Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Table write command stuck "Filtering files for que...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-23-2022 11:04 AM
Hello all,
Background:
I am having an issue today with databricks using pyspark-sql and writing a delta table. The dataframe is made by doing an inner join between two tables and that is the table which I am trying to write to a delta table. The table sometimes won't even do a row count (count()) but other-times for some reason it can, and the output is usually around 1.9 billion rows and it even in those cases will do a display (display() ).
Issue:
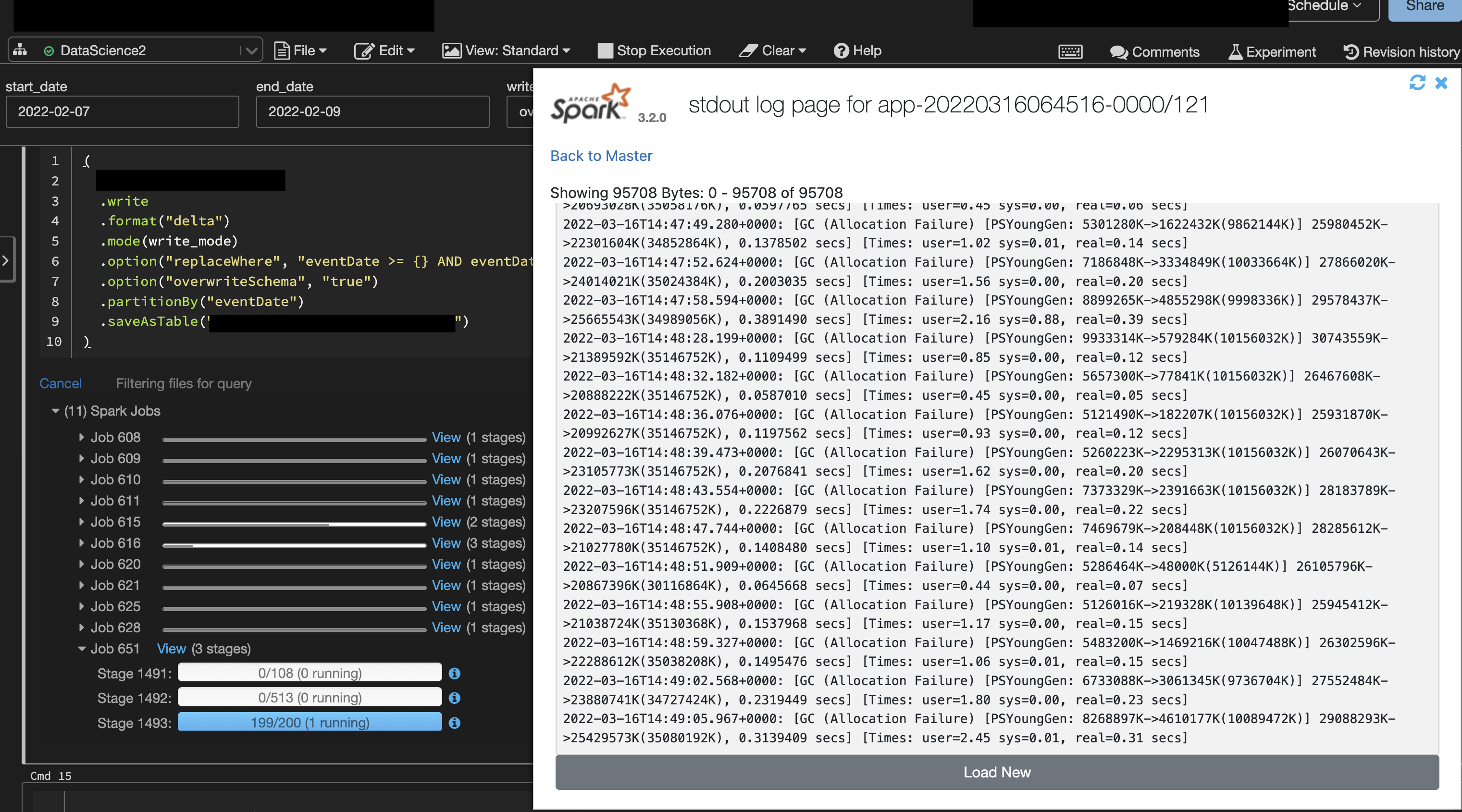
When going to write this dataframe into a delta table it kind of seems like it is getting stuck on one stage. The command I am using to write the table is as follows:
(
df
.write
