- 1538 Views
- 2 replies
- 1 kudos
Asinine bad word detection
Are you kidding me here--I couldn't post this reply because (see arrows because I can't say the words)? I've run afoul of this several times before, bad word detection was a solved problem in the 1990s and there is even a term for errors like this--...

- 1538 Views
- 2 replies
- 1 kudos
- 1 kudos
Hello @Rjdudley! Thank you for bringing this to our attention. We understand how frustrating it can be to have your message incorrectly flagged, especially when you're contributing meaningfully. While our filters are in place to maintain a safe space...
- 1 kudos
- 2173 Views
- 5 replies
- 1 kudos
AI/BI Dashboard - Hide Column in Table Visualization, but not in exported data
How can I hide specific colum from a table visualization, but not in the exported data.I have over 200 columns in my query result and the ui freeze while I want to show it in a table visualization. So I want to hide specific columns, but if I export ...
- 2173 Views
- 5 replies
- 1 kudos
- 3568 Views
- 3 replies
- 0 kudos
DAB not updating zone_id when redeployed
Hey folks,Facing an issue with zone_id not getting overridden when redeploying the DAB template to Databricks workspace.The Databricks job is already deployed and has "ap-south-1a" zone_id. I wanted to make it "auto" so, I have made the changes to th...

- 3568 Views
- 3 replies
- 0 kudos
- 0 kudos
Hello. I had similar issue when using DAB in CI/CD but able to fixed the issue.
- 0 kudos
- 2829 Views
- 2 replies
- 1 kudos
Resolved! DBX Community Pending Answers
Hi there, in the past I've posted questions in this community and I would consistently get responses back in a very reasonable time frame. Typically I think most of my posts have an initial response back within 1-2 days, or just a few days (I don't t...
- 2829 Views
- 2 replies
- 1 kudos
- 1 kudos
Thank you for clarifying. I know some questions may be a bit more technical, but I hope I get some feedback/suggestions, particularly to my UMF Best Practice question!
- 1 kudos
- 1501 Views
- 1 replies
- 1 kudos
Resolved! Is there a way to iterate over a combination of parameters using a "for each" task?
Hi,I have a notebook with two input widgets set up ("current_month" and "current_year") that the notebook grabs values from and uses for processing. I want to be able to provide a list of input values in the "for each" task where each value is actual...
- 1501 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi there @sys08001 , yup it is possible you can pass the input values for the for_each task in json format Somewhat like this[ { "tableName": "product_2", "id": "1", "names": "John Doe", "created_at": "2025-02-22T10:00:00.000Z" },...
- 1 kudos
- 2939 Views
- 2 replies
- 0 kudos
Azure Databricks - Databricks AI Assistant missing on Azure Student Subscription?
I am going through a course learning Azure Databricks and I had created a new Azure Databricks Workspace. I am the owner of the subscription and created everything so I assume I should have full admin rights.The following is my set up-Azure Student S...
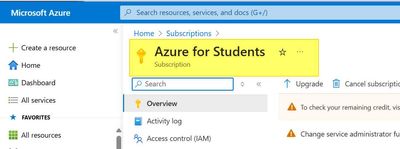
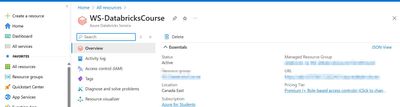

