As per the very short review session of the available source code and the SPIP itself, I think the answer is YES.It is especially clear for spark.sql.sources.v2.bucketing.partiallyClusteredDistribution.enabled that says:This is an optimization on ske...
HiI have around 20 million records in my DF, and want to save it in HORIZINTAL SQL DB.This is error:org.apache.spark.SparkException: Job aborted due to stage failure: A shuffle map stage with indeterminate output was failed and retried. However, Spar...
facing same issue since we moved from Spark 3.2.1 (databricks 10.4) to Spark 3.3.2 (databricks 12.2), how come we have seen this problem before, now we do.. is it Spark related or Databricks related (autoscaling?)
Hi Databricks Support,I'm encountering an issue with creating and running jobs on Databricks. Here are the details:Problem Description:When attempting to create and run a job using the old JSON (which was successfully used to create and run jobs usin...
Hi @Kishor, I’m sorry to hear that you’re having trouble with Databricks job creation and retrieval of run output.
Issue 1: “Error: No task is specified.” This error typically occurs when the JSON file used for job creation does not specify a t...
Hi Guys,Just started the ASP 2.1L Spare SQL Lab and I get this error, when I run the first setup SQL command:%run ../Includes/Classroom-Setup-SQLThe execution of this command did not finish successfullyPython interpreter will be restarted.Python inte...
Hi @SHS, The error message you’re seeing is due to a mismatch between the expected Databricks Runtime version and the one you’re currently using. The lab you’re working on expects one of the following versions: ‘11.3.x-scala2.12’, ‘11.3.x-photon-scal...
Hi @JordanMartin, We're thrilled to hear that you had a great experience at DAIS 2023! Your feedback is valuable to us, and we appreciate you taking the time to share it on the community platform.
We wanted to let you know that the Databricks Communi...
Hi @Rafa82, We're thrilled to hear that you had a great experience at DAIS 2023! Your feedback is valuable to us, and we appreciate you taking the time to share it on the community platform.
We wanted to let you know that the Databricks Community Tea...
Hi @RayChan,
We're thrilled to hear that you had a great experience at DAIS 2023! Your feedback is valuable to us, and we appreciate you taking the time to share it on the community platform.
We wanted to let you know that the Databricks Community T...
Hi All,I am facing issue while running a new table in bronze layer.Error - AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: Unable to alter table.com.databricks.backend.common.rpc.SparkDriverExceptions$SQLExecutionException: org.a...
Hello @Mirza1 ,
Could you please share the source code that is generating the exception, as well as the DBR version you are currently using? This will help me better understand the issue.
When executing a withColumn (running on DBR 14.3 LST) I get this error:Error in callback <bound method UserNamespaceCommandHook.post_run_cell of <dbruntime.DatasetInfo.UserNamespaceCommandHook object at 0x7feda2b2efb0>> (for post_run_cell):How shoul...
Hi @Henrik_, I recommend checking the callback function and any relevant dependencies to identify the root cause. If you can provide more details or share the relevant code snippet, I’d be happy to assist further!
I am getting an "INTERNAL_ERROR" on a databricks job submitted through the API. Which says:"Run result unavailable: run failed with error message All access to AWS S3 resource has been disabled"However, when I click on the notebook created by the job...
Hi,I'm trying to execute the following code:%sqlSELECT LSOA21CD, ST_X(ST_GeomFromWKB(Geom_Varbinary)) AS STX, ST_Y(ST_GeomFromWKB(Geom_Varbinary)) AS STYFROM ordnance_survey_lsoas_december_2021_population_weighted_centroidsWHERE LSOA21CD ...
Hello @GMB , how are you?
The "st_x" function is part of the spatial expressions supported in Photon-enabled Databricks Runtime 14.2 with the Private Preview enabled.
Here are the steps you can follow:
Ensure that you're using a Photon-enabled Datab...
I'm using DAB to deploy a "jobs" resource into Databeicks and into two environments: "dev" and "prod". I pull the notebooks from a remote git repository using "git_resource", and defined the default job to use a tag to find which version to pull. Ho...
I use target overrides to switch between branch and tags on different environments: resources:
jobs:
my_job:
git_source:
git_url: <REPO-URL>
git_provider: gitHub
targets:
staging:
resources:
jobs:
my_j...
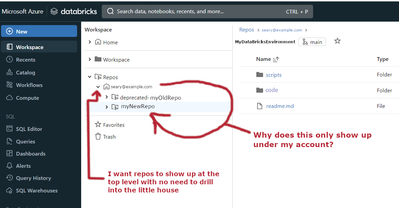
When I attach a Git repo to Databricks, it always puts the repo under my username/domain name:How can I create a "team" repo at the top level, so teammates don't have to drill into my username?
Hi,Interest of using a repo is to have a dedicated area for each of developers.If you want to have only a folder with the last version of the code, you should a CI/CD pipeline that will package the code and then delivered into a folder inside Workspa...
Hello.I'm currently trying to migrate a project from dbx to Databricks Asset Bundles. I have successfully created the required profile using U2M authentication with the command```databricks auth login --host <host-name>```I'm able to see the new prof...
I ran into a similar error just now, and in my case, Pycharm was running some iPython startup scripts each time it opened a console. There was, for some reason, a file at `~/.ipython/profile_default/startup/00-databricks-init-a5acf3baa440a896fa364d18...
Hi!So I’ve been wondering since I started with the Data Engineering Learning Plan on the Customer Academy, should I go with my Community Edition Databricks, or I should go with creating a premium edition on either a cloud provider or the website.Than...