.format("delta")
.mode(write_mode)
.option("replaceWhere", "eventDate >= {} AND eventDate < {}".format(start_date_str, end_date_str))
.option("overwriteSchema", "true")
.partitionBy("eventDate")
.saveAsTable("default.df")
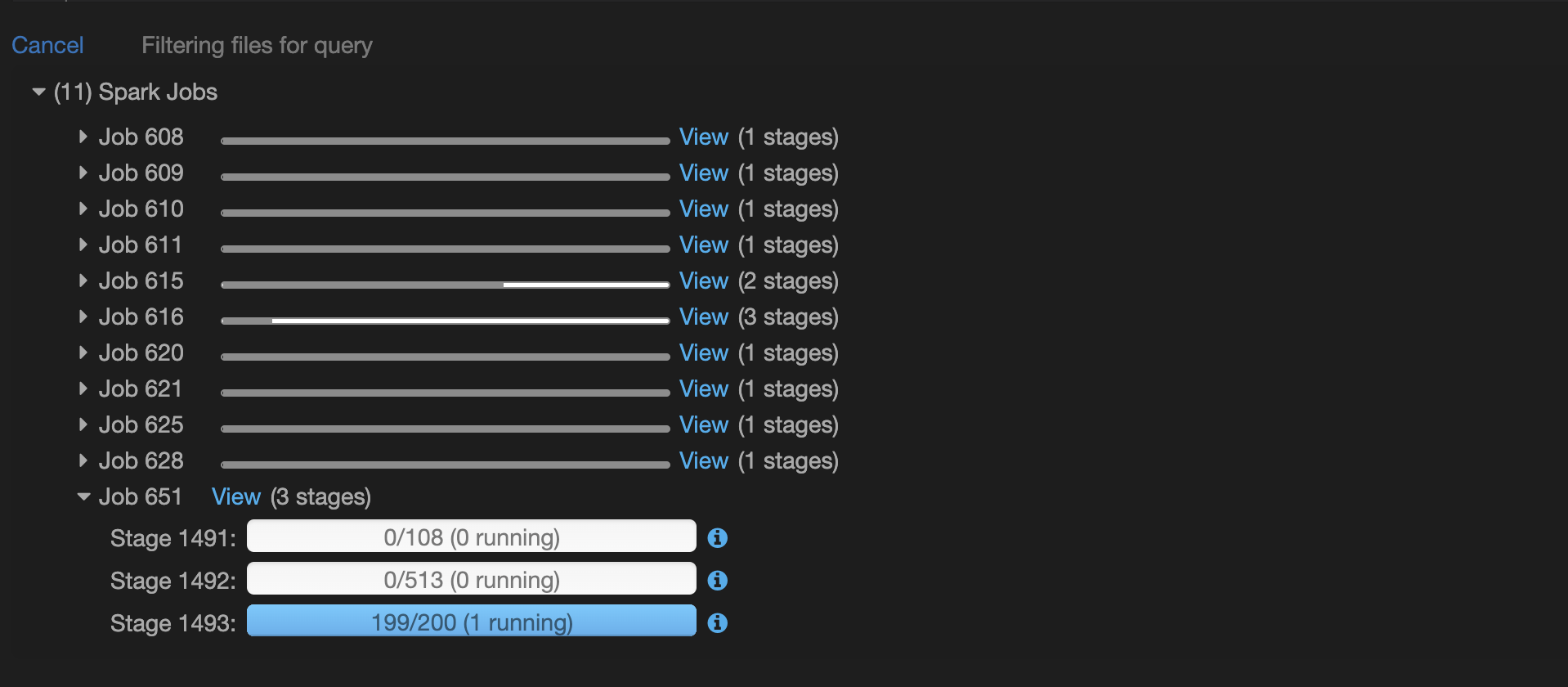
)The issue that arrises once it gets to one stage and says "Filtering files for query":



Can anyone give me any insight on what is going on? I have run this code for over 10 hours and nothing happens, it will always be stuck on that last stage with that same message of "Filtering files for query." From my understanding databricks optimizes delta tables really well, and I even have a partition on the table which I am trying to write. I am not a memory/cache expert so I am not sure if things can't be loaded into cache quick enough for it to write. Is there any insight anyone can provide?
Info on cluster:
Databricks runtime version: 10.2 (includes Apache Spark 3.2.0, Scala 2.12)
Worker type: i3.2xlarge 61GB memory, 8 cores
Driver type: i3.4xlarge 122GB memory, 16 cores
Thank you!
Labels:
- Labels:
-
Azure databricks
-
Cluster
-
Pyspark
-
Table
-
Write


1 ACCEPTED SOLUTION
Accepted Solutions
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-16-2022 02:48 AM
@Ljuboslav Boskic
there can be multiple reasons why the query is taking more time , during this phase metadata look-up activity happens, can you please check on the below things
- Ensuring the tables are z-ordered properly, and that the merge key (on clause) included the z-order key and the partition key in it.
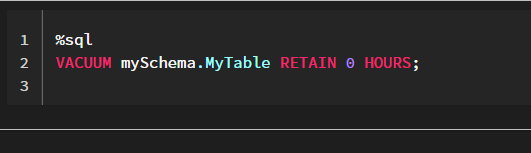
- you can use vacuum and optimise on the source delta tables and please find the below documents
https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-vacuum.html
https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-optimize.html
Please let us know if you still face the same issue
8 REPLIES 8
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-23-2022 02:30 PM
do you have there maybe unique id? so you could run easy MERGE (upsert):
MERGE INTO your_table USING your_new_view
ON your_table .uniqueId = your_new_view.uniqueId AND eventDate >= {} AND eventDate < {}
WHEN NOT MATCHED
THEN INSERT *
WHEN MATCHED
THEN UPDATE *My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-23-2022 02:41 PM
@Hubert Dudek , So let me backtrack one second, when I create the inner join I also put some conditions:
data_to_save =(
table1
.join(table2,
(table1.user == table2.user)
& (col("eventTime") >= col("tableTime"))
& (datediff(table1.eventDate,table2.tableEventDate) <= window)
,"inner")
)This is the table I want to write to a delta table.
The code snippet you put up, is this something I need to put in that write statement I had or prior in the join statement which I have pasted above?
As for your question:
Each row may not have one unique id. For example lets consider 10 rows - in those 10 rows, we may have 3 rows which have in one column called "user Id" to be the same but in another column called "eventId" be different. For me it is important to keep these rows separate due to having the same user id. I hope this answers your question.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2022 09:12 AM

Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-16-2022 02:48 AM
@Ljuboslav Boskic
there can be multiple reasons why the query is taking more time , during this phase metadata look-up activity happens, can you please check on the below things
- Ensuring the tables are z-ordered properly, and that the merge key (on clause) included the z-order key and the partition key in it.
- you can use vacuum and optimise on the source delta tables and please find the below documents
https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-vacuum.html
https://docs.databricks.com/spark/latest/spark-sql/language-manual/delta-optimize.html
Please let us know if you still face the same issue
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-07-2022 09:55 AM
Hi @Ljuboslav Boskic,
Just a friendly follow-up. Do you still need help or any of the responses helped to resolved your issue? please let us know.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-29-2024 11:22 PM
Even if I vacuum and optimize, it keeps getting stuck.
cluster type is r6gd.xlarge min:4, max:6
driver type is r6gd.2xlarge
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-13-2025 09:40 AM
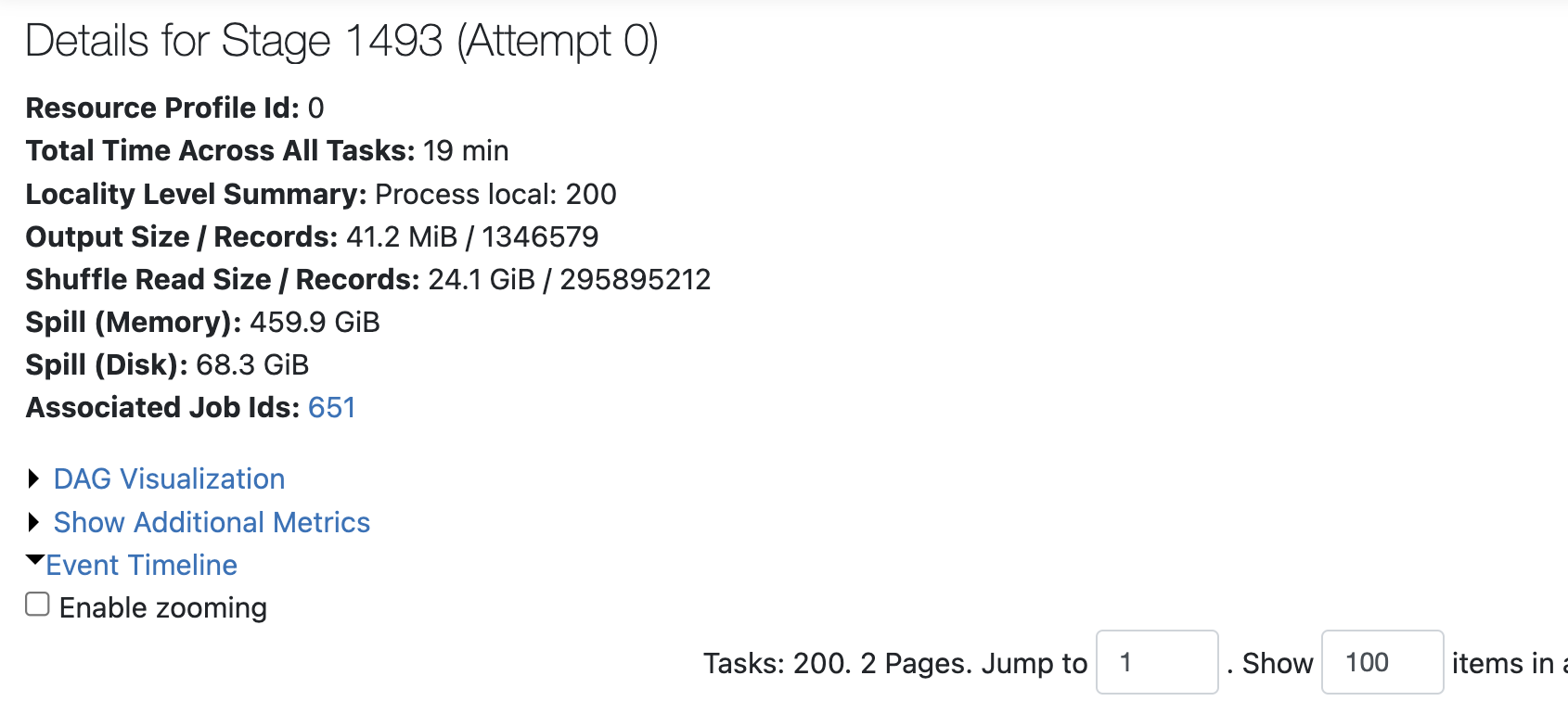
@timo199 , @boskicl I had similar issue and job was getting stuck at Filtering Files for Query indefinitely. I checked SPARK logs and based on that figured out that we had enabled PHOTON acceleration on our cluster for job and datatype of our columns being used for join have datatype with string collation.
Following was the error message that I got in logs:-
Photon does not fully support the query because:
collationkey(FAC_PID_FACILITY#5813) is not supported:
The expression cannot be photonized for reason 'UNSUPPORTED_DATATYPE'. collationkey(OST_RID_OUTSTANDNG#6304) is not supported:
The expression cannot be photonized for reason 'UNSUPPORTED_DATATYPE'To resolve this, we had turned off PHOTON acceleration setting on cluster and then job succeeded.
Hope this might help for some folks.
Thanks!
Nitin
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-13-2025 10:11 AM
Thanks for sharing!
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- Can Run Notebook Permission in Data Governance
- No Egress for Serverless Workspace in Administration & Architecture
- Genie Code hallucinates CLI commands in Data Engineering
- Table history time travel in Data Engineering