HiI’m new to data modelling so could use some help.I’m building a personal project using a fairly standard 3NF sales database as the source data. So far I have a pipeline that incrementally extracts data from the source system each day into a Raw sto...
This is what my medallion architecture looks like - 1) Bronze Layer - append raw data.2) Silver Layer, reflect current(active) data and I do business logic transformations. The Silver layer should serve as your cleaned and transformed staging area. H...
I have an on-premises Power BI Report Server that uses the Simba Spark ODBC Driver (2.8) to connect to Databricks. It can connect to a serverless warehouse successfully and run its queries, but it never seems to disconnect the session, and so the war...
It's working sometimes. Only correlation I have found so far is that a successful query will disconnect as expected but any error will keep the connection to the warehouse open indefinitely.
Hi,As a formal requirement in my project I need to keep original, raw (mainly CSVs and XMLs) files on the lake. Later on they are being ingested into Delta format backed medallion stages, bronze, silver, gold etc.From the audit, operations and discov...
Hi @KrzysztofPrzyso, It sounds like you’re dealing with an interesting challenge related to performance and data organization in your Azure Databricks environment.
Let’s break down the issues you’ve mentioned and explore potential solutions:
Scan...
I'm creating dashboard with multiple visualizations from a notebook.Whenever I add a new visualization, the default position in dashboard is top left which mess up all the format I did for previous graph. Is there a way to default add to the bottom o...
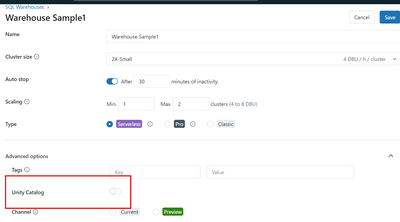
Manual ApproachWe can Update SQL Warehouse manually in Databricks.Click SQL Warehouses in the sidebarIn Advanced optionsWe can find Unity Catalog toggle button there! While Updating Existing SQL Warehouse in Azure to enable unity catalog using terraf...
Hello @Sudheer2 looks like there's an open feature request for that:https://github.com/databricks/terraform-provider-databricks/issues/2797I'll be checking with the terraform team if it's already on the roadmap.
Hello,I'm wondering if there's a method or workaround to execute JDBC table queries in a similar manner to other cluster types. Currently, attempting to do so results in an error stating that only text-based files (such as JSON, Parquet, Delta, etc.)...
We have created a Unity Catalog instance on top of our Lakehouse (built entirely with Azure Databricks). We are using Power BI to develop and serve our analytics and reporting needs. I've granted the "Account Users" group the appropriate privileges f...
Thanks for explaining this! This doesn't do exactly what I was hoping—it doesn't block all access to the workspace. Users can still login and access their own workspace and run SQL queries, explore the catalog, etc. But they ARE blocked from accessin...
In relational data warehouse systems it was best practise to represent date values as YYYYMMDD integer type values in tables. Date comparison could be done easily without using date-functions and with low performance impact.Is this still the recomme...
Hi @DataFarmer I Databricks I will advise you to use date type instead of int, this will make your life much simpler while working on the date type data.
When trying to connect to a SQL warehouse using the JDBC connector with Spark the below error is thrown. Note that connecting directly to a cluster with similar connection parameters works without issue, the error only occurs with SQL Warehouses.py4j...
Same error here, I am trying to save spark dataframe to Delta lake using JDBC driver and pyspark using this code:#Spark session
spark_session = SparkSession.builder \
.appName("RCT-API") \
.config("spark.metrics.namespace", "rct-a...
In order to create a ci/cd pipeline to deliver dashboards (here monitoring), how to export / import a dashboard created in databricks sql dashboard from one workspace to another?Thanks
Hi Is there a command you could use to list all computes configured in your workspace (active and non-active). This would be really helpful for anyone managing the platfrom to pull all the meta data (tags ,etc) and quickly evaluate all the configura...
@Kaizen You've got three ways of doing this:- Using REST API (https://docs.databricks.com/api/workspace/clusters/list),- Using CLI (https://github.com/databricks/cli/blob/main/docs/commands.md#databricks-clusters-list---list-all-clusters)- Using Pyth...
Team,I did setup a SQL Warehouse Cluster to support request from Mobile devices through REST API. I read through the documentation of concurrent query limit which is 10. But in my scenario I had 5 small clusters and the query monitoring indicated the...
Hi @Ramakrishnan83,
Databricks SQL does indeed support concurrent read requests. However, the exact definition of concurrency can vary based on the cluster configuration and workload.By default, Databricks limits the number of concurrent queries per...
Is there any business use-case where profile_metrics and drift_metrics are used by Databricks customers.If so,kindly provide the scenario where to leverage this feature e.g data lineage,table metadata updates.
hey @pankaj2264. both profile metric and drift metric tables are created and used by Lakehouse monitoring to assess the performance of your model and data over time or relative to a baseline table. you can find all the relevant information here Intro...
Hi,Is it possible to convert existing delta table with partition having data to clustering? If so can you please suggest the steps required? I tried and searched but couldn't find any. Is it that liquid clustering can be done only for new Delta table...