- 10171 Views
- 2 replies
- 0 kudos
Create Team Git Repo in Azure Databricks
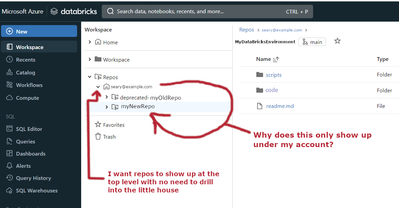
When I attach a Git repo to Databricks, it always puts the repo under my username/domain name:How can I create a "team" repo at the top level, so teammates don't have to drill into my username?
- 10171 Views
- 2 replies
- 0 kudos
- 0 kudos
Hi,Interest of using a repo is to have a dedicated area for each of developers.If you want to have only a folder with the last version of the code, you should a CI/CD pipeline that will package the code and then delivered into a folder inside Workspa...
- 0 kudos
- 12564 Views
- 3 replies
- 1 kudos
Error when setting up OAuth profile for Databricks CLI
Hello.I'm currently trying to migrate a project from dbx to Databricks Asset Bundles. I have successfully created the required profile using U2M authentication with the command```databricks auth login --host <host-name>```I'm able to see the new prof...
- 12564 Views
- 3 replies
- 1 kudos
- 1 kudos
I ran into a similar error just now, and in my case, Pycharm was running some iPython startup scripts each time it opened a console. There was, for some reason, a file at `~/.ipython/profile_default/startup/00-databricks-init-a5acf3baa440a896fa364d18...
- 1 kudos
- 1759 Views
- 1 replies
- 0 kudos
Using Community Edition instance for Customer Academy’s DE Learning Plan
Hi!So I’ve been wondering since I started with the Data Engineering Learning Plan on the Customer Academy, should I go with my Community Edition Databricks, or I should go with creating a premium edition on either a cloud provider or the website.Than...
- 1759 Views
- 1 replies
- 0 kudos
- 0 kudos
Hey, @Kaniz. May I recommend deleting the post if it is not in the right place or changing the forum so I get the proper response?
- 0 kudos
- 2295 Views
- 0 replies
- 0 kudos
DLT to push data instead of a pull
I am relatively new to Databricks, and from my recent experience it appears that every step in a DLT Pipeline, we define each LIVE TABLES (be it streaming or not) to pull data upstream.I have yet to see an implementation where data from upstream woul...
- 2295 Views
- 0 replies
- 0 kudos
- 6503 Views
- 1 replies
- 1 kudos
Resolved! Unable to provide access in unity catalog using SQL commands
I am trying to provide access in unity catalog using the SQL commands.I am following the below documentation:https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog/manage-privileges/It suggests to create SQL commands in belo...



- 6503 Views
- 1 replies
- 1 kudos
- 1 kudos
Try this. For some reason the quotes are crazy when using these commands. GRANT USAGE ON CATALOG `uda_dev` TO `your-group` GRANT SELECT ON SCHEMA uda_dev.default TO `your-group` (without quotes for the schema)
- 1 kudos
- 2466 Views
- 0 replies
- 0 kudos
Issues with Runtime 15.1/15.2Beta in shared access mode
We have been using runtime 14.2, share mode for our computing cluster in Databrick for quite some time. We are now trying to upgrade to python 3.11 for some dependencies mangement, thereby requiring us to use runtime 15.1/15.2 as runtime 14.2 only ...
- 2466 Views
- 0 replies
- 0 kudos
- 1725 Views
- 1 replies
- 0 kudos
Databricks workflow jobs run is taking Double time in EU Region
We have a scheduled job in Databricks workflow, This Job run is taking aroud 5 hours Previously before 1 month it was tasking on 2.5 hours. Can any one tell what may be the reason behind this. Note: There is no change has been made in this period of ...
- 1725 Views
- 1 replies
- 0 kudos
- 0 kudos
You can check if you are using spot instances on your Job Cluster.btw. if you are using Azure West Europe is on very high demand and sometimes it takes time to provision compute.But it should be matter of minutes, not hours.Check maybe if your data v...
- 0 kudos
- 14694 Views
- 3 replies
- 0 kudos
Resolved! How to pass variables to a python file job
Hi everyone,It's relatively straight forward to pass a value to a key-value pair in notebook job. But for the python file job however, I couldn't figure out how to do it. Does anyone have any idea?Have been tried out different variations for a job wi...


- 14694 Views
- 3 replies
- 0 kudos
- 0 kudos
Thanks so much for this! By the way, is there a way to do it with the JSON interface? I am struggling to get the parameters if entered in this way
- 0 kudos
- 2187 Views
- 1 replies
- 0 kudos
Chat Bot with Azure blob and databricks
Hi Team, I am thinking to start a chat bot application for teams to query data from Azure blob and data bricks tables in python programming language.Please help me out on how i can start and which tools i can use for this requirement.Thanks in advanc...
- 2187 Views
- 1 replies
- 0 kudos
- 0 kudos
@Nagrjuna , that's a great idea! Although we do not know about your use case completely, I am sure you would definitely fall in love with our AI/ML Products. To create a Python chat bot application that can pull data from Azure Blob Storage and Datab...
- 0 kudos
- 2857 Views
- 1 replies
- 1 kudos
How to configure github credentials for a service principal NOT using Azure
I want to have a service principal run a job that uses a notebook in our github. We are AWS not Azure. How do I configure git credentials for the service principal? Does this use deploy keys?
- 2857 Views
- 1 replies
- 1 kudos
- 2864 Views
- 1 replies
- 1 kudos
Resolved! Workspace FileNotFoundExecption
I have a model created with catboost and exported in onnx format in workspace and I want to download that model to my local machine.I tried to use the Export that is in the three points to the right of the model, but the model weighs more than 10 Mb ...
- 2864 Views
- 1 replies
- 1 kudos
- 1 kudos
you need put file to FileStorehttps://docs.databricks.com/en/dbfs/filestore.html#save-a-file-to-filestore
- 1 kudos
- 2463 Views
- 1 replies
- 0 kudos
VS Code integration with Python Notebook and Remote Cluster
Hi, I'm trying to work on VS code remotely on my machine instead of using the Databricks environment on my browser. I have went through documentation to set up the Databricks. extension and also setup Databricks Connect but don't feel like they work ...
- 2463 Views
- 1 replies
- 0 kudos
- 4327 Views
- 1 replies
- 0 kudos
What happened to the ephemeral notebook links????? and the job ids????
Hey Databricks, Why did you remove the ephemeral notebook links and job Ids from the parallel runs? This has created a huge gap for us. We can no longer view the ephemeral notebooks, and also the Jobids are missing from the output. Waccha doing?...
- 4327 Views
- 1 replies
- 0 kudos
- 0 kudos
Hi Kaniz, It's funny you mention these things - we are doing some of those - the problem now is that the JobId is obscured from the output meaning we can't tell which ephemeral notebook goes with which JobId. It looks like the ephemeral notebook ...
- 0 kudos
- 5919 Views
- 0 replies
- 0 kudos
Updating Databricks SQL Warehouse using Terraform
We can Update SQL Warehouse manually in Databricks.Click SQL Warehouses in the sidebarIn Advanced optionsWe can find Unity Catalog toggle button there! While Updating Existing SQL Warehouse in Azure to enable unity catalog using terraform, I couldn'...
- 5919 Views
- 0 replies
- 0 kudos
- 6871 Views
- 5 replies
- 3 kudos
OSError: [Errno 78] Remote address changed
Hello:)as part of deploying an app that previously ran directly on emr to databricks, we are running experiments using LTS 9.1, and getting the following error: PythonException: An exception was thrown from a UDF: 'pyspark.serializers.SerializationEr...
