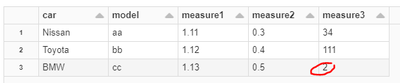
This must be trivial, but I must have missed something.I have a dataframe (test1) and want to round all the columns listed in list of columns (col_list)here is the code I am running:col_list = ['measure1', 'measure2', 'measure3']
for i in col_list:...
Hi, in line with my question about optimize, this is the next step, with a retention of 7 days I could execute vacuum on all tables once a week, is this a recommended procedure?How can I know if I'll be getting any benefit from vacuum, without DRY RU...
Ideally 7 days is recommended, but discuss with data stakeholders to identify what's suitable? 7/14/28 days. To use VACCUM, first run some analytics on behaviour of your data.Identify % of operations that perform updates and deletes vs insert operati...
Hi all,I am establishing a connection to databricks from Collibra through Spark driver. Collibra expects these details for the connection (for token based):personal access token (pat)server/workspace namehttpPathUpon successful connection, Collibra d...
I have upgraded the Azure Databricks from 6.4 to 9.1 which enable me to use Spark3. As far as I know, the Hive version has to be upgraded to 2.3.7 as well as discussed in: https://community.databricks.com/s/question/0D53f00001HKHy2CAH/how-to-upgrade-...
I'm asking about Datatricks version 9.1. I've follow the url given (https://docs.microsoft.com/en-us/azure/databricks/data/metastores/external-hive-metastore). Do you mind letting me know where in the table is mentioning the supported hive version fo...
In workspace one folder I have around 100+ pyspark scripts, all these scripts need to be compiled before running the main program. In order to compile all these files, we are using the %run magic command like %run ../prod/netSales. Since we have 100+...
Problem is that you can list all files in workspace only via API call and than you can run every one of them using:dbutils.notebook.run()This is the script to list files from workspace (probably you need to add some filterning):import requests
ctx = ...
We created Python package (.tar.gz) and kept it under private git.We can able to connect to that git (using PAT) from the Azure databricks notebook.Our requirement is to install that package from .tar.gz file for that notebook"pip install https://USE...
For installing the package using pip you need to package the repo using setup.py. check this link for more details https://packaging.python.org/en/latest/tutorials/packaging-projects/alternatively you can pass the tar.gz using --py-files while submi...
Ignite your senses with distinctive and fm world shop delightful fragrances for your home, Discover scents to set the mood and inspire fragrant memories
Ignite your senses with distinctive and soy wax melts delightful fragrances for your home, Discover scents to set the mood and inspire fragrant memories
Hi, is there any way other than adf monitoring where in automated way we can get notebook level execution details without getting to go to each pipeline and checking
Hii'm using an autoloader with Azure Databricks:df = (spark.readStream.format("cloudFiles") .options(**cloudfile) .load("abfss://dev@std******.dfs.core.windows.net/**/*****)) at my target checkpointLocation folder there are some files and subdirs...
@Aman Sehgal - My name is Piper, and I'm one of the moderators for Databricks. I wanted to jump in real quick to thank you for being so generous with your knowledge.
Currently, I am running a cluster that is set to terminate after 60 minutes of inactivity. However, in one of my notebooks, one of the cells is still running. How can I prevent this from happening, if want my notebook to run overnight without monito...
If a cell is already running ( I assume it's a streaming operation), then I think it doesn't mean that the cluster is inactive. The cluster should be running if a cell is running on it.On the other hand, if you want to keep running your clusters for ...
One of the source systems generates from time to time a parquet file which is only 220kb in size.But reading it fails."java.io.IOException: Could not read or convert schema for file: 1-2022-00-51-56.parquetCaused by: org.apache.spark.sql.AnalysisExce...
@nafri A - Howdy! My name is Piper, and I'm a community moderator for Databricks. Would you be happy to mark @Hubert Dudek's answer as best if it solved the problem? That will help other members find the answer more quickly. Thanks
Hi, the process is like traditional software development practices.Docs to refer: https://docs.microsoft.com/en-us/azure/databricks/dev-tools/ci-cd/ci-cd-azure-devops#unit-tests-in-azure-databricks-notebooksAzure DevOps Best Practices: https://docs.m...
Hi, I am getting the following error:com.databricks.sql.io.FileReadException: Error while reading file wasbs:REDACTED_LOCAL_PART@blobStorageName.blob.core.windows.net/cook/processYear=2021/processMonth=12/processDay=30/processHour=18/part-00003-tid-4...
yes, I can read from notebook with DBR 6.4, when I specify this path: wasbs:REDACTED_LOCAL_PART@blobStorageName.blob.core.windows.net/cook/processYear=2021/processMonth=12/processDay=30/processHour=18but the same using DBR 6.4 from spark-submit, it f...
I have installed Databricks-Connect (9.1 LTS). I am able to send queries to the cluster. However, when the query includes a call to the 'table_changes' function that is a part of Change Data Feed, I get the following error:AnalysisException("could ...
Hi @Kaniz Fatma , the table_changes function is an internal Databricks function used in Change Data Feed (CDF).Please refer to the article below. It discusses the table_changes function.https://docs.databricks.com/delta/delta-change-data-feed.html