Hi there,
Trying to decide if I am going to get started with ml and really enjoyed it so far.
When going through the documentation, there was a blocker moment for me, as I feel the documentation doesn't mention much about the dataset used to train the model.
Model = Data + (Algorithm & hyperparameters )

I don't see an example in documentation where MLprojects is ran on different data (CSV ,SQL or code based etc..),
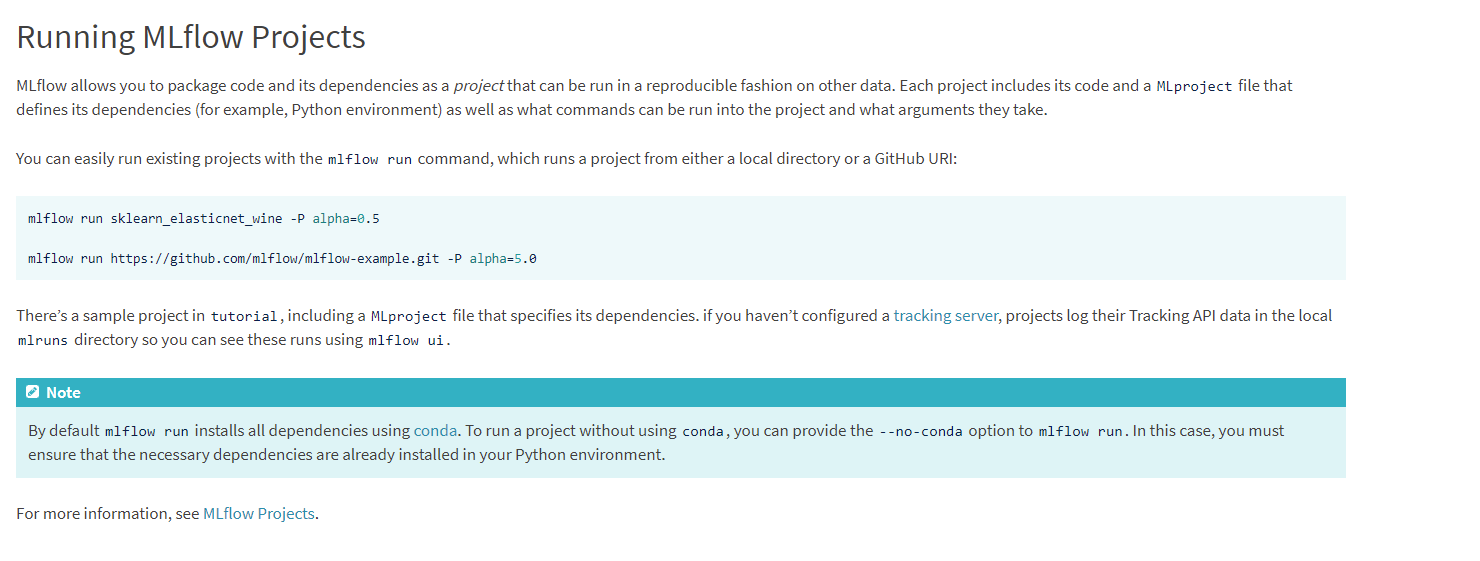
The code shown in the screenshot
"mlflow run sklearn_elasticnet_wine -P alpha = 0.5 would retrain a model with different hyperparameters, but on what data?
Has it already been included in the project, and can you change it to train the model on different data.
How do you store and track the datasets being used?
Can someone explain please?
Thanks,







{kind=link}