- 12481 Views
- 3 replies
- 8 kudos
Resolved! Find and replace
Hi,Is there a "Find and replace" option to edit SQL code? I am not referring to the "replace" function but something similar to Control + shift + F in Snowflake or Control + F in MS Excel.
- 12481 Views
- 3 replies
- 8 kudos
- 8 kudos
is there an option to find-replace just within a cell instead of entire notebook?
- 8 kudos
- 7446 Views
- 7 replies
- 0 kudos
Resolved! Unable to start browser for databricks certification
Hello, I have registered for databricks certified data engineering associate exam. One of the requirements to give the exam is The exam is set for Sunday 6th October, 2024 but the browser installation (psi secure bridge browser) does not work. .Reac...

- 7446 Views
- 7 replies
- 0 kudos
- 0 kudos
Hi @hetrasol ,I'm a Windows user. After installation, I just got the Lockdown Browser OEM instead of the PSI browser, as you mentioned above. Can you help to instruct again on how to install these browsers
- 0 kudos
- 3296 Views
- 2 replies
- 0 kudos
Spark Remote error when connecting to cluster
Hi, I am using the latest version of pyspark and I am trying to connect to a remote cluster with runtime 13.3.My doubts are:- Do i need databricks unity catalog enabled?- My cluster is already in a Shared policy in Access Mode, so what other configur...
- 3296 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi, Is your workspace is already unity catalog enabled? Also, did you go through the considerations for enabling workspace for unity catalog? https://docs.databricks.com/en/data-governance/unity-catalog/enable-workspaces.html#considerations-before-yo...
- 0 kudos
- 5305 Views
- 2 replies
- 2 kudos
Resolved! Cannot install wheel from Workspace in DLT
Hi all. I am no longer able to install my custom wheel in my DLT pipeline. No matter what configuration I try I cannot get it to work: parameterized or just hard-coding the path to the wheel. If I run the hard-coded cell with an all-purpose cluster t...
- 5305 Views
- 2 replies
- 2 kudos
- 2 kudos
I managed to fix the issue. The problem was that my wheel was built for Databricks Runtime 14.3 LTS and I was using the PREVIEW channel rather than the CURRENT channel. At time of writing:CURRENT(default): Databricks Runtime 14.1 --> Python: 3.10.12P...
- 2 kudos
- 9340 Views
- 5 replies
- 1 kudos
How to get data from Splunk on daily basis?
I am finding the ways to get the data to Databricks from Splunk (similar to other data sources like S3, Kafka, etc.,). I have received a suggestion to use the Databricks add-on to get/put the data from/to Splunk. To pull the data from Databricks to S...
- 9340 Views
- 5 replies
- 1 kudos
- 1 kudos
@Arch_dbxlearner - could you please follow the post for more details. https://community.databricks.com/t5/data-engineering/does-databricks-integrate-with-splunk-what-are-some-ways-to-send/td-p/22048
- 1 kudos
- 2049 Views
- 1 replies
- 0 kudos
Late file arrivals - Autoloader
Hi All,I have a situation where I'm receiving various CSV files in a storage location.The issue I'm facing is that I'm using Databricks Autoloader, but some files might arrive later than expected. In this case, we need to notify the relevant team ab...
- 2049 Views
- 1 replies
- 0 kudos
- 0 kudos
Well, Autoloader could work nicely with the notification event for arriving files. You could probably specify a window duration for your "on-time" arrivels and that could be your base check for on time. As files arrive they go to their window and whe...
- 0 kudos
- 1371 Views
- 1 replies
- 0 kudos
duplicate data published in kafka offset
we have 25k data which are publishing by batch of 5k.we are numbering the records based on row_number window function and creating batch using this.we have observed that some records like 10-20 records are getting published duplicated in 2 offset. ca...
- 1371 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @dipali_globant,duplicate data in Kafka can arise in a batch processing scenario for a few reasons here’s an example of ensuring unique and consistent row numbering: from pyspark.sql import Window from pyspark.sql.functions import row_number wind...
- 0 kudos
- 4964 Views
- 1 replies
- 0 kudos
How do i find total number of input tokens to genie ?
