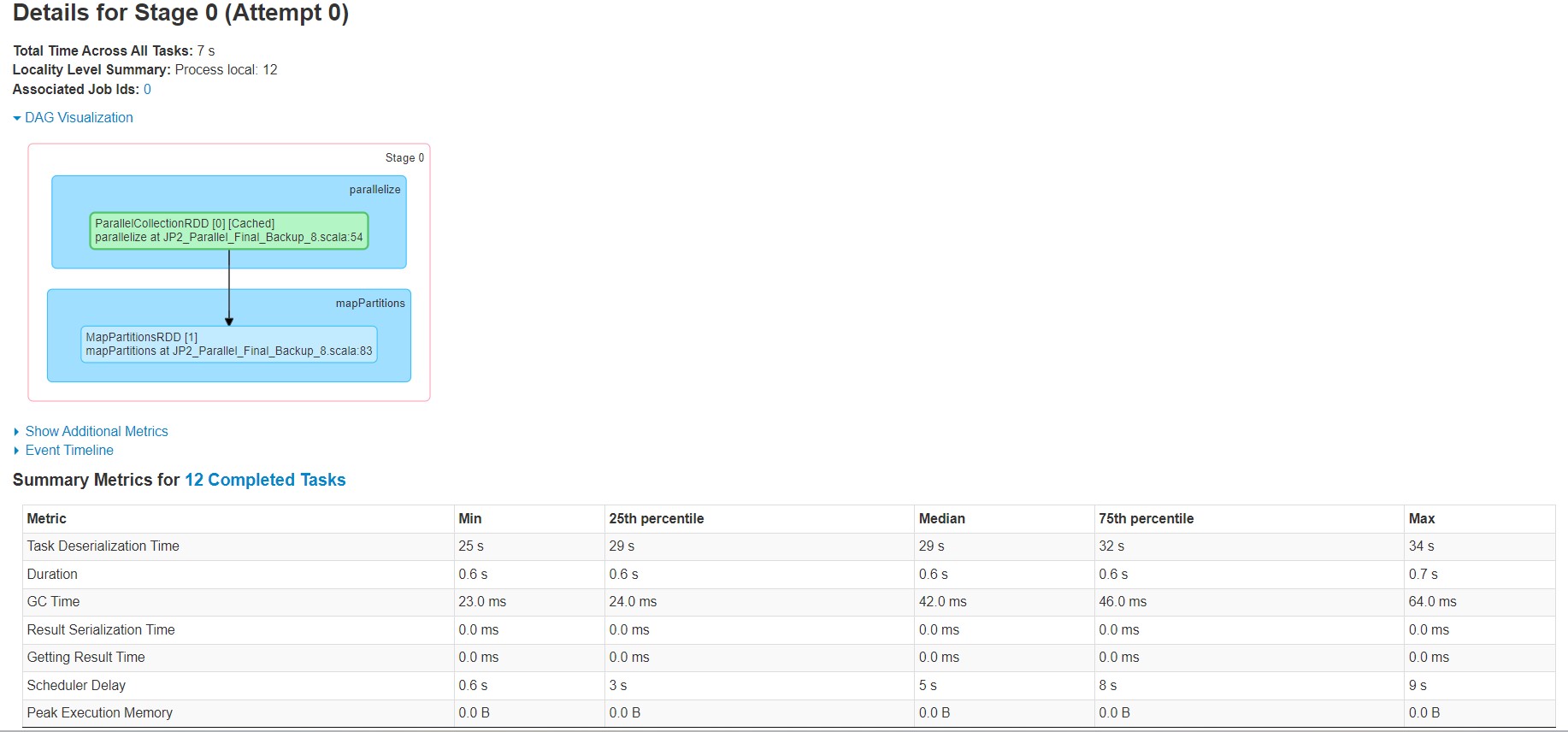
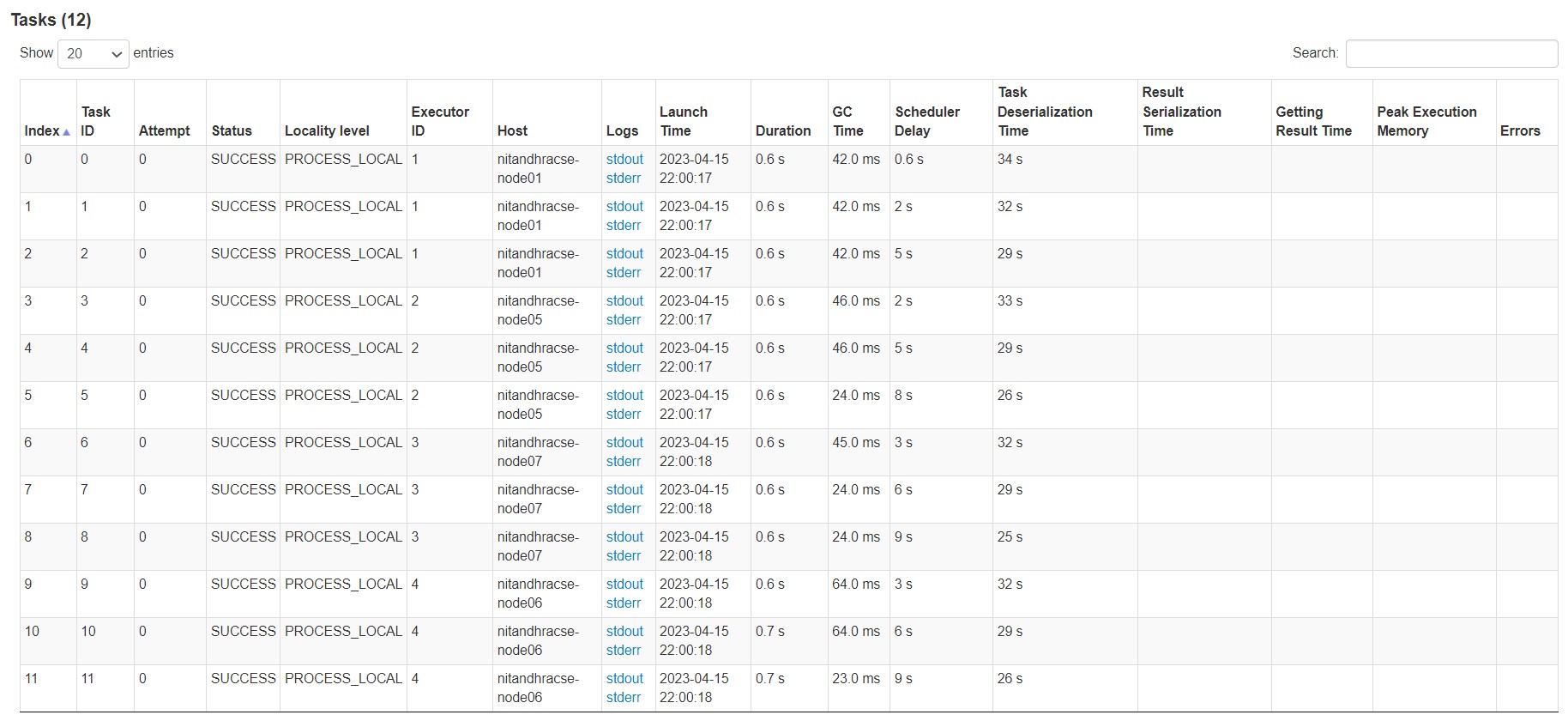
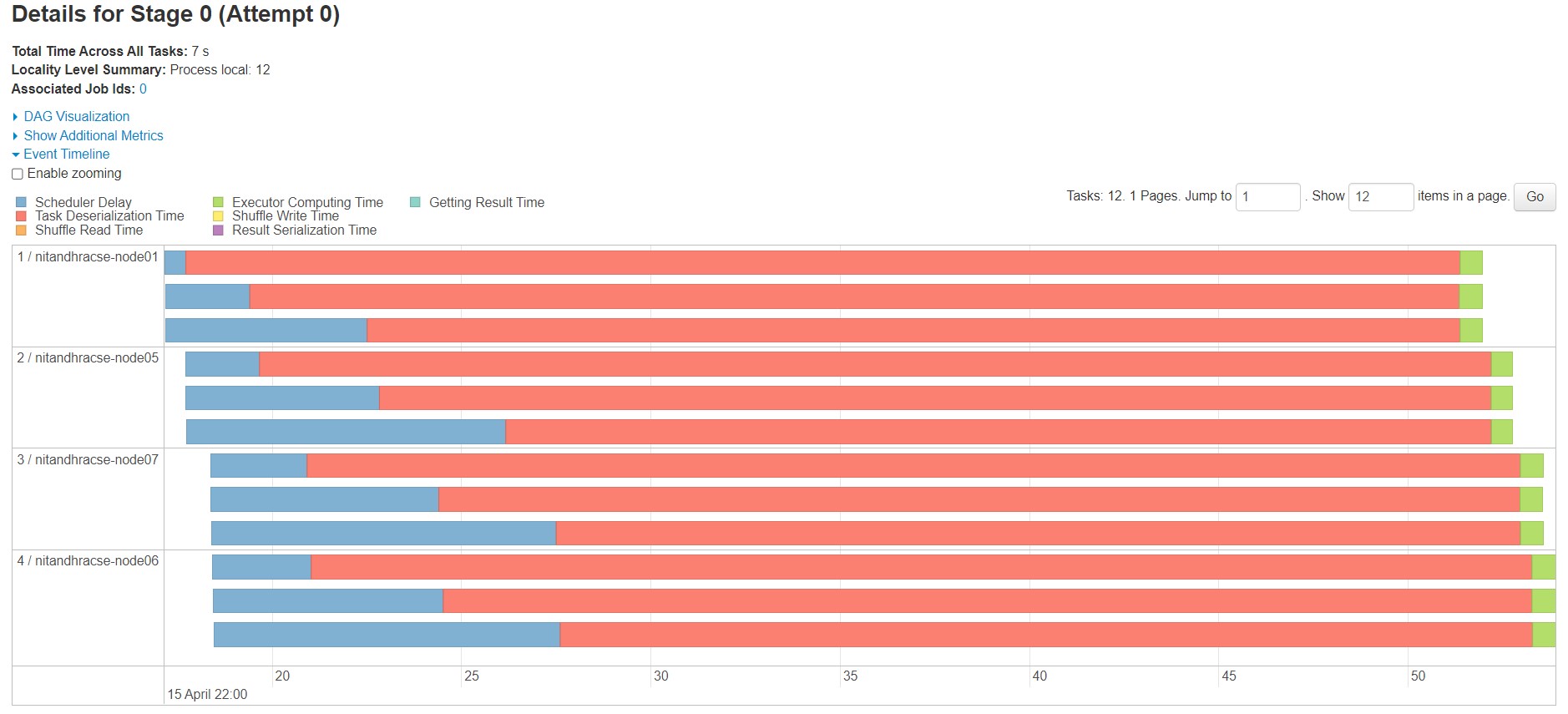
I will elaborate my problem. I am using a 6-node Spark cluster over Hadoop Yarn out of which one node acts as the master and the other 5 are acting as worker nodes. I am running my Spark application over the cluster. After completion, when I check the Spark UI, I observe a longer execution time due to longer Scheduler Delay and Task Deserialization Time even though the Executor Computing Time is very low. The total running time is 81 sec when it should complete in less than 8 sec. I could not get help from any existing posts on the net. I wish someone could help me solve this. What is the way to reduce both Scheduler Delay and Task Deserialization Time. Is the issue due to the sub-optimal way of writing code or due to bad configuration of Yarn and Spark? I attach a few images below. I will share any other things required for further analysis like Yarn, Spark configuration, application code etc. if necessary. Thanks in advance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}