Hello All,
I am trying to read the data and trying to group the data in order to pass it to predict function via @F.pandas_udf method.
#Loading Model
pkl_model = pickle.load(open(filepath,'rb'))
# build schema for output labels
filter_schema=[]
t = T.StructField("anomaly_prediction", T.IntegerType(),True)
filter_schema.append(t)
t1 = T.StructField("anomaly_score", T.DoubleType(),True)
filter_schema.append(t1)
return_schema = T.StructType(df.select(df.columns).schema.fields+filter_schema)
@F.pandas_udf(return_schema, F.PandasUDFType.GROUPED_MAP)
def inferdata(data):
dt = data[labelnames].to_numpy()
#dt = np.asarray(dt).astype('float64')
score, pred = pkl_model.predict(dt)
print('score and prediction is ',score, pred)
data["anomaly_prediction"] = pred
data["anomaly_score"] = score
return(data)
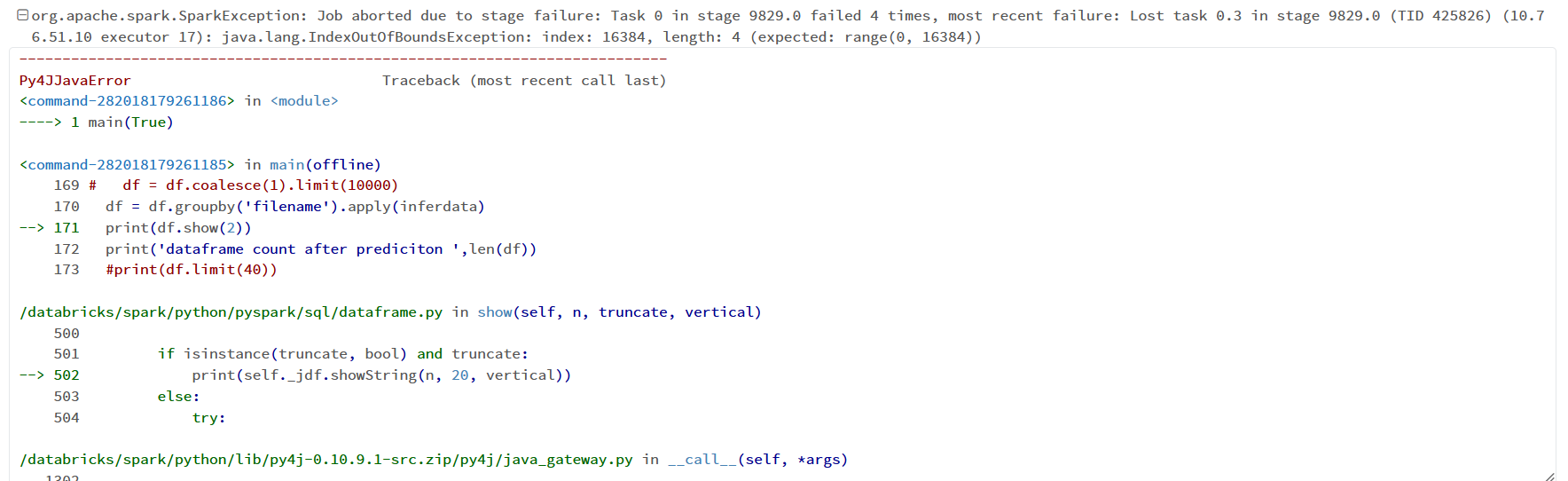
df = df.groupby('filename').apply(inferdata)
print(df.show(2))
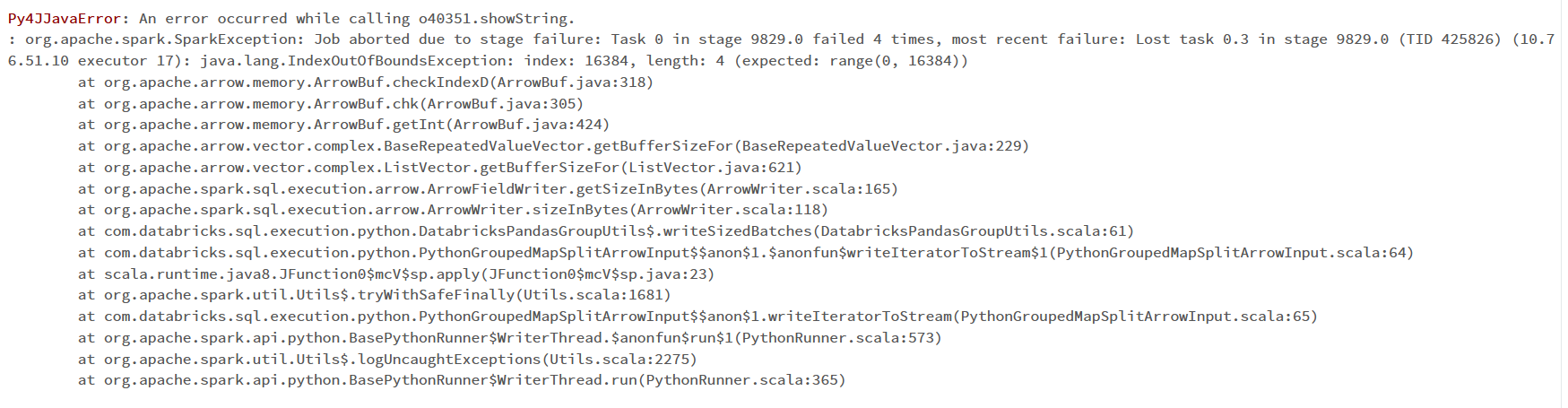
But it is throwing an error:
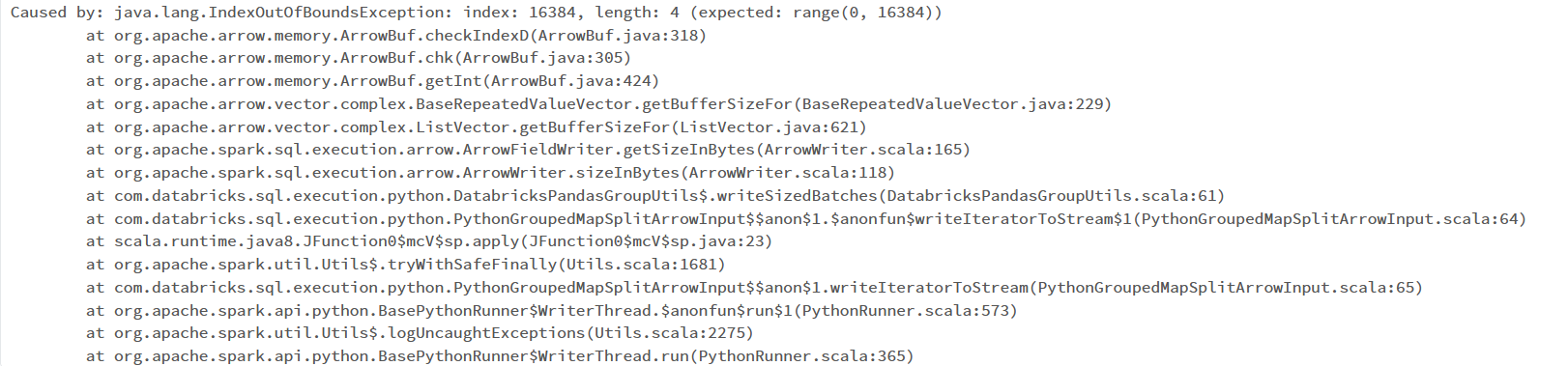
"java.lang.IndexOutOfBoundsException: index: 16384, length: 4 (expected: range(0, 16384))"



I have attached the code snippet and error images for your reference. I have been stuck with this problem for a week.
Could anybody please help me to resolve this issue?







{kind=link}
{kind=link}
{kind=link}