Hi @digger_fresh_03,
Thank you for sharing your experience from DAIS Summit 2023! We're thrilled to hear that you found the training on the Databricks Lakehouse Platform valuable.
We appreciate your attendance and are excited to announce that the Dat...
Hi @Anette, That's great to hear! It sounds like you had a rewarding experience at the summit. Meeting other professionals and learning about the latest advancements in LLM must have been incredibly valuable.
I wanted to let you know that the Databri...
Hello Everyone,I'm here to learn about technology advancements and how they can help my company. Keynotes were great and learned lot of things through breakout sessions and looking forward to giving back to the community
Hi @shahebaj, We're thrilled to hear about your positive experience at DAIS 2023 and your eagerness to give back to the community!
Your participation and engagement are what make events like DAIS so valuable. We appreciate your support and look forwa...
The talk highlighted the benefits of using an open data lake for unified batch and streaming workloads and showcased features like Autoloader for data discovery, streaming triggers for seamless switching, and streaming aggregation for incremental com...
Hi @Hyperparam42,
Thank you for sharing your experience and insights from the Data + AI Summit 2023!
We're thrilled to hear that you found the talk on multicloud data streaming to be enlightening.
We wanted to let you know that the Databricks Commun...
Great Conference, it was cool learning about creating my own LLM, and the risks associated with LLM.sMy favorite activity was the Spin at Dark on Tuesday night!
Hi @dy, Great to hear you had a valuable experience at DAIS 2023! We appreciate your attendance and participation.
We wanted to share that the Databricks Community Team will be returning to San Francisco to host the Databricks Community booth at DAIS...
Enrolled in the “Machine Learning in Production” and the “LLMs in Production” Classes and completed. Great Training.. looking forward to implementing soon!!!
Hi @DatabricksBofA, That's fantastic to hear! It's always rewarding to see attendees like yourself finding value in the training and looking forward to implementing what you've learned. Your enthusiasm is truly appreciated!
I wanted to share some exc...
What a great community of people and practitioners! Loved to learn more about the path forward and all the ways this community will certainly have an impact on the future of AI.
Hi @ValMir, That's a wonderful sentiment! It's fantastic to hear that you found the DAIS event so enriching. Your enthusiasm for the community and its impact on the future of AI is truly inspiring. We greatly appreciate your attendance and participat...
Hondro Sol to całkowicie naturalny aerozol, który szybko wzmacnia chrząstki, ścięgna i stawy. Ten produkt jest przeznaczony na zapalenie stawów lub przewlekły ból łokci, ramion, pleców, kolan lub szyi. Łagodzi ból i stany zapalne oraz odmładza skórę....
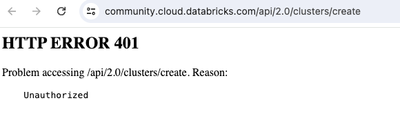
I want to have a service principal run a job that uses a notebook in our github. We are AWS not Azure. How do I configure git credentials for the service principal? Does this use deploy keys?
Hi @brian999, Let’s break down the steps for configuring Git credentials for a service principal in an AWS environment:
Create an IAM User:
First, set up an Amazon Web Services (AWS) account if you haven’t already.Create an IAM user (or use an ex...
Hi, I'm trying to work on VS code remotely on my machine instead of using the Databricks environment on my browser. I have went through documentation to set up the Databricks. extension and also setup Databricks Connect but don't feel like they work ...
Hi @mohaimen_syed, It sounds like you’re trying to use Databricks Connect to run a Python notebook on a remote Azure Databricks cluster from your local machine.
Let’s break down the steps to achieve this:
Configure Azure Databricks Authentication...
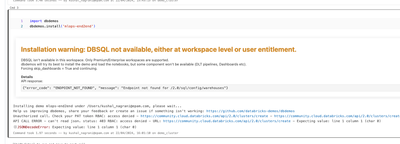
Hello,I am trying to run this demo in databricks community edition but i am facing error.MLOPS DEMO - https://www.databricks.com/resources/demos/tutorials/data-science-and-ai/mlops-end-to-end-pipeline?itm_data=demo_centerSomeone else also faced the s...
Hey @kushalnagrani , thank you for sharing this. I am facing the same issue. Could you please help me where can I find these settings? I am new, just created a community workspace and I thought given I am the admin I will have all these by default - ...
Hello,I've recently embarked on integrating Splunk with Databricks. My aim is to efficiently ingest data from Splunk into Databricks. While I've reviewed the available documentation on Splunk Integration, it primarily covers basic information. Howeve...
I'd highly recommend checking out Fivetran. Easy integration with Databricks, cost effective and they have recently launched a Splunk integration. https://fivetran.com/docs/connectors/applications/splunk
You can set it up on the Data Ingestion sectio...
Hello I am trying to run the SparkXGBoostRegressor and I am getting the following error:SpoilerPy4JError: An error occurred while calling o992.resourceProfileManager. Trace: py4j.security.Py4JSecurityException: Method public org.apache.spark.resource...
Hi @rahuja, The error you’re encountering might be related to the interaction between PySpark and XGBoost.
Let’s explore some potential solutions:
PySpark Version Compatibility:
Ensure that your PySpark version is compatible with the XGBoost vers...
Hi community, I am getting below warning when I try using pyspark code for some of my use-cases using databricks-connect. Is this a critical warning, and any idea what does it mean?Logs: WARN DatabricksConnectConf: Could not parse /root/.databricks-c...
Hi, @Surajv, The warning you’re encountering is related to using Databricks Connect with PySpark.
Databricks Connect: Databricks Connect is a Python library that allows you to connect your local development environment to a Databricks cluster. I...
Hi everyone,I'm currently facing an issue with handling a large amount of data using the Databricks API. Specifically, I have a query that returns a significant volume of data, sometimes resulting in over 200 chunks.My initial approach was to retriev...
Hi @rafal_walisko, Handling large volumes of data using the Databricks API can indeed be challenging, especially when dealing with numerous chunks.
Let’s explore some strategies that might help you optimize your approach:
Rate Limits and Paral...