Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: SparkFiles - strange behavior on Azure databri...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2021 09:29 AM
When you use:
from pyspark import SparkFiles
spark.sparkContext.addFile(url)it adds file to NON dbfs /local_disk0/ but then when you want to read file:
spark.read.json(SparkFiles.get("file_name"))it wants to read it from /dbfs/local_disk0/. I tried also with file:// and many other creative ways and it doesn't work.
Of course it is working after using %sh cp - moving from /local_disk0/ to /dbfs/local_disk0/ .
It seems to be a bug like addFile was switched to dbfs on azure databricks but SparkFiles not (in original spark it addFile and gets to/from workers).
I couldn't find also any settings to manually specify RootDirectory for SparkFiles.
My blog: https://databrickster.medium.com/
Labels:
- Labels:
-
Azure
-
Azure databricks


23 REPLIES 23
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2022 04:42 AM
Hi @Kaniz Fatma, Ticket Number: #00125834.
It's been over a month since the ticket was opened, but still no response.
I tested it now with version 3.2.0 of Apache Spark on the Azure platform, it continues the same way with the message: "File not found". But in community.cloud.databricks the path is found and returns the expected result.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2022 05:14 AM
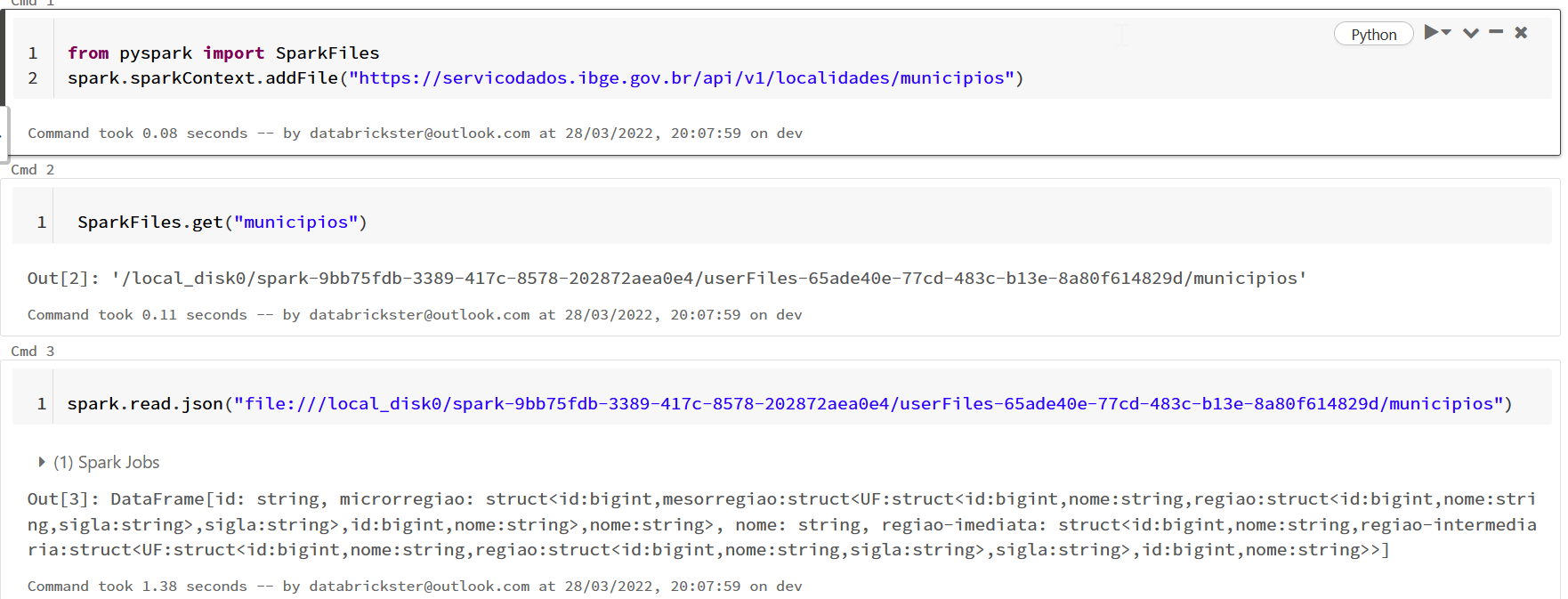
municipios = "https://servicodados.ibge.gov.br/api/v1/localidades/municipios"
from pyspark import SparkFiles
spark.sparkContext.addFile(municipios)
municipiosDF = spark.read.option("multiLine", True).option("mode", "OVERRIDE").json("file://"+SparkFiles.get("municipios"))I did not understand.
Please change the code above as instructed by you. @Kaniz Fatma
att,
Welder Martins
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2022 08:55 AM
