Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Reading Iceberg table present in S3 from datab...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Reading Iceberg table present in S3 from databricks console using spark given none error .
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-09-2023 05:23 AM
Hi Team ,
I am facing issue while reading iceberg table from S3 and getting none error when read the data .
below steps I followed .
- Added Iceberg Spark connector library to your Databricks cluster.
2. Cluster Configuration to Enable Iceberg
spark.sql.catalog.spark_catalog.warehouse /icebergpoc/
spark.sql.catalog.spark_catalog.type hadoop
spark.sql.catalog.spark_catalog org.apache.iceberg.spark.SparkCatalog
3.created Spark session and configure it to use the Iceberg Spark connector:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("myApp").getOrCreate()
# Configure the Iceberg Spark catalog
spark.conf.set("spark.sql.catalog.spark_catalog", "org.apache.iceberg.spark.SparkSessionCatalog")
spark.conf.set("spark.sql.catalog.spark_catalog.type", "hadoop")
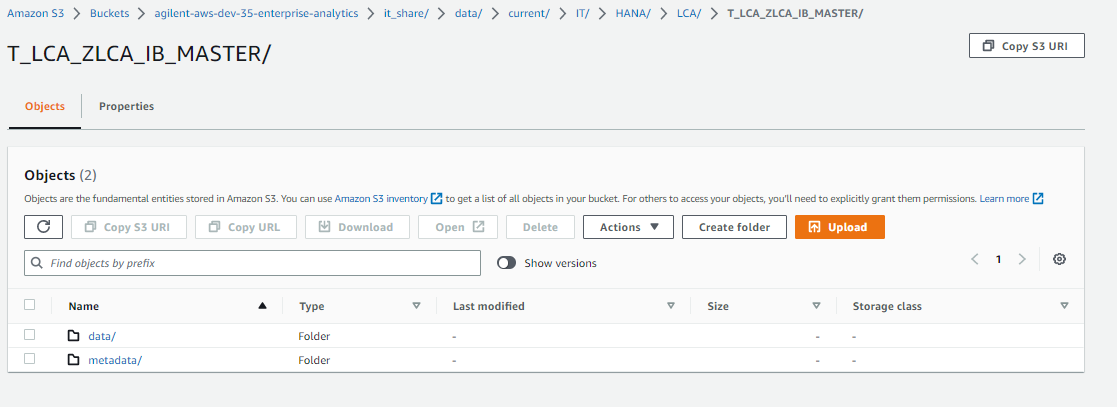
spark.conf.set("spark.sql.catalog.spark_catalog.uri", "s3://agilent-aws-dev-35-enterprise-analytics/it_share/data/current/IT/HANA/LCA/T_LCA_ZLCA_IB_MASTER/metadata/")
4. Load the Iceberg table as a DataFrame using the spark.read.format()
df = spark.read.format("iceberg").load("s3://agilent-aws-dev-35-enterprise-analytics/it_share/data/current/IT/HANA/LCA/T_LCA_ZLCA_IB_MASTER/")
getting Error .


Labels:
- Labels:
-
Databricks Cluster
-
Iceberg


8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-09-2023 11:31 PM
Hi, Could you please expand the error and provide the details here.
Please tag @Debayan with your next comment so that I will get notified. Thank you!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2024 02:39 PM
Could someone please post the solution, I am stuck in a similar issue. My Iceberg table is created by a separate spark sql script and now i need to read the Iceberg tables(created outside of databricks) from my Databricks notebook.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2024 09:13 AM
Hi @Retired_mod
I am using Databricks Runtime 10.4 ( Spark 3.2 ), so I have downloaded “iceberg-spark-runtime-3.2_2.12”
Also the table exists in the S3 bkt.