I am calculating usage analytics for my work, where they use genie.I have given the following for my genie as definition:(1) instructions (2) example SQL queries (3) Within catalog, i went to those relevant table schema and added comments, descriptio...
- 4964 Views
- 1 replies
- 0 kudos
- 0 kudos
Or is there any set of tables and functions to determine the number of input and output tokens per query?
- 0 kudos
- 1607 Views
- 1 replies
- 0 kudos
Sharing Opportunities with Databricks
Hi everyone,I would like to talk to someone that could set up a process of deals sharing with Databricks following the GDPR.Thanks,Carol.
- 1607 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi,Can you pls share some more details on what you are looking for ?If you are trying to share the data to/from Databricks, you can use Delta sharing , Clean rooms option - these provide data sharing options with strong security & governance.or if yo...
- 0 kudos
- 1987 Views
- 1 replies
- 0 kudos
Databricks Destiny with Fivetrans best practices
Hello! we are trying to use Fivetran for ingesting different sources into the data lake so we will have multiple connectors. We would like to know what are the recommendations when selecting the SQL warehouses. Since the new serverless SQL warehouses...
- 1987 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi,To understand about the Databricks SQL Serverless cost, you can see here - https://www.databricks.com/product/pricing/databricks-sqlIn terms of comparison, Databricks is said to be the most cost efficient & high performant in the market amongst it...
- 0 kudos
- 1427 Views
- 1 replies
- 0 kudos
code vulnerabilities, code smells, and bugs
Hi Team, is there a way in Databricks to check for code vulnerabilities, code smells, and bugs?Note :Databricks native functionality only
- 1427 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi,As far as I am aware, for security scanning/monitoring at Databricks account level, we have belowSAT - https://github.com/databricks-industry-solutions/security-analysis-toolhttps://www.databricks.com/trust/trusthttps://learn.microsoft.com/en-us/a...
- 0 kudos
- 3225 Views
- 7 replies
- 0 kudos
Cluster logs folder
Hi, I can't see to find the cluster_logs folder, anyone that can help me find where the cluster logs are stored? Best regards

- 3225 Views
- 7 replies
- 0 kudos
- 0 kudos
Thank you for the help! I have enabled predictive optimization for unity catalog, thinking it would automatically preform VACCUM on the tables i have in my delta lake. With that in mind, I assumed VACCUM wouldn't require further attention.Would it be...
- 0 kudos
- 2440 Views
- 1 replies
- 0 kudos
Can we share Delta table data with Salesforce using OData?
Hello!I'm seeking recommendations for streaming on-demand data from Databricks Delta tables to Salesforce. Is OData a viable choice?Thanks.
- 2440 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @ChristopherQ1, Salesforce has released a zero-copy connection that relies on the SQL Warehouse to ingest data when needed. I suggest you consider that instead of OData. Matthew
- 0 kudos
- 1270 Views
- 0 replies
- 0 kudos
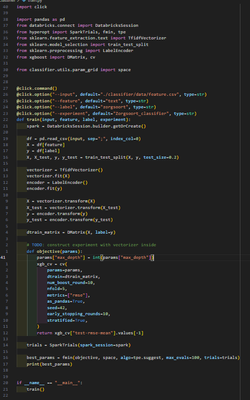
Paralellizing XGBoost Hyperopt run using Databricks
Hi there!I am implementing a classifier for classifying documents to their respective healthcare type.My current setup implements the regular XGBClassifier of which the hyperparameters are to be tuned on my dataset, which is done using Hyperopt. Base...
- 1270 Views
- 0 replies
- 0 kudos
- 1776 Views
- 1 replies
- 0 kudos
CDC for Unstructured data
Hi All,how we can handle CDC for unstructured data in Databricks. What are some best practices we should follow to make this work effectively?Regards,Phani
- 1776 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @Phani1 ,Handling CDC for unstructured data—such as audio, images, or video files—in Databricks involves efficiently detecting and processing changes to these files as they occur.Here's how you can approach this:Use Databricks Autoloader: Autoload...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
AIBI
1 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Course
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Dashboards
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
Grafana
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
ISVPartnership
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
link for labs
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
plugins
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |