- 3168 Views
- 2 replies
- 1 kudos
Resolved! I cannot curl a URL in a notebook
I tried to curl the following url in a notebook %sh curl https://staging-api.newrelic.com/graphql -v But I got the following error message { [5 bytes data] * TLSv1.2 (OUT), TLS header, Supplemental data (23): } [5 bytes data] * TLSv1.2 (IN), TLS he...
- 3168 Views
- 2 replies
- 1 kudos
- 6458 Views
- 7 replies
- 2 kudos
Trying to connect datrabricks with Mulesoft
Hi im trying to connect to Databricks using the mulesoft database connector, using databricks JDBC, I already connect using personal access token, but i need to use OAuth2 M2M, and only return a error 500151 Invalid local Address:org.mule.runtime.api...
- 6458 Views
- 7 replies
- 2 kudos
- 2 kudos
Assuming you followed the guide (https://learn.microsoft.com/en-us/azure/databricks/integrations/jdbc/authentication#--oauth-machine-to-machine-m2m-authentication), is it possible your workspace uses private link?because that won't work.Also: only Da...
- 2 kudos
- 979 Views
- 0 replies
- 0 kudos
AnalysisException: is not a Delta table. but that table is Delta table
When running a Databricks notebook,an error occurs stating that SOME_TABLE is not a Delta table.However, after executing the describe detail command and checking the format,the table is shown as Delta.Without taking any specific actions, re-running ...
- 979 Views
- 0 replies
- 0 kudos
- 1548 Views
- 0 replies
- 0 kudos
Databricks Connect Vscode. Cannot find package installed on cluster
I am using Databricks Connect v2 to connect to a UC enabled cluster. I have a package I have made and installed in a wheel file on the cluster. When using vscode to import the package and use it I get a module not found error when running cell by ce...
- 1548 Views
- 0 replies
- 0 kudos
- 1972 Views
- 0 replies
- 0 kudos
Unable to move/merge a account from customer-academy to partner-academy
Hi,Last year I created a customer-academy account for learning purpose.New I need to move/merge my account to partner-academy using my company mail. The goal is to only have a partner-academy account where my primary mail will be my private email and...
- 1972 Views
- 0 replies
- 0 kudos
- 3106 Views
- 2 replies
- 1 kudos
Resolved! UCX code migration
Hello Databricks Community,I’m currently in the process of migrating our codebase to Unity Catalog using UCX and would appreciate some advice. Our environment has a mix of jobs and tables running on both Unity Catalog and hive_metastore.After running...
- 3106 Views
- 2 replies
- 1 kudos
- 1 kudos
Hi @Reply_Domenico, How are you dong today?To filter jobs, try adjusting the UCX assessment query or use a script to exclude jobs already on Unity Catalog. Unfortunately, UCX doesn't yet have specific commands for automating code migration to Unity C...
- 1 kudos
- 4063 Views
- 2 replies
- 0 kudos
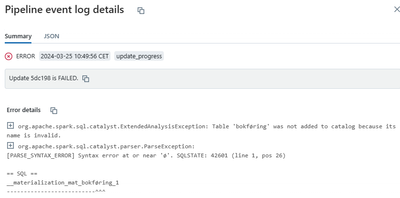
UTF-8 troubles in DLT
Issues with UTF-8 in DLTI am having issues with UTF-8 in DLT:I have tried to set the spark config on the cluster running the DLT pipeline: I have fixed this with normal compute under advanced settings like this:spark.conf.set("spark.driver.extraJava...

- 4063 Views
- 2 replies
- 0 kudos
- 0 kudos
@Retired_mod Hi, DLT has updated its runtime but I get a different error now:this is my code:
- 0 kudos
- 1516 Views
- 1 replies
- 1 kudos
Assistance Required for Enabling Unity Catalog in Databricks Workspace
Hi,I hope this message finds you well.I am reaching out regarding a concern with Databricks Administrator privileges. I have an Azure subscription and I use Azure Databricks for my tutorials, but I currently do not have Global Administrator access, w...
- 1516 Views
- 1 replies
- 1 kudos
- 1 kudos
Hi @Meghana_Vasavad ,During initial setup of unity catalog you need to find a person with global administrator role of Entra ID tenant. It's one time action, because then he can give necessary permission to manage catalog to your account, or even bet...
