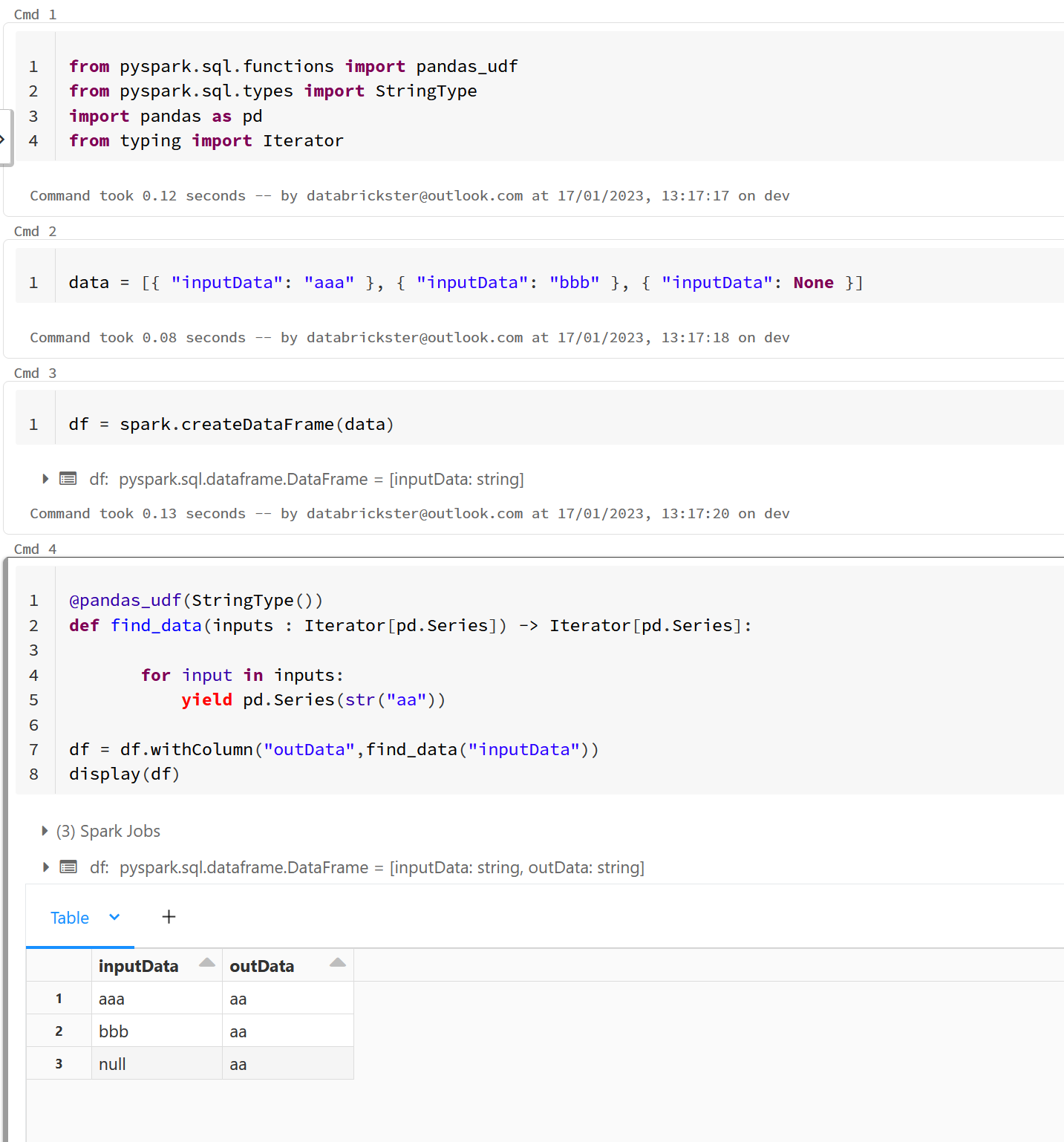
I have pandas_udf, its working for 1 rows, but I tried with more than one rows getting below error.
PythonException: 'RuntimeError: The length of output in Scalar iterator pandas UDF should be the same with the input's; however, the length of output was 1 and the length of input was 2.'.
Code
@func.pandas_udf(StringType())
def find_data(inputs : Iterator[pd.Series]) -> Iterator[pd.Series]:
for input in inputs :
--doing logic have for loop, if etc.
yield pd.Series(str(result_json))
df = df.withColumn("outData",find_data("inputData"))








{kind=link}