- 2939 Views
- 2 replies
- 0 kudos
- 0 kudos
@rodneyc8063 According to Azure’s documentation, it states:Tip:Admins: If you’re unable to enable Databricks Assistant, you might need to disable the "Enforce data processing within workspace Geography for Designated Services" setting. See “For an ac...
- 0 kudos
- 1232 Views
- 1 replies
- 0 kudos
Resolved! Access to Demo: Databricks Workspace Walkthrough
Hi,How can I have access to Databricks Workspace Walkthrough hands-on (guidance) in free courses to practice?Thanks
- 1232 Views
- 1 replies
- 0 kudos
- 0 kudos
Hello @MariaSaa! The free Databricks courses don’t include access to hands-on labs. Practical lab environments are currently available only through paid training options or with an Academy Labs subscription.
- 0 kudos
- 2020 Views
- 3 replies
- 0 kudos
Allow an external user to query SQL table in Databricks
I have a delta table sitting in a schema inside a catalog. How do I allow an external user to query the SQL table via an API? I scrolled through documentation and a lot of resources but it's all so confusing. The AI assistant is way too naive. Can so...
- 2020 Views
- 3 replies
- 0 kudos
- 0 kudos
We will need a bit more information. Are you asking: A) how an external user who is skilled at code can invoke a sql query via api. or B) how a non-technical external user can run a query via a simple ui?If it's option A: then you can create a person...
- 0 kudos
- 4652 Views
- 1 replies
- 0 kudos
Install bundle built artifact as notebook-scoped library
We are having a hard time finding an intuitive way of using the artifacts we build and deploy with databricks bundle deploy notebook-scoped.Desired result:Having internal artifacts be available notebook-scoped for jobs by configorHaving an easier way...
- 4652 Views
- 1 replies
- 0 kudos
- 0 kudos
We were not able to find a clean solution for this, so what we ended up doing is referencing the common lib like this in every notebook it is needed.%pip install ../../../artifacts/.internal/common-0.1-py3-none-any.whl
- 0 kudos
- 1765 Views
- 2 replies
- 0 kudos
Autoloader delete action on AWS S3
Hi folks, I have been using autoloader to ingest files from S3 bucket.I tried to add trigger on the workflows to schedule the job to run every 10 minutes. However, recently I'm facing an error that makes the jobs keep failing after a few success run....
- 1765 Views
- 2 replies
- 0 kudos
- 0 kudos
There might be few possibilities : can you check this items ? 1. Is there any s3 bucket policy configured like within timeframe file deletion or file validity configured ? 2. check the autload configuration once again to validate the option of cleanu...
- 0 kudos
- 1251 Views
- 0 replies
- 0 kudos
Time Series Book by a Senior Solutions Architect
I recently worked with one of the Senior Solutions Architects, Yoni Ramaswami (https://www.linkedin.com/in/yoni-r/) with Databricks on a new book" Time Series Analysis with Spark" Key FeaturesQuickly get started with your first models and explore the...
- 1251 Views
- 0 replies
- 0 kudos
- 1838 Views
- 1 replies
- 0 kudos
Unable pass array of tables names from for each and send it task param
sending below array list from for each task["mv_t005u","mv_t005t","mv_t880"] In the task , iam reading value as key :mv_namevalue :{{input}} but in note book i am getting below errorNote book code:%sqlREFRESH MATERIALIZED VIEW nonprod_emea.silver_loc...
- 1838 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @sivaram_mandepu,In the first screenshot, the input must be a valid JSON array, so instead of using {{mvname: "mv_......"}}, update it to [ { "mvname": "mv_......." } ].In the third screenshot, the SQL error likely comes from a newline or extra sp...
- 0 kudos
- 3446 Views
- 3 replies
- 0 kudos
Resolved! Init Scripts Error When Deploying a Delta Live Table Pipeline with Databricks Asset Bundles
Hello everyone,Let me give you some context. I am trying to deploy a Delta Live Table pipeline using Databricks Asset Bundles, which requires a private library hosted in Azure DevOps.As far as I understand, this can be resolved in three ways:Installi...
- 3446 Views
- 3 replies
- 0 kudos
- 0 kudos
I detected the error; it was due to the path defined in the bundle where the init script was located.I'm closing the post.
- 0 kudos
- 10037 Views
- 2 replies
- 0 kudos
FAILED_READ_FILE.NO_HINT error
We read data from csv in the volume into the table using COPY INTO. The first 200 files were added without problems, but now we are no longer able to add any new data to the table and the error is FAILED_READ_FILE.NO_HINT. The CSV format is always th...
- 10037 Views
- 2 replies
- 0 kudos
- 0 kudos
I came across the same issue and the file causing problems needed the csv option "multiline" set back to the default "false" to read the file:df = spark.read.option("multiline", "false").csv("CSV_PATH") If this approach eliminates the error above, I ...
- 0 kudos
- 1591 Views
- 2 replies
- 1 kudos
webterm unminimize command missing?
A lot of commands in webterm basically tell you a bunch of stuff has been not installed or minimized and you should run `unminimize` for a full interactive experience.This used to work great. However, I just tried it and the unminimize command is no...
- 1591 Views
- 2 replies
- 1 kudos
- 1 kudos
1. no such command exists2. probably not - we tend to dump old clusters and create new ones (for new sets of data) fairly frequently and (I think) use the latest stable DBR when creating3. I did find a workaround. unminimize has been added to apt so...
- 1 kudos
-
.CSV
1 -
50% Certification Voucher
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |