Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Using "Select Expr" and "Stack" to Unpivot PyS...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2022 09:07 PM
I am trying to unpivot a PySpark DataFrame, but I don't get the correct results.
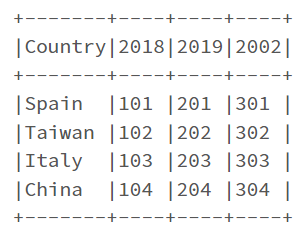
Sample dataset:
# Prepare Data
data = [("Spain", 101, 201, 301), \
("Taiwan", 102, 202, 302), \
("Italy", 103, 203, 303), \
("China", 104, 204, 304)
]
# Create DataFrame
columns= ["Country", "2018", "2019", "2002"]
df = spark.createDataFrame(data = data, schema = columns)
df.show(truncate=False)
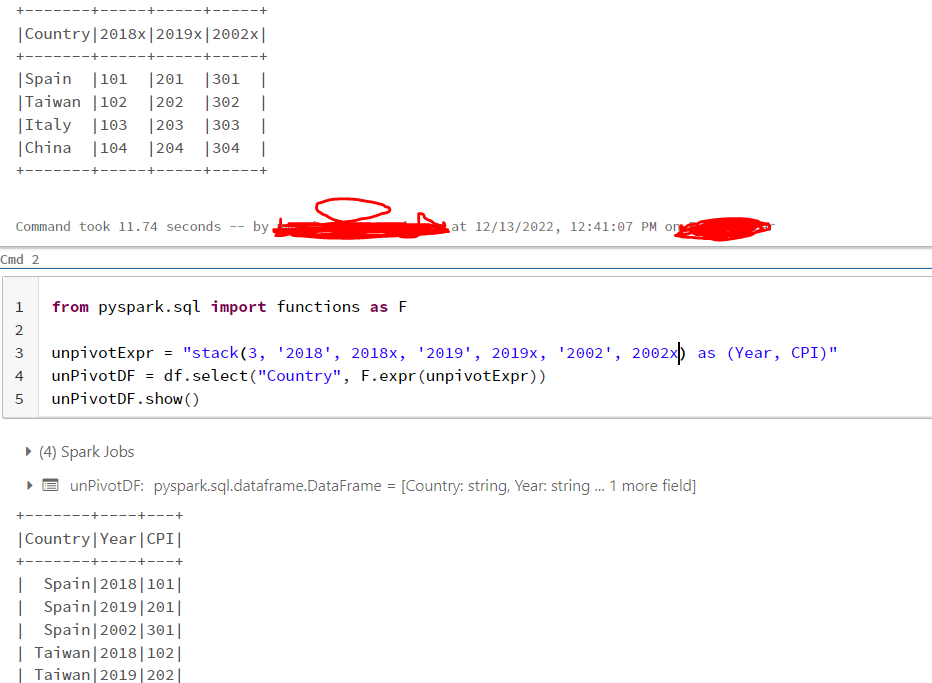
Below is the code I have tried:
from pyspark.sql import functions as F
unpivotExpr = "stack(3, '2018', 2018, '2019', 2019, '2020', 2020) as (Year, CPI)"
unPivotDF = df.select("Country", F.expr(unpivotExpr))
unPivotDF.show()And the results:

Any idea to solve this issue?


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2022 11:18 PM
Hi @Mohammad Saber
The issue is because the column name is similar to a literal value and it is taking that constant value for all the keys provided.
To avoid this you can give more proper column names like below.

Hope this helps...
Cheers
Uma Mahesh D
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-12-2022 11:18 PM
Hi @Mohammad Saber
The issue is because the column name is similar to a literal value and it is taking that constant value for all the keys provided.
To avoid this you can give more proper column names like below.
Hope this helps...
Cheers
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-12-2023 04:56 AM
on a another dummie example i can't reproduce this error, is there an explanation as to why this happens?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-08-2023 12:32 AM
If i have columns names as below how can i get data
unpivottest = "stack(2,'Turnover (Sas m)',Turnover (Sas m),'abc %', abc %) as (kpi_name, kpi_value)"
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2024 05:40 PM
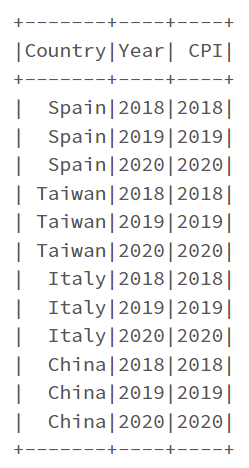
You can also use backticks around the column names that would otherwise be recognised as numbers.
from pyspark.sql import functions as F
unpivotExpr = "stack(3, '2018', `2018`, '2019', `2019`, '2020', `2020`) as (Year, CPI)"
unPivotDF = df.select("Country", F.expr(unpivotExpr))
unPivotDF.show()
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- AnalysisException: [UNRESOLVED_ROUTINE] Cannot resolve routine `=` in Data Engineering
- Free Edition CrossValidator not working because of internal caching in Machine Learning
- PySpark AnalysisException: Ambiguous reference to field t when parsing nested JSON in Data Engineering
- foreachPartition in Data Engineering