- 6871 Views
- 5 replies
- 3 kudos
- 3 kudos
Hi @liormayn , I can understand. I see the fix went on 20 March 2024, you would have to restart the clusters. Thanks!
- 3 kudos
-
.CSV
1 -
Access Data
2 -
Access Databricks
3 -
Access Delta Tables
2 -
Account reset
1 -
adcAws databricks
1 -
ADF Pipeline
1 -
ADLS Gen2 With ABFSS
1 -
Advanced Data Engineering
2 -
AI
5 -
Analytics
1 -
Apache spark
1 -
Apache Spark 3.0
1 -
api
1 -
Api Calls
1 -
API Documentation
4 -
App
2 -
Application
2 -
Architecture
1 -
asset bundle
1 -
Asset Bundles
3 -
Auto-loader
1 -
Autoloader
4 -
Aws databricks
1 -
AWS security token
1 -
AWSDatabricksCluster
1 -
Azure
7 -
Azure data disk
1 -
Azure databricks
16 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
1 -
Azure Databricks SQL
6 -
Azure databricks workspace
1 -
Azure Unity Catalog
6 -
Azure-databricks
1 -
AzureDatabricks
1 -
AzureDevopsRepo
1 -
best practices
1 -
Big Data Solutions
1 -
Billing
1 -
Billing and Cost Management
2 -
Blackduck
1 -
Bronze Layer
1 -
Business Intelligence
1 -
CDC
1 -
Certification
3 -
Certification Exam
1 -
Certification Voucher
3 -
CICDForDatabricksWorkflows
1 -
Cloud_files_state
1 -
CloudFiles
1 -
Cluster
3 -
Cluster Init Script
1 -
Comments
1 -
Community Edition
4 -
Community Edition Account
1 -
Community Event
1 -
Community Group
2 -
Community Members
1 -
CommunityArticle
1 -
Compute
3 -
Compute Instances
1 -
conditional tasks
1 -
Connection
1 -
Contest
1 -
Credentials
1 -
csv
1 -
Custom Python
1 -
CustomLibrary
1 -
DAIS2026
1 -
Data
1 -
Data + AI Summit
1 -
Data Engineer Associate
1 -
Data Engineering
4 -
Data Explorer
1 -
Data Governance
1 -
Data Ingestion & connectivity
1 -
Data Ingestion Architecture
1 -
Data Processing
1 -
Databrick add-on for Splunk
1 -
databricks
5 -
Databricks Academy
1 -
Databricks AI + Data Summit
1 -
Databricks Alerts
1 -
Databricks App
2 -
Databricks Assistant
1 -
Databricks autoloader
1 -
Databricks Certification
1 -
Databricks Cluster
2 -
Databricks Clusters
1 -
Databricks Community
10 -
Databricks community edition
3 -
Databricks Community Edition Account
1 -
Databricks Community Rewards Store
3 -
Databricks connect
1 -
Databricks Dashboard
3 -
Databricks delta
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks Documentation
4 -
Databricks Error Message
1 -
Databricks genAI associate
1 -
Databricks JDBC Driver
2 -
Databricks Job
1 -
Databricks Lakeflow
1 -
Databricks Lakehouse Platform
6 -
Databricks Migration
1 -
Databricks Model
1 -
Databricks notebook
2 -
Databricks Notebooks
4 -
Databricks Partner
1 -
Databricks Platform
2 -
Databricks Pyspark
1 -
Databricks Python Notebook
1 -
Databricks Repo
1 -
Databricks Runtime
1 -
Databricks Serverless
2 -
Databricks SQL
5 -
