- 3404 Views
- 2 replies
- 0 kudos
Seeking Assistance with Dynamic %run Command Path
Hello Databricks Community Team,I trust this message finds you well. I am currently facing an issue while attempting to utilize a dynamic path with the %run command to execute a notebook called from another folder. I have tested the following approac...
- 3404 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi, If your config file is in the databricks file system then you should add dbfs:/Ex: f"dbfs:/Users/.../blob_conf/{conf_file}"
- 0 kudos
- 1055 Views
- 0 replies
- 0 kudos
How to Migrate specific notebooks from one Azure Repo to another Azure Repo
Team,I need to migrate only specific notebooks which has changes committed to be pulled from one repo to another repoEnvironment/Repo Setup:Master -> Dev -> Feature Branch -> Developer commits the code in Feature Branch -> Dev has the changes from D...
- 1055 Views
- 0 replies
- 0 kudos
- 1501 Views
- 1 replies
- 0 kudos
Databricks JDBC Driver 2.6.36 includes dependencies in pom.properties with vulnerabilities
Starting from Databricks JDBC Driver 2.6.36 we've got Trivy security report with vulnerabilities from pom.properties.2.6.36 adds org.apache.commons.commons-compress:1.20 and ch.qos.logback.logback-classic:1.2.3.2.6.34 doesn't include such dependencie...
- 1501 Views
- 1 replies
- 0 kudos
- 0 kudos
I didn't find where to open an issue (GitHub or Jira). Please, let me know if I need to report it somewhere else.
- 0 kudos
- 8184 Views
- 2 replies
- 2 kudos
UC Volumes - Cannot access the UC Volume path from this location. Path was
Hi, I'm trying out the new Volumes preview.I'm using external locations for everything so far. I have my storage credential, and external locations created and tested. I created a catalog, schema and in that schema a volume. In the new data browser o...
- 8184 Views
- 2 replies
- 2 kudos
- 2 kudos
Hope this helps, but this issue could be caused by the Cluster being in no-isolation shared and not in single-user or shared, both compatible with Unity Catalog
- 2 kudos
- 1543 Views
- 0 replies
- 0 kudos
Creating external location is Failing because of cross plane request
While creating Unity Catalog external location from Data Bricks UI or from a notebook using "CREATE EXTERNAL LOCATION location_name .." a connection is being made and rejected from control plane to the S3 data bucket in a PrivateLink enabled environm...
- 1543 Views
- 0 replies
- 0 kudos
- 1296 Views
- 0 replies
- 0 kudos
Source to Bronze Organization + Partition
Hi there, I hope I have what is effectively a simple question. I'd like to ask for a bit on guidance if I am structuring my source-to-bronze auto loader data properly. Here's what I have currently:/adls_storage/<data_source_name>/<category>/autoloade...
- 1296 Views
- 0 replies
- 0 kudos
- 5657 Views
- 2 replies
- 0 kudos
Install python package from private repo [CodeArtifact]
As part of my MLOps stack, I have developed a few packages which are the published to a private AWS CodeArtifact repo. How can I connect the AWS CodeArtifact repo to databricks? I want to be able to add these packages to the requirements.txt of a mod...
- 5657 Views
- 2 replies
- 0 kudos
- 0 kudos
One way to do it is to run this line before installing the dependencies:pip config set site.index-url https://aws:$CODEARTIFACT_AUTH_TOKEN@my_domain-111122223333.d.codeartifact.region.amazonaws.com/pypi/my_repo/simple/But can we add this in MLFlow?
- 0 kudos
- 1430 Views
- 0 replies
- 0 kudos
DLT pipeline access external location with abfss protocol was failed
Dear Databricks Community Members:The symptom: The DLT pipeline was failed with the error message: Failure to initialize configuration for storage account storageaccount.dfs.core.windows.net: Invalid configuration value detected for fs.azure.account...
- 1430 Views
- 0 replies
- 0 kudos
- 2941 Views
- 1 replies
- 0 kudos
SQL Warehouse cluster is always running when configure metabase conneciton
I encountered an issue while using the Metabase JDBC driver to connect to Databricks SQL Warehouse: I noticed that the SQL Warehouse cluster is always running and never stops automatically. Every few seconds, a SELECT 1 query log appears, which I sus...
- 2941 Views
- 1 replies
- 0 kudos
- 0 kudos
Will try to remove "preferredTestQuery" or add "idleConnectionTestPeriod" to avoid keep send select 1 query.
- 0 kudos
- 2461 Views
- 0 replies
- 0 kudos
Is the Databricks Community Edition still available?
Hello,I am a professor of IT in the Price College of Business at The University of Oklahoma. In the past, I have used the Databricks Community Edition to demonstrate the principles of building and maintaining a data warehouse. This spring semester ...
- 2461 Views
- 0 replies
- 0 kudos
- 2132 Views
- 2 replies
- 1 kudos
utils.add_libraries_to_model creates a duplicated model
Hello,When I call this function,mlflow.models.utils.add_libraries_to_model(MODEL_URI)It register a new model into the Model Registry. Is it possible to do the same but without registering a new model?Thanks,
- 2132 Views
- 2 replies
- 1 kudos
- 1 kudos
I ended up publishing the library to AWS CodeArtifact repository. Now, how can I tell MLFlow to use AWS CodeArtifact private repository instead of PyPi?
- 1 kudos
- 3465 Views
- 2 replies
- 0 kudos
Auto Loader Use Case Question - Centralized Dropzone to Bronze?
Good day,I am trying to use Auto Loader (potentially extending into DLT in the future) to easily pull data coming from an external system (currently located in a single location) and organize it and load it respectively. I am struggling quite a bit a...
- 3465 Views
- 2 replies
- 0 kudos
- 0 kudos
Quick follow-up on this @Retired_mod (or to anyone else in the Databricks multi-verse who is able to help clarify this case).I understand that the proposed solution would work for a "one-to-one" case where many files are landing in a specific dbfs pa...
- 0 kudos
- 3883 Views
- 3 replies
- 0 kudos
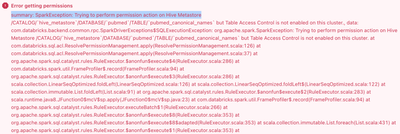
Fail to write large dataframe
Hi all, we have a issue while trying to write a quite large data frame, close to 35 million records. We try to write it as parquet and also table and none work. But writing a small chink (10k records) is working. Basically we have some text on which ...
- 3883 Views
- 3 replies
- 0 kudos
- 0 kudos
That could work, but you will have to create a UDF.Check this SO topic for more info
- 0 kudos
- 2254 Views
- 0 replies
- 2 kudos
Exciting Update! 🚀 Check out our fresh Community upgrades
Hello Community Members, We are thrilled to announce a fresh look for our Community platform! Get ready for an enhanced user experience with our brand-new UI changes. Our team has worked diligently to bring you a more intuitive and visually appealing...

- 2254 Views
- 0 replies
- 2 kudos
- 5259 Views
- 2 replies
- 0 kudos
ClassCastException when attempting to timetravel (databricks-connect)
Hi all,Using databricks-connect 11.3.19, I get an "java.lang.ClassCastException" when attempting to timetravel. The exact same statement works fine when executed in the databricks GUI directly. Any ideas on what's going on? Is this a known limitation...
- 5259 Views
- 2 replies
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |