Hi dear community,
My company is in a migration project from MapR to databricks, and we have the following piece of code that used to work fine in this platform but once in databricks it stopped working. I noticed that this is failing is just with this specific regular expresion because with others this is not getting any error.
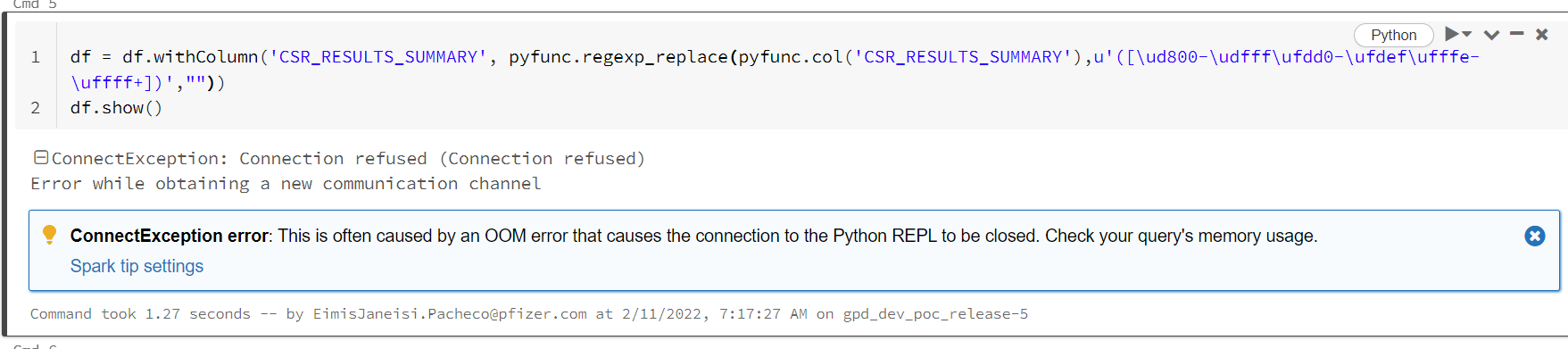
The error is "Error while obtaining a new communication channel" and after that, we can not continue writting code and testing, something breaks.
I am attaching a screenshot for reference.

import pyspark.sql.functions as pyfunc
df=spark.read.parquet("/mnt/gpdipedlstgamrasp50565/stg_db/intermediate/ODX/ODW/STUDY_REPORT/Current/Data/")
df.count()
df = df.withColumn('CSR_RESULTS_SUMMARY', pyfunc.regexp_replace(pyfunc.col('CSR_RESULTS_SUMMARY'),u'([\ud800-\udfff\ufdd0-\ufdef\ufffe-\uffff+])',''))
df.show()
Thank you very much in advance.







{kind=link}