Databricks SQL Alerts
1 -
Databricks SQL Warehouse
1 -
Databricks Terraform
1 -
Databricks UI
1 -
Databricks Unity Catalog
4 -
Databricks User Group
1 -
Databricks Workflow
2 -
Databricks Workflows
2 -
Databricks workspace
3 -
Databricks-connect
1 -
databricks_cluster_policy
1 -
DatabricksJobCluster
1 -
DataCleanroom
1 -
DataDays
1 -
Datagrip
1 -
DataMasking
2 -
DataVersioning
1 -
dbdemos
2 -
DBFS
1 -
DBRuntime
1 -
DBSQL
1 -
DDL
1 -
Dear Community
1 -
deduplication
1 -
Delt Lake
1 -
Delta Live Pipeline
3 -
Delta Live Table
5 -
Delta Live Table Pipeline
5 -
Delta Live Table Pipelines
4 -
Delta Live Tables
7 -
Delta Sharing
2 -
Delta Time Travel
1 -
deltaSharing
1 -
Deny assignment
1 -
Development
1 -
DevOps
1 -
DLT
10 -
DLT Pipeline
7 -
DLT Pipelines
5 -
Dolly
1 -
Download files
1 -
DQX
1 -
Dynamic Variables
1 -
Engineering With Databricks
1 -
env
1 -
ETL Pipelines
1 -
Event Driven
1 -
External Sources
1 -
External Storage
2 -
FAQ for Databricks Learning Festival
2 -
Feature Store
2 -
File Trigger
1 -
Filenotfoundexception
1 -
Free Edition
1 -
Free trial
1 -
friendsofcommunity
1 -
GCP Databricks
1 -
GenAI
2 -
GenAI and LLMs
1 -
GenAI Course Material
1 -
Genie
1 -
Getting started
3 -
Google Bigquery
1 -
HIPAA
1 -
Hubert Dudek
2 -
import
2 -
Integration
1 -
JDBC Connections
1 -
JDBC Connector
1 -
Job Task
1 -
JSON Object
1 -
LakeflowDesigner
1 -
Learning
2 -
Lineage
1 -
LLM
1 -
Login
1 -
Login Account
1 -
Machine Learning
3 -
MachineLearning
1 -
Market Place
1 -
Materialized Tables
2 -
Medallion Architecture
1 -
meetup
2 -
Metadata
1 -
Migration
1 -
ML Model
2 -
MlFlow
2 -
Model
1 -
Model Serving
1 -
Model Training
1 -
Module
1 -
Monitoring
1 -
Networking
2 -
Notebook
1 -
Onboarding
1 -
Onboarding Trainings
1 -
OpenAI
1 -
Pandas udf
1 -
Permissions
1 -
personalcompute
1 -
Pipeline
2 -
Plotly
1 -
PostgresSQL
1 -
Pricing
1 -
provisioned throughput
1 -
Pyspark
1 -
Python
5 -
Python Code
1 -
Python Wheel
1 -
Quickstart
1 -
Read data
1 -
Repos Support
1 -
Reset
1 -
Rewards Store
2 -
Salesforce with Databricks
1 -
Sant
1 -
Schedule
1 -
Serverless
3 -
serving endpoint
1 -
Session
1 -
Sign Up Issues
2 -
Software Development
1 -
Spark
1 -
Spark Connect
1 -
Spark scala
1 -
sparkui
2 -
Speakers
1 -
Splunk
2 -
SQL
8 -
streamlit
1 -
Summit23
7 -
Support Tickets
1 -
Sydney
2 -
Table Download
1 -
Tags
3 -
terraform
1 -
Training
2 -
Troubleshooting
1 -
Unity Catalog
4 -
Unity Catalog Metastore
2 -
Update
1 -
user groups
2 -
Venicold
3 -
Vnet
1 -
Voucher Not Recieved
1 -
Watermark
1 -
Webinar
1 -
Weekly Documentation Update
1 -
Weekly Release Notes
2 -
Women
1 -
Workflow
2 -
Workspace
3
- « Previous
- Next »
| User | Count |
|---|---|
| 142 | |
| 123 | |
| 57 | |
| 46 | |
| 40 |