Engage in discussions on data warehousing, analytics, and BI solutions within the Databricks Community. Share insights, tips, and best practices for leveraging data for informed decision-making.
Here's your Data + AI Summit 2024 - Warehousing & Analytics recap as you use intelligent data warehousing to improve performance and increase your organization’s productivity with analytics, dashboards and insights.
Keynote: Data Warehouse presente...
We have a setup where we process sensor data in databricks using pyspark structured streaming from kafka streams, and continuisly write these to delta tables. These delta tables are served through a SQL warehouse endpoint to the users. We also store ...
Hi everyone!Is there any function in Databricks's dashboards to pause/halt visualization before a filter is inputted on the dashboard? Currently, my queries/visualizations are getting too long because of the data, and I want to stop it before a filte...
Getting this error in dbt when trying to run a query. Not happening in the actual SQL warehouse in Databricks. Is this a bug? Can only find source code when I search 'DatabricksSQLCursorWrapper' but no documentation or information otherwise.
Does anybody know whether we could customise the dates showing in the calendar selection in sql editor/dashboard?My query has a time frame in a particular period, however when I use DateRange parameter in sql editor, it could allow users to choose th...
Hi allWe are having some alarming issues regarding a script that yields different output when running on SQL vs Notebook. The correct output should be 8625 rows which it is in the notebook, but the output in Databricks SQL is 156 rows. The script use...
UPDATE:I think we have identefied and solved the issue. It seems like using LAST with Databricks SQL requires to excplicitly be careful about setting the "ignoreNull" argument and also be careful about the correct datatype. I guess this is because of...
We have previously been able to access our Databricks cluster in R using ODBC but it stopped working a couple of months ago and now i can't get it to connect.I've downloaded the latest drivers and added the right information in odbc/odbcinst files bu...
I have created a filter through the editing part in the dashboard, but when I drag this widget it cannot locate in other places except the top area. I know the filter in the dashboard has the unction to control the whole queries/ whole visualizations...
I wanted to calculate the total size in bytes for a given column for a table. I saw that you can use the bit_length function and did something like this giving you the total bits of the column but not sure if this is correct.SELECT sum(bit_length(to...
I looked at the docs of bit_length and it does not state if it is before or after compression.However since spark decompresses data on read, it is very likely it is the size before compression.The table size is read from metadata and is compressed.To...
Hi Team, I am creating my data warehouse on AWS s3 and corresponding tables on databricks warehouse.I want to connect looker studio (which is different from looker) to these databricks tables and be able to create reports.Could you please help us on ...
We are also interested in this functionality. But there are no databricks connectors for Looker Studio. But as Databricks SQL Statement Execution REST API is already available in public preview, it is now possible to Build a Community Connector for d...
I'm working on returning some statistics for a workflow where the date ranges can either be entered manually or when it runs on a schedule it is setting it's date ranges as a task value. I'm able to return the one's where it has been manually set usi...
When I use following java code to get namespace from AWD Databricks: import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.Properties;
public class DatabricksJDBCExample {
...
@charlie_cai database is not a valid configuration parameter available in the jdbc string. You can use ConnCatalog and ConnSchema to provide this information.This is also documented here - https://docs.databricks.com/en/integrations/jdbc-odbc-bi.html...
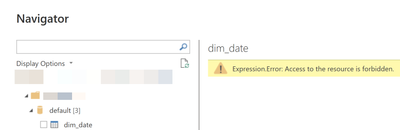
I am using Power BI Desktop to connect to Unity Catalog using Delta Sharing. When I connect, I enter my endpoint, enter my bearer token, browse the catalog and can see my tables. But when I try to preview or load a table, I get the error "access to r...
It turned out we had to allow my IP address on the storage account used by Unity Catalog. I guess i wasn't expecting to need that for Delta Sharing, but that indeed did fix the problem.
Hi,While running a notebook during a nightrun on Azure Databricks, it got stuck on Initializing RocksDB. We are not using any streaming data nor have enabled RocksDB. Anyone has any clue how to disable RocksDB or prevent this in the future?Thanks!