Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: java.lang.OutOfMemoryError: GC overhead limit ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2021 09:51 PM
solution :-
i don't need to add any executor or driver memory all i had to do in my case was add this : - option("maxRowsInMemory", 1000).
Before i could n't even read a 9mb file now i just read a 50mb file without any error.
{
val df = spark.read
.format("com.crealytics.spark.excel").
option("maxRowsInMemory", 1000).
option("header", "true").
load("data/12file.xlsx")
}
I am trying to read a 8mb excel file,
i am getting this error.
i use intellij with spark 2.4.4
scala 2.12.12
and jdk 1.8
this is my code : -
val conf = new SparkConf()
.set("spark.driver.memory","4g")
.set("spark.executor.memory", "6g")
// .set("spark.executor.cores", "2")
val spark = SparkSession
.builder
.appName("trimTest")
.master("local[*]")
.config(conf)
.getOrCreate()
val df = spark.read
.format("com.crealytics.spark.excel").
option("header", "true").
load("data/12file.xlsx")
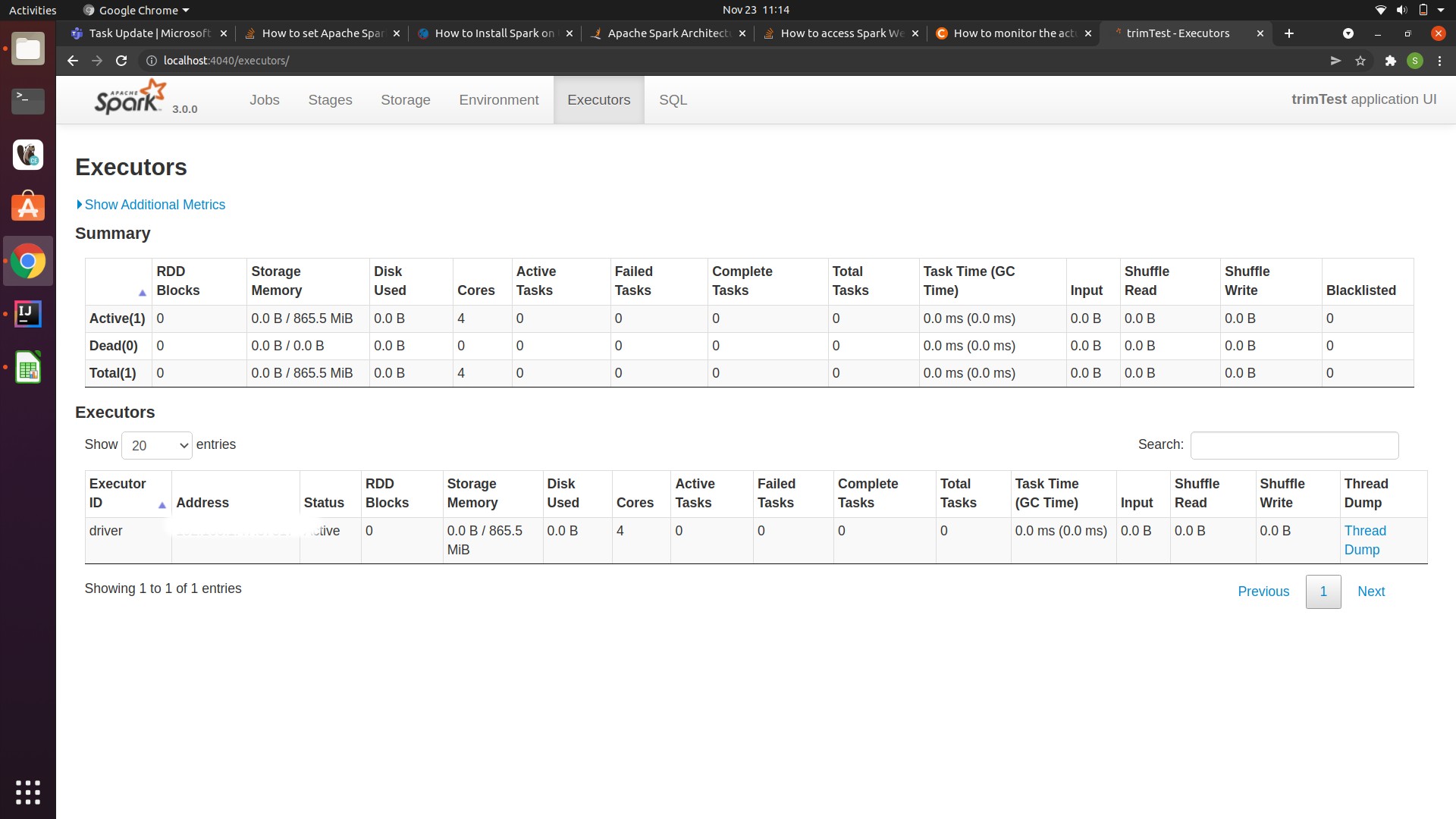
Now, these are my spark ui screenshots,
can you tell me what is the main issue and how can i increase the job executor memory.


