Hello everyone,I'm trying to register a model with MLflow in Databricks, but encountering an error with the following command: model_version = mlflow.register_model(f"runs:/{run_id}/random_forest_model", model_name) The error message is as follows:...
Hey Databricks, Why did you remove the ephemeral notebook links and job Ids from the parallel runs? This has created a huge gap for us. We can no longer view the ephemeral notebooks, and also the Jobids are missing from the output. Waccha doing?...
Hi Kaniz, It's funny you mention these things - we are doing some of those - the problem now is that the JobId is obscured from the output meaning we can't tell which ephemeral notebook goes with which JobId. It looks like the ephemeral notebook ...
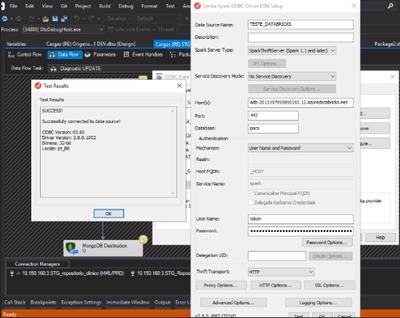
Hi folks, I'm working on a project with Databricks using Unity Catalog and a connection to SSIS (SQL Server Integration Services).My team is trying to access data registered in Unity Catalog using Simba ODBC driver version 2.8.0.1002. They mentioned ...
Hi @FelipeRegis, It seems you’re encountering issues with accessing data registered in Unity Catalog using the Simba ODBC driver.
Let’s explore some possible solutions:
Delta Lake Native Connector:
Consider using Delta Lake’s native Delta JDBC/OD...
Hey Databricks, Why did you take away the jobids from the parallel runs? We use those to identify which output goes with which run. Please put them back.Benedetta
Hi @Benedetta,
Thank you for reaching out. I understand your concern regarding the jobids in parallel runs. I will look into this matter and get back to you with more information as soon as possible.
Hi I'm creating a DLT pipeline which uses DLT CDC to implement SCD Type 1 to take the latest record using a datetime column which works with no issues:@dlt.view
def users():
return spark.readStream.table("source_table")
dlt.create_streaming_table(...
Hi @dm7, Thank you for providing the details of your DLT pipeline and the desired outcome!
It looks like you’re trying to implement a Slowly Changing Dimension (SCD) Type 2 behaviour where you want to capture historical changes over time.
Let’s br...
Hi,I'm trying to create a customer docker image with some R packages re-installed. However, when I try to use it in a notebook, it can't seem to find the installed packages. The build runs fine.FROM databricksruntime/rbase:14.3-LTS## update system li...
Hi @BenCCC,
Here are a few things you can check:
Package Installation in Dockerfile:
In your Dockerfile, you’re using the RUN R -e 'install.packages(...)' command to install R packages. While this approach works, there are alternative methods th...
Hello Databricks Community,I am currently working on creating a Terraform script to provision clusters in Databricks. However, I've noticed that by default, the clusters created using Terraform have the policy set to "Unrestricted."I would like to co...
Hello, many thanks for your question, on the cluster creation template there is an optional setting called policy_id, this id can be retrieved from the UI, if you go under Compute > Policies > Select the policy you want to set.By default if the user ...
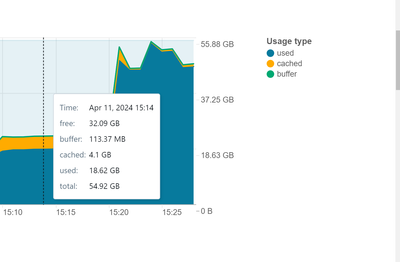
Hi,I have a single-node personal cluster with 56GB memory(Node type: Standard_DS5_v2, runtime: 14.3 LTS ML). The same configuration is done for the job cluster as well and the following problem applies to both clusters:To start with: once I start my ...
Hi @egndz, It seems like you’re dealing with memory issues in your Spark cluster, and I understand how frustrating that can be.
Initial Memory Allocation:
The initial memory allocation you’re observing (18 GB used + 4.1 GB cached) is likely a com...
Hi,I have cloned a public git repo into my Databricks account. It's a repo associated with an online training course. I'd like to work through the notebooks, maybe make some changes and updates, etc., but I'd also like to keep a clean copy of it. M...
Hi DavidKxx,
You can clone public remote repositories without Git credentials (a personal access token and a username). To modify a public remote repository or to clone or modify a private remote repository, you must have a Git provider username and...
I am wondering If can retrieve any information from Azure Log Analytics custom tables (already set) for Azure Databricks. Would like to retrieve information about query and data performance for SQL Warehouse Cluster. I am not sure If I can get it fro...
Hi @groch_adam, Retrieving information from Azure Log Analytics custom tables for Azure Databricks is possible.
Let me guide you through the process.
Azure Databricks Monitoring Library:
To send application logs and metrics from Azure Databric...
Hello:)we are trying to run an existing working flow that works currently on EMR, on databricks.we use LTS 10.4, and when loading the data we get the following error:at org.apache.spark.api.python.BasePythonRunner$WriterThread.run(PythonRunner.scala:...
Hi @liormayn, It seems you’re encountering an issue related to the schema of your data when running your existing workflow on Databricks.
Let’s explore some potential solutions:
Parquet Decimal Columns Issue:
The error message you’re seeing might...
I'm encountering an issue with the installation of Python packages from a Private PyPI mirror, specifically when the package contains dependencies and the installation is on Databricks clusters - Cluster libraries | Databricks on AWS. Initially, ever...
Hi @hugodscarvalho, It’s frustrating when package installation issues crop up, especially when dealing with dependencies in complex projects.
Let’s explore some potential solutions to address this inconsistency in your Databricks cluster installat...
Hello,I need to create and destroy a model endpoint as part of CI/CD. I tried with mlflow deployments create-endpoint, giving databricks as --target however it errors saying that --endpoint is not a known argument when clearly --endpoint is required....
Hi @afdadfadsfadsf, Creating and managing model endpoints as part of your CI/CD pipeline is essential for deploying machine learning models. I can provide some guidance on how to set up a CI/CD pipeline using YAML in Azure DevOps.
You can adapt th...
What happens to a currently running job when a workspace is deployed again using Terraform? Are the jobs paused/resumed, or are they left unaffected without any down time? Searching for this specific scenario doesn't seem to come up with anything and...
Hi @scottbisaillon, When deploying a workspace again using Terraform, the behaviour regarding currently running jobs depends on the specific Terraform version and the platform you are using.
Let’s explore the details:
Terraform Cloud (form...
I have a DLT pipeline running in continous mode. I have a stream to stream join which runs for the first 5hrs but then fails with a Null Pointer Exception. I need assistance to know what I need to do to handle this. my code is structured as below:@dl...
Hi @TinasheChinyati, It looks like you’re encountering a Null Pointer Exception in your DLT pipeline when performing a stream-to-stream join.
Let’s break down the issue and explore potential solutions:
The error message indicates that the query te...