Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Window function using last/last_value with PAR...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 10:46 AM
Hi, I'm wondering if this is the expected behavior when using last or last_value in a window function? I've written a query like this:
select
col1,
col2,
last_value(col2) over (partition by col1 order by col2) as column2_last
from values
(1, 10), (1, 11), (1, 12),
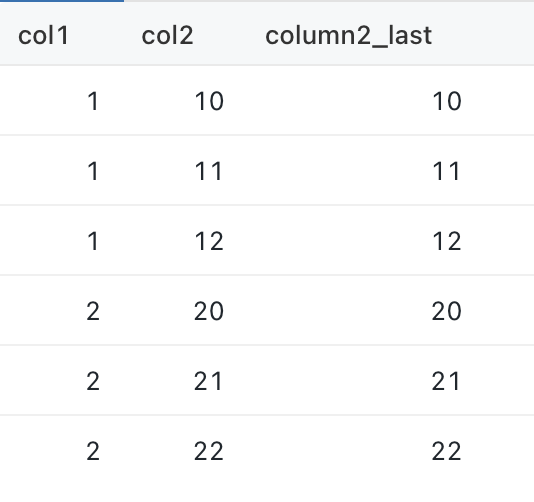
(2, 20), (2, 21), (2, 22);In Snowflake I get the following results. The behavior feels right, since we're partitioning by col1 and ordering by col2 (https://docs.snowflake.com/en/sql-reference/functions/last_value.html).

In Databricks, I get:

Any insight into this behavior would be very helpful. Also, I'm curious why last and last_value are synonyms? https://docs.databricks.com/sql/language-manual/functions/last.html
Thanks!
Labels:
- Labels:
-
Databricks SQL
-
Spark sql
-
SQL Endpoint


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-19-2021 08:38 AM
@Alexis Johnson - Here is where you can open a support ticket:
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 12:44 PM
yes indeed it looks like a bug with LAST_VALUE,
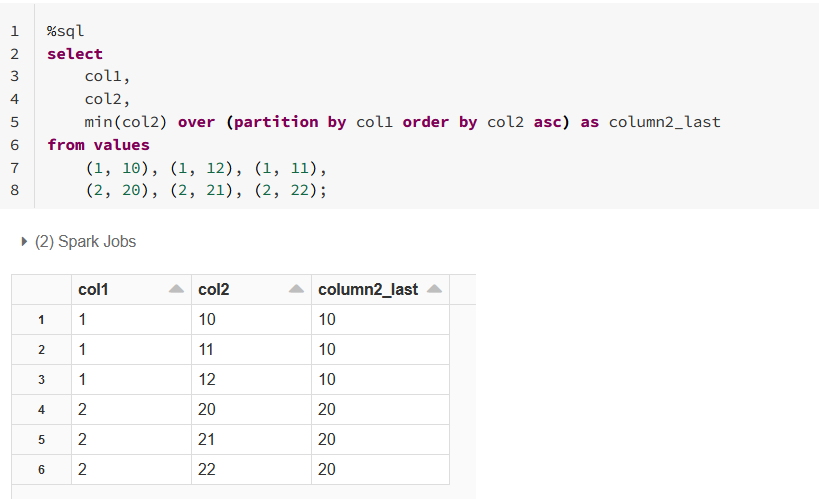
Min gives correct results:

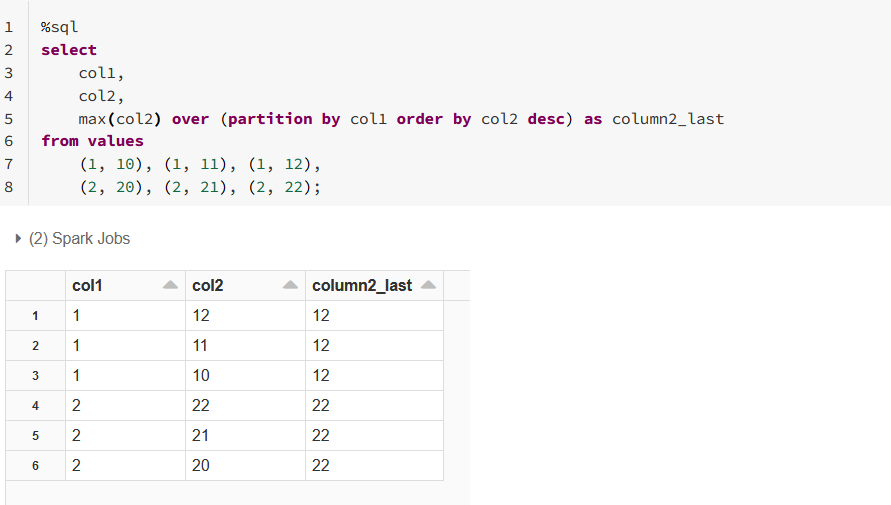
Max hmm only when desc is specified (shouldn't affect as max is max but only with descending sorting it works as should be):

for last_value is exactly like on your example (so nothing helps - I tried many ways).
@Kaniz Fatma maybe someone from inside databricks could look at it
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 12:47 PM
Agreed. Interesting find that `max` behaves funny when `desc` isn't specified.
I'd also note that `first_value` yields the correct result.
@Kaniz Fatma Is there a process for filing bugs in Databricks? It'd be great to get this fixed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-19-2021 08:38 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 12:48 PM
Thank you for your help, @Hubert Dudek !
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-12-2023 01:00 PM
For those stumbling across this; it seems LAST_VALUE emulates the same functionality as it does in SQL Server which does not, in most people's minds, have a proper row/range frame for the window. You can adjust it with the below syntax.
I understand last_value emulating what is in my mind a mistake from sql_server but I don't understand why last() (an alias for last_value) has to use the same window row range.

SELECT
col1
, col2
, LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2 ASC) as column2_last
, LAST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2 ASC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as column2_last_unbound
, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2 ASC) as column2_first
, FIRST_VALUE(col2) OVER (PARTITION BY col1 ORDER BY col2 DESC) as column2_first_reversed
FROM values
(1,10), (1,12), (1,11),
(2,20), (2,21), (2,22);
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- How execute SET spark.sql.sources.partitionOverwriteMode = dynamic; in SQL Stored procedures in Data Engineering
- Lakeflow SDP partition error in Data Engineering
- VNet Data Gateway unable to connect to Azure Databricks Serverless SQL via Private Endpoint in Administration & Architecture
- Data in Unity Catalog that can't be previewed in Data Engineering
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering