@yu zhang :
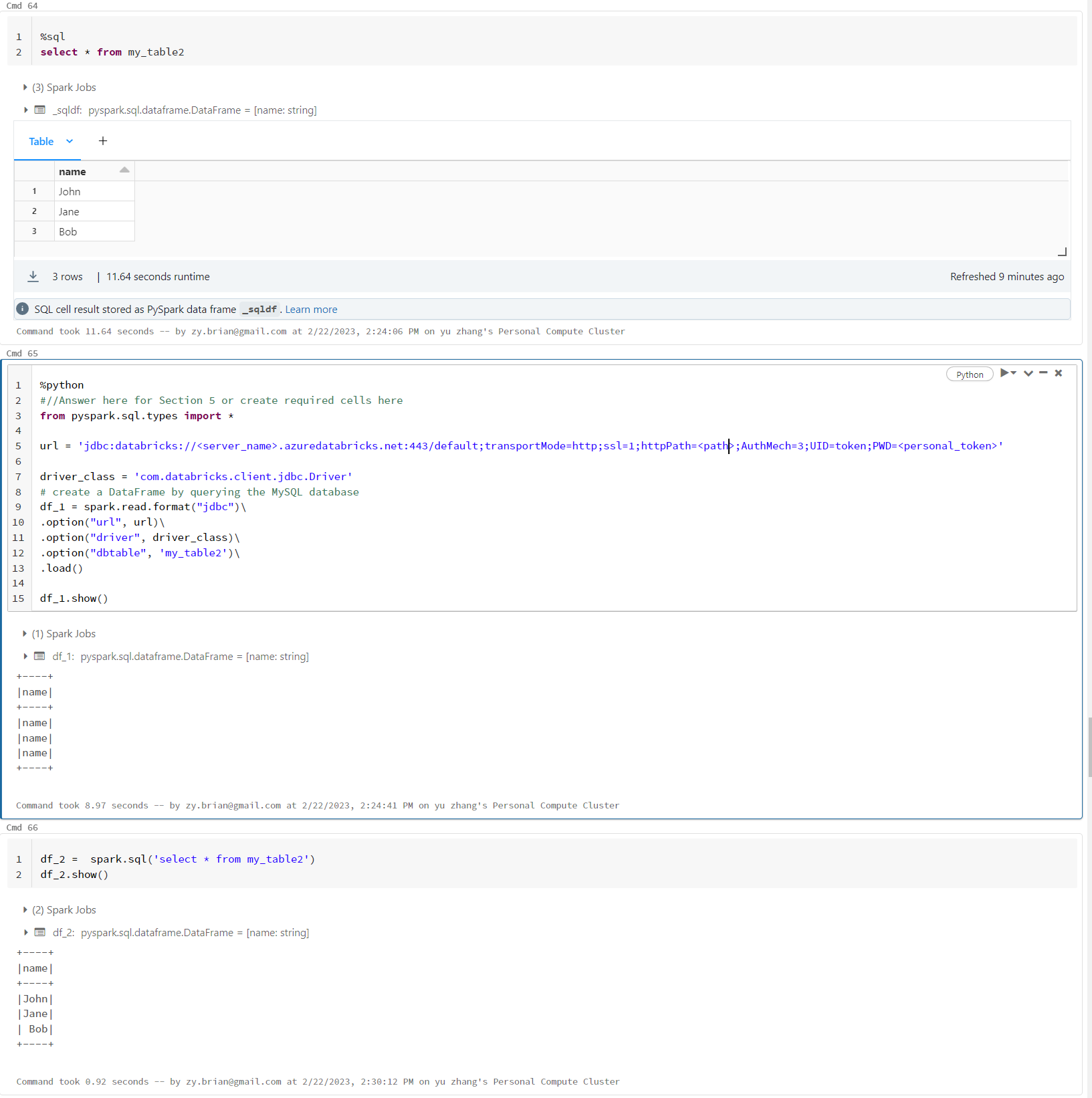
It looks like the issue with the first code snippet you provided is that it is not specifying the correct query to retrieve the data from your database.
When using the load() method with the jdbc data source, you need to provide a SQL query in the
dbtable option that retrieves the data you want to load into the DataFrame.
Assuming that your my_table2 table contains a column named name with the values you listed, you can modify your code as follows to retrieve the correct data:
url = 'jdbc:databricks://[workspace domain]:443/default;transportMode=http;ssl=1;AuthMech=3;httpPath=[path];AuthMech=3;UID=token;PWD=[your_access_token]'
driver_class = 'com.databricks.client.jdbc.Driver'
# create a DataFrame by querying the MySQL database
df_1 = spark.read.format("jdbc")\
.option("url", url)\
.option("driver", driver_class)\
.option("dbtable", '(select name from my_table2) as tmp')\
.load()
df_1.show()
This code passes a SQL query to the dbtable option that selects only the name column from your
my_table2 table. The resulting DataFrame should contain the data you expect.
Alternatively, you can use the spark.sql method to directly execute a SQL query against your database and load the results into a DataFrame, as you showed in your second code snippet:
df_2 = spark.sql('select * from my_table2')
df_2.show()
This code should also retrieve the correct data from your database.








{kind=link}