stack :-
java.lang.OutOfMemoryError: GC overhead limit exceeded
at java.lang.Class.newReflectionData(Class.java:2511)
at java.lang.Class.reflectionData(Class.java:2503)
at java.lang.Class.privateGetDeclaredConstructors(Class.java:2660)
at java.lang.Class.getConstructor0(Class.java:3075)
at java.lang.Class.newInstance(Class.java:412)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:403)
at sun.reflect.MethodAccessorGenerator$1.run(MethodAccessorGenerator.java:394)
at java.security.AccessController.doPrivileged(Native Method)
at sun.reflect.MethodAccessorGenerator.generate(MethodAccessorGenerator.java:393)
at sun.reflect.MethodAccessorGenerator.generateMethod(MethodAccessorGenerator.java:75)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:53)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at sun.reflect.misc.MethodUtil.invoke(MethodUtil.java:276)
at com.sun.jmx.mbeanserver.ConvertingMethod.invokeWithOpenReturn(ConvertingMethod.java:193)
at com.sun.jmx.mbeanserver.ConvertingMethod.invokeWithOpenReturn(ConvertingMethod.java:175)
at com.sun.jmx.mbeanserver.MXBeanIntrospector.invokeM2(MXBeanIntrospector.java:117)
at com.sun.jmx.mbeanserver.MXBeanIntrospector.invokeM2(MXBeanIntrospector.java:54)
at com.sun.jmx.mbeanserver.MBeanIntrospector.invokeM(MBeanIntrospector.java:237)
at com.sun.jmx.mbeanserver.PerInterface.getAttribute(PerInterface.java:83)
at com.sun.jmx.mbeanserver.MBeanSupport.getAttribute(MBeanSupport.java:206)
at javax.management.StandardMBean.getAttribute(StandardMBean.java:372)
at com.sun.jmx.interceptor.DefaultMBeanServerInterceptor.getAttribute(DefaultMBeanServerInterceptor.java:647)
at com.sun.jmx.mbeanserver.JmxMBeanServer.getAttribute(JmxMBeanServer.java:678)
at com.sun.jmx.mbeanserver.MXBeanProxy$GetHandler.invoke(MXBeanProxy.java:122)
at com.sun.jmx.mbeanserver.MXBeanProxy.invoke(MXBeanProxy.java:167)
at javax.management.MBeanServerInvocationHandler.invoke(MBeanServerInvocationHandler.java:258)
at com.sun.proxy.$Proxy8.getMemoryUsed(Unknown Source)
at org.apache.spark.metrics.MBeanExecutorMetricType.getMetricValue(ExecutorMetricType.scala:67)
at org.apache.spark.metrics.SingleValueExecutorMetricType.getMetricValues(ExecutorMetricType.scala:46)
at org.apache.spark.metrics.SingleValueExecutorMetricType.getMetricValues$(ExecutorMetricType.scala:44)
at org.apache.spark.metrics.MBeanExecutorMetricType.getMetricValues(ExecutorMetricType.scala:60)


18 REPLIES 18
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2021 03:12 AM
Thank You i just found a solution, and i have mentioned it in my question to, while reading my file all i had to do was add this,
option("maxRowsInMemory", 1000).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-25-2021 03:13 AM
found a way
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2021 11:07 AM
Hi @sarvesh singh ,
Could you mark the "best" solution to your question please? it will help in case other community members have the se issue in the future.
Thank you
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2021 05:12 AM
done
- « Previous
-
- 1
- 2
- Next »
Announcements





{kind=link}
{kind=link}
Related Content
- Sizing Tables and delt logs/CDF in Data Engineering
- Why We Moved Our Operational Database Into Databricks — And Stopped Managing Two Stacks in Data Engineering
- Databricks SQL connection becomes stale in long-running app in Data Engineering
- Is Databricks AI/BI Genie worth it if we already have Power BI or Tableau? in Data Engineering
- Does enabling Change Data Feed on a Delta table affect OPTIMIZE and ZORDER performance? in Data Engineering