Hi,I want to make a PySpark DataFrame from a Table. I would like to ask about the difference of the following commands:spark.read.table(TableName)&spark.table(TableName)Both return PySpark DataFrame and look similar. Thanks.
I installed databricks-sql-connector in Pycharm.Then i run the query below based on docs.I refer this docs.(https://docs.databricks.com/dev-tools/python-sql-connector.html)==========================================from databricks import sqlimport osw...
It seems that one of your environment variables is incorrect. Please print them and compare them with the connection settings from the cluster or SQL warehouse endpoint.
Hello, You can activate Audit logs ( More specifically Cluster logs) https://learn.microsoft.com/en-us/azure/databricks/administration-guide/account-settings/azure-diagnostic-logs It can be very helpful to track all the metrics.
let's suppose there is a database db, inside that so many tables are there and , i want to get the size of tables . how to get in either sql, python, pyspark.even if i have to get one by one it's fine.
This post will help you simplify your data ingestion by utilizing Auto Loader, Delta Optimized Writes, Delta Write Jobs, and Delta Live Tables. Pre-Req: You are using JSON data and Delta Writes commandsStep 1: Simplify ingestion with Auto Loader Delt...
This post will help you simplify your data ingestion by utilizing Auto Loader, Delta Optimized Writes, Delta Write Jobs, and Delta Live Tables.Pre-Req: You are using JSON data and Delta Writes commandsStep 1: Simplify ingestion with Auto Loader Delta...
Hi guys,this is my first question, feel free to correct me if i'm doing something wrong.Anyway, i'm facing a really strange problem, i have a notebook in which i'm performing some pandas analysis, after that i save the resulting dataframe in a parque...
Hello Bricksters,We organize the delta lake in multiple storage accounts. One storage account per data domain and one container per database. This helps us to isolate the resources and cost on the business domain level.Earlier, when a schema/database...
Cluster list in Microsoft.Azure.Databricks.Client fails because ClusterSource enum does not include MODELS.When you have a model serving cluster, ClustersApiClient.List method fails to deserialize the API response because that cluster has MODELS as C...
While reading data from BigQuery to Databricks getting the error : AnalysisException: Multiple sources found for bigquery (com.google.cloud.spark.bigquery.BigQueryRelationProvider, com.google.cloud.spark.bigquery.v2.BigQueryTableProvider), please spe...
Hi @Parul Paul , We haven’t heard from you since the last response from @Debayan Mukherjee , and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community as it can be helpful to others. ...
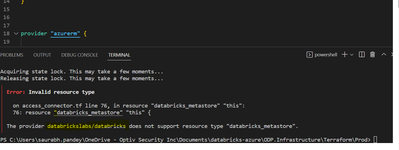
I am working on automation of Unity through terraform. I have referred below link link to get started :https://registry.terraform.io/providers/databricks/databricks/latest/docs/guides/unity-catalog-azureI am facing issue when I create metastore using...
Not sure if you got this working, but I noticed you are using provider: `databrickslabs/databricks`, hence why this is not avaialable. You should be using new provider: `databricks/databricks`: https://registry.terraform.io/providers/databricks/datab...
Hi @raja iqbal, We haven’t heard from you since the last response from @karthik p.Please don't forget to click on the "Select As Best" button whenever the information provided helps resolve your question.
I have a master notebook that runs a few different notebooks on a schedule using the dbutils.notebook.run() function. Occasionally, these child notebooks will fail (due to API connections or whatever). My issue is, when I attempt to catch the errors ...
When using db.fs.utils on a s3 bucket titled "${sometext}.${sometext}.${somenumber}${sometext}-${sometext}-${sometext}" we receive an error. PLEASE understand this is an issue with how it encodes the .${somenumber} because we verified with boto3 that...
@Debayan Mukherjee All the information is there please read accurately. I am not going to give you the actual bucket name I am using on a public forum. As i said above here is the command:dbutils.fs.ls("s3a://${bucket_name_here_follow_above_format}"...
Hi all!I would like to use a managed delta table as a temporal table, meaning:to create a managed table in the middle of ETL processto drop the managed table right after the processThis way I can perform merge, insert, or delete oprations better than...
Hi @Kwangwon Yi , We haven’t heard from you since the last response from @Werner Stinckens and @karthik p, and I was checking back to see if you have a resolution yet. If you have any solution, please share it with the community, as it can be help...
Hi @Raman Gupta Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.Thanks...