- 1 kudos
- 11160 Views
- 6 replies
- 0 kudos
Asset Bundles git branch per target
Hi,I am migrating from dbx to Databricks Asset Bundles (DAB) a deployment setup where I have specific parameters per environment. This was working well with dbx, and I am trying now to define those parameters defining targets (3 targets : dev, uat, p...
- 11160 Views
- 6 replies
- 0 kudos
- 0 kudos
Something must have changed in the meantime on Databricks side. I have only updated databricks CLI to 016 and now, using a git / branch under each target deploys this setup, where feature-dab is the branch I want the job to pull sources from, I see t...
- 0 kudos
- 15212 Views
- 1 replies
- 0 kudos
RBAC
Hi Team,can provide you with step-by-step instructions on how to create role-based access and attribute-based access in Databricks.Regards,Phanindra
- 15212 Views
- 1 replies
- 0 kudos
- 7910 Views
- 5 replies
- 0 kudos
Resolved! maxFilesPerTrigger not working while loading data from Unity Catalogue table
Hi,I am using streaming on unity catalogue tables and trying to limit the number of records read in each batch. Here is my code but its not respecting maxFilesPerTrigger, instead reads all available data. (spark.readStream.option("skipChangeCommits",...
- 7910 Views
- 5 replies
- 0 kudos
- 0 kudos
I believe you misunderstand the fundamentals of delta tables. `maxFilesPerTrigger` has nothing to do with how many rows you will process at the same time. And if you really want to control the number of records per file, then you need to adapt the wr...
- 0 kudos
- 3281 Views
- 1 replies
- 1 kudos
Resolved! Serving pay-per-token Chat LLM Model
We have build a chat solution on LLM RAG chat model, but we face an issue when we spin up a service endpoint to host the model.According to the documentation, there should be sevral LLM models available as pay-per-token endpoints, for instance the DB...
- 3281 Views
- 1 replies
- 1 kudos
- 1 kudos
@Henrik The documentation clearly states that it should be available in west europe, but i'm also unable to see DBRX ppt endpoint. I think that it would be best to raise an Azure Support ticket - they should either somehow enable it on your workspace...
- 1 kudos
- 1512 Views
- 1 replies
- 0 kudos
Databricks repo not working with installed python libraries
Hello,I'm trying to use some installed libraries in my cluster.I created a single node cluster with the version Runtime version 14.3 LTS.I also installed libraries like oracledb==2.2.1Then when I try to use python to load this libraries in the worksp...
- 1512 Views
- 1 replies
- 0 kudos
- 0 kudos
Hello Nelson, How are you dong today?Try checking the permissions on your repo folder to ensure your cluster can access it without issues. Use absolute paths when running from your GitHub repo to avoid directory confusion. Reinstall the oracledb libr...
- 0 kudos
- 1473 Views
- 1 replies
- 0 kudos
Concurrent installation of UCX in multiple workspaces
I am trying to install UCX in multiple workspaces concurrently through bash script but facing issue continuously. I have created separate directories for each workspace. I'm facing the below error everytime.Installing UCX in Workspace1Error: lib: cle...
- 1473 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @unity_Catalog, How are you dong today?Try running the UCX installations sequentially to avoid file access conflicts, adding a small delay between each. Ensure each workspace uses a separate installation directory to prevent overlap. You could als...
- 0 kudos
- 2110 Views
- 1 replies
- 0 kudos
Informatica API data retrieval through Datrbicks Workflows or ADF!! Which is better?
The above set of activities took some 4 hours at ADF to explore and design with greater ease of use, connections, monitoring and it could have probably taken 4 days or more using Databrick...




- 2110 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi @rohit_kumar, How are you dong today?To answer to your subject line question, If you're looking for flexibility and integration, Databricks Workflows might be better since it offers native support for complex data transformations and seamless inte...
- 0 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
4 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
1 -
Databricks Apps
1 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks genAI associate
1 -
Databricks JDBC Driver
1 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
Declartive Pipelines
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeBase
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
mosic ai search
1 -
Networking
2 -
Notebook
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Unity Cataloge
1 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 45 | |
| 40 |