Hello,
I want to create an sql udf as follows:
%sql
CREATE or replace FUNCTION get_type(s STRING)
RETURNS STRING
LANGUAGE PYTHON
AS $$
def get_type(table_name):
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
return spark.sql(f'describe extended {table_name}').filter(col('col_name')=='Type').select('data_type').collect()[0]['data_type']
return get_type(s) if s else None
$$
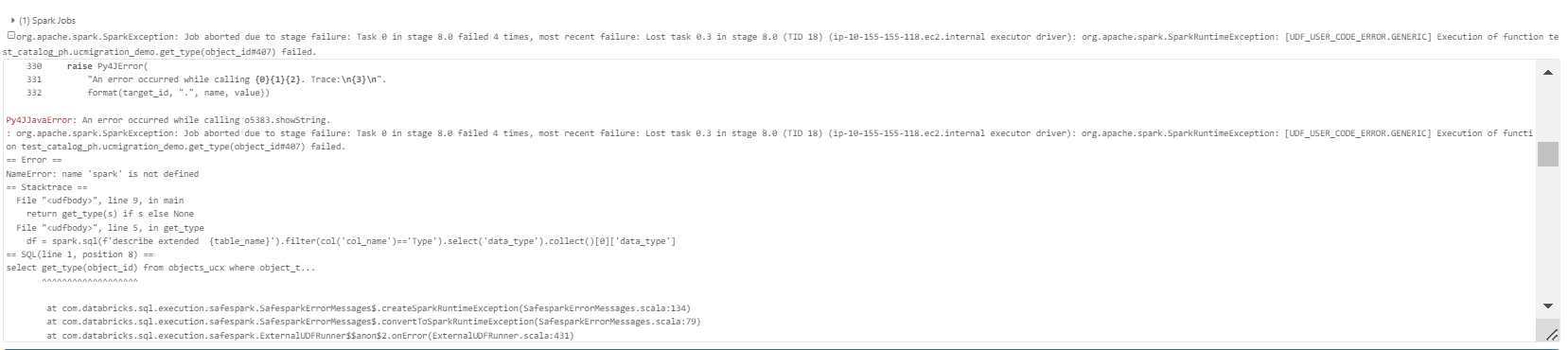
I can verify that get_type function is created in my unity catalog. But while accessing it, it's throwing the error and not working as expected. I am attaching the error message as attachment. Can you please help me with this.







{kind=link}