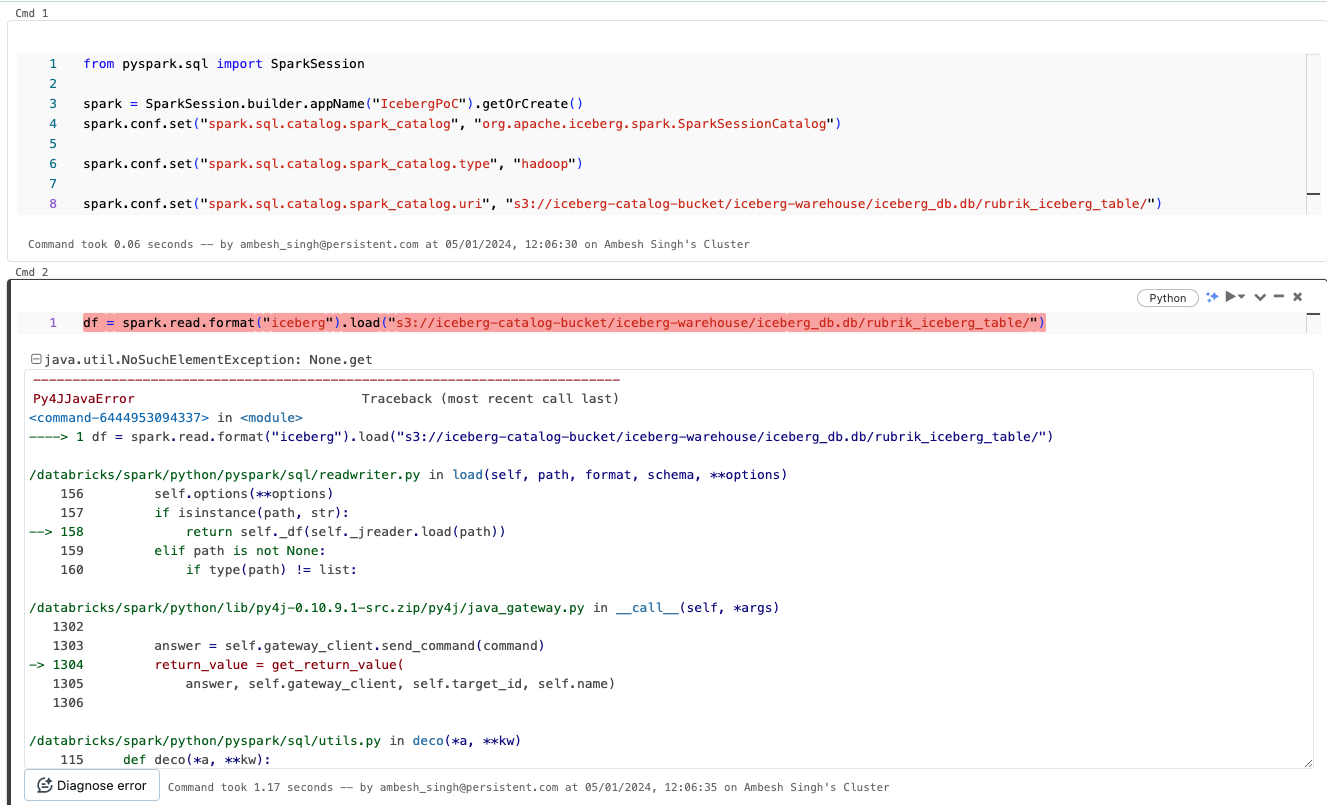
The error msg is: java.util.NoSuchElementException: None.get
I am also attaching a screenshot for reference.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-19-2025 08:25 PM - edited 02-19-2025 08:28 PM
Did you get your issue resolved ? I am also in the same situation.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-25-2025 06:26 PM
To use Apache Iceberg via the Hadoop Catalog on Databricks, it was found to work with the following settings:
- Use a Databricks Runtime version of 12.2LTS or earlier.
- Set the access mode to "No isolation shared" (the mode where Unity Catalog cannot be used).
- Use a library compatible with Java 8 (i.e., an Iceberg library earlier than version 1.6.1).
- Apply the necessary Iceberg-related settings in the Spark configuration.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2025 07:10 AM
I want to use both unity catalog and iceberg that is in a S3 path.
To use unity catalog I can't use access mode "No isolation shared".
Is there a solution for this?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-07-2025 01:28 PM
Did anyone find solution to use unity catalog and Iceberg table in databricks?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2026 12:44 AM
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Manage budgets and cost controls for Genie in Data Governance
- Locked out of my own Workspace Admin (ID: 1885148383889850) - Need assistance in Administration & Architecture
- Question About Workspace MFA Enforcement and Email OTP Behavior in Administration & Architecture
- DLT pipeline's compute policy when Instance pool Id used it ignores the VM series. in Data Engineering
- Data bricks + Network security perimeter (storage account) Error in Data Engineering