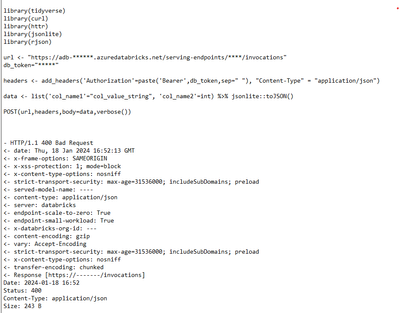
I am trying to get a prediction by querying the ML Endpoint on Azure Databricks with R. I'm not sure what is the format of the expected data. Is there any other problem with this code? Thanks!!!
Hi Kaniz, I was able to find the solution. You should post this in the examples when you click "Query Endpoint"You only have code for Browser, Curl, Python, SQL. You should add a tab for RHere is the solution:library(httr)url <- "https://adb-********...
Hi! When i was creating a new endpoint a have this alert CREATE A MODEL SERVING ENDPOINT TO SERVE YOUR MODEL BEHIND A REST API INTERFACE. YOU CAN STILL USE LEGACY ML FLOW MODEL SERVING UNTIL JANUARY 2024 I don't understand if my Legacy MLFlow Model ...
Hi @MaKarenina, The alert you received states that you can continue using Legacy MLflow Model Serving until January 2024.
However, there are a few important points to consider:
Support: After January 2024, Legacy MLflow Model Serving will no lon...
Hello,I am trying to deploy a composite estimator as single model, by logging the run with mlflow and registering the model.Can anyone help with how this can be done? This estimator contains different chains-text: data- tfidf- svm- svm.decision_funct...
Hi @prafull , Deploying a composite estimator with MLflow involves several steps.
Let’s break it down:
Logging the Run with MLflow:
First, you’ll need to train your composite estimator using the different pipelines you’ve mentioned (text and cat...
Hi everyone,I am using databricks and mlflow to create a model and then register it as a serving endpoint. Sometimes the models takes more than 2 minutes to run and after 2 minutes it gives a timeout error:Timed out while evaluating the model. Verify...
Hi @Shumi8, When dealing with timeout issues in MLflow, it’s essential to configure the relevant parameters to ensure your server remains responsive.
Let’s address this step by step:
MLFLOW_SCORING_SERVER_REQUEST_TIMEOUT:
This parameter controls ...
Hello,Trying to create a custom serving endpoint, using artifacts argument while logging the run/model to save .jar files. These files are called during when calling .predict. JAVA runtime 8 or higher is required to run the jar file, not sure how to ...
Hi @prafull,
Creating a custom serving endpoint with the necessary JAVA runtime is essential for deploying your model.
Let’s explore some steps to achieve this:
Databricks Model Serving:
Databricks provides options for creating and managing model...
We have deployed Dolly (https://huggingface.co/databricks/dolly-v2-3b) as a REST API endpoint on our infrastructure. The notebook we used to do this is included in the text below my question.The Databricks infra used had the following config - (13.2...
I had a similar problem when I used HuggingFacePipeline(pipeline=generate_text) with langchain. It worked to me when I tried to use HuggingFaceHub instead. I used the same dolly-3b model.
I saw that Foundation Model API is not HIPAA compliant. Is there a timeline in which we could expect it to be HIPAA compliant? I work for a healthcare company with a BAA with Databricks.
Hi @yhyhy3
Foundation Model API's HIPAA certification:AWS: e.t.a. March 2024Azure: e.t.a. Aug 2024
HIPAA certification is essentially having a third party audit report for HIPAA. That is not the date that a HIPAA product offering may/will necessari...
While trying to create a serving endpoint with my custom model, I get a "Failed" state:Model server failed to load the model. Please see service logs for more information.The service logs show the following:Container failed with: failed to create con...
I have faced the similar issue. still didn't find the right solution. In my case, the below is the error trace i found from service logs. Not sure where the issue could be"An error occurred while loading the model. You haven't configured the CLI yet!...
Hi,I'm trying to enable inference table for my llama_2_7b_hf serving endpoint, however I'm getting the following error:"Inference tables are currently not available with accelerated inference." Anyone one have an idea on how to overcome this issue? C...
Thank you for posting your question in our community! We are happy to assist you.To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?This...
Hi all! I am trying to create an endpoint for Easy OCR. I was able to create the experiment using a wrapper class with the code below: # import libraries
import mlflow
import mlflow.pyfunc
import cloudpickle
import cv2
import re
import easyocr
impo...
I am trying to load a simple Minmaxscaler model that was logged as a run through spark's ML Pipeline api for reuse. On average it takes 40+ seconds just to load the model with the following example: This is fine and the model transforms my data corre...
Hello,Any solutions found for this issue?I'm serving up a large number of models at a time, but since we converted to PySpark (due to our data demands), the mlflow.spark.load_model() is taking hours.Part of the reason to switch to spark was to help w...
Hi fellows, I encountered memory(?) error when sending POST requests to my real-time endpoint, and I'm unable to find hardware setting to increase memory, as suggested by the Service Logs (below). Steps to Repro:(1) I registered a custom MLFlow model...
Thank you for your responses, @Annapurna_Hiriy and @KanizIndeed, it appeared that my original model (~800MB) was too big for the current server. Based on your suggestion, I made a simpler/smaller model for this project, and then I was able to deploy ...
Hi, We provisioned the endpoint with 4 DBUs and also disabled the scale_to_zero option. For some reason, it randomly drops to 0 provisioned concurrency. Logs available in the serving endpoint service are not insightful. Currently, we are provisioning...
Hi,I apologize if my question wasn't clear; let me clarify it.We are not using the scale_to_zero option and we are not doing any warmup requests so it should never scale to zero despite traffic or zero traffic right?
I have been trying to deploy spark ML Models from the experiement page via UI, the deployment gets aborted after a long run, any particular reason for why this might be happening? I have also taken care of dependencies still it is failing.Dependency ...
@Kumaran Thanks for the reply kumaram The deployment was finally successful for Random Forest algorithm, failing for sparkxgbregressor.Sharing code snippet:from xgboost.spark import SparkXGBRegressor
vec_assembler = VectorAssembler(inputCols=train_df...