Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Is catalog a feature in the community version?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Is catalog a feature in the community version?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-16-2022 05:19 AM
%sql
create catalog if not exists catalog1I tried above, but it gives me error as below:
com.databricks.backend.common.rpc.DatabricksExceptions$SQLExecutionException: org.apache.spark.sql.AnalysisException: Catalog namespace is not supported.
at com.databricks.sql.managedcatalog.ManagedCatalogErrors$.catalogNamespaceNotSupportException(ManagedCatalogErrors.scala:40)
at com.databricks.sql.managedcatalog.ExceptionManagedCatalog.createCatalog(ExceptionManagedCatalog.scala:60)
at com.databricks.sql.managedcatalog.ManagedCatalogSessionCatalog.createCatalog(ManagedCatalogSessionCatalog.scala:357)
at com.databricks.sql.managedcatalog.command.CreateCatalogCommand.run(CatalogCommands.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:80)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:78)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:89)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.$anonfun$applyOrElse$1(QueryExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$8(SQLExecution.scala:239)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:386)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withCustomExecutionEnv$1(SQLExecution.scala:186)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:968)
at org.apache.spark.sql.execution.SQLExecution$.withCustomExecutionEnv(SQLExecution.scala:141)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:336)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:160)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$$nestedInanonfun$eagerlyExecuteCommands$1$1.applyOrElse(QueryExecution.scala:156)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:575)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:167)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:575)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:268)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:264)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:551)
at org.apache.spark.sql.execution.QueryExecution.$anonfun$eagerlyExecuteCommands$1(QueryExecution.scala:156)
Labels:
- Labels:
-
CatalogFeature
-
Community Version


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-02-2022 11:48 AM
Please check that your cluster (compute) works for Unity Catalog. See the screenshot and documentation for details.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 05:36 AM
@Sascha Vetter I am not seeing any option to enable Unity Catalog in Azure Databricks.
Configuration:
Databricks runtime version: 10.4 LTS (includes Apache Spark 3.2.1, Scala 2.12)
Standard_DS3_v2 14GB, 4 core is used.
Access mode: No Isolation shared.
What configuration I need to set to enable Unity Catalog?
Setting up the runtime to Runtime 11.2 is not working for me.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2022 11:03 AM
Are the requirements for Unity Catalog fulfilled? UC is available for "Premium plan or above" only and the account admin has to enable it.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-01-2022 09:11 AM
For me, selecting Runtime 11.1 did not work (i.e. 'unity catalog' didn't show up on the right-hand side under Summary). But when I selected Runtime 11.2, it popped up. Going to start playing with it now
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-01-2023 02:59 PM
I changed to 11.2 now in datafactory, that also worked
Announcements





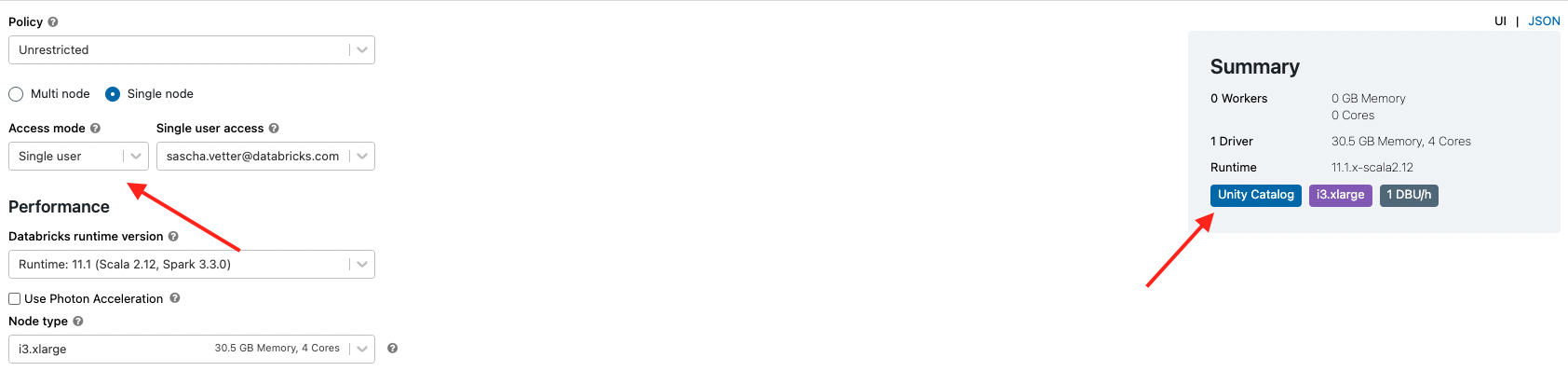{kind=link}
Related Content
- Documentation issue: Invalid JSON example in Lakeflow Connect multi-destination pipeline in Data Engineering
- Azure OpenAI v1 API support for External Model Serving / Mosaic AI Gateway? in Generative AI
- Databricks Runtime, Pyspark and Spark Versions in Data Engineering
- Custom and community connectors in Data Engineering
- I built a free 11-tab Cost Observability Dashboard as a Databricks App — open source in Administration & Architecture