Hi @Kaniz Fatma (Databricks), it ran without errors. The problem is that SparkFiles doesn't work on the Azure platform. I'm extracting data from the API with other functionality. I'm even using the URLLIB function palliatively. RDD will be deprecated as of Apache Spark version 3.0.
Thak's.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-25-2022 03:39 AM
@Kaniz Fatma hi, do you have access to orders that were opened in Databricks? The Ticket was opened in December 2021 and so far they have not commented on the deadline. Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
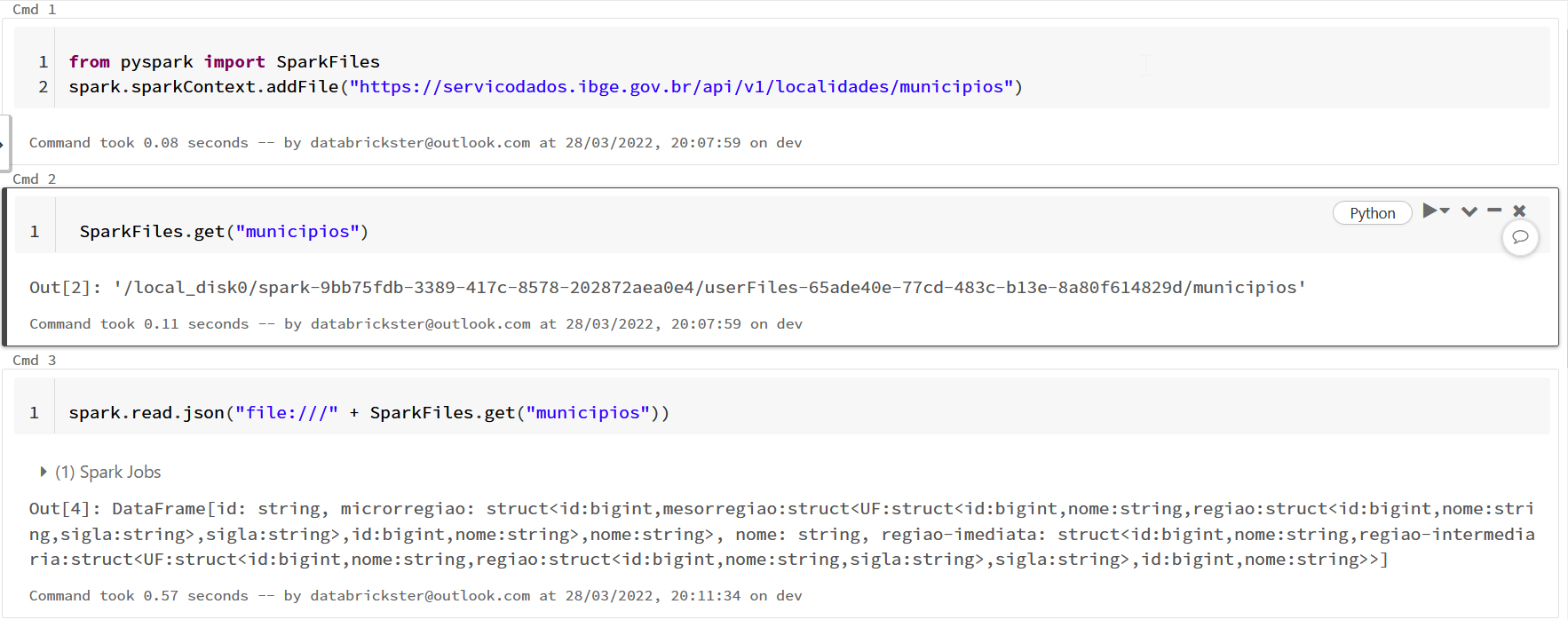
03-14-2022 08:20 AM
@Hubert Dudek
Have to tried with file:/// ?
I remember starting Spark 3.2, it honors the native hadoop file system if no file access protocol is defined.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-14-2022 03:13 PM
Hi it was few months ago. I need to check it again with new DR.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2022 11:08 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2022 11:19 AM
Hey,
But will this allocated address change? it would have to work according to the community. But thanks for the feedback.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-28-2022 11:37 AM

- « Previous
-
- 1
- 2
- Next »
Announcements





{kind=link}
{kind=link}
Related Content
- How does Databricks handle registration and discovery of custom PySpark data sources in SDPs? in Data Engineering
- Bundle deployment overwrites artifacts while jobs are running - best practices? in Data Engineering
- DAB bundle deploy --force-lock creates duplicate jobs after Azure DevOps pipeline failure in Data Engineering
- Unity Catalog External Location with Amazon S3 Access Points,session policy behavior and workarounds in Data Engineering
- DeltaFileStatistics on a nested column (`created date.shipment`) cause filtering issues in Data Engineering