We have to generate over 70 intermediate tables. Should we use temporary tables or dataframes, or should we create delta tables and truncate and reload? Having too many temporary tables could lead to memory problems. In this situation, what is the mo...
Hi Phani1,
It would be a use case specific answer, so if it is possible I would suggest to work with the Solution Architect on this or share some more insights for a better guidance.
When I say that, I just would want to understand would we really ne...
Hi,I have cloned a public git repo into my Databricks account. It's a repo associated with an online training course. I'd like to work through the notebooks, maybe make some changes and updates, etc., but I'd also like to keep a clean copy of it. M...
Hi DavidKxx,
You can clone public remote repositories without Git credentials (a personal access token and a username). To modify a public remote repository or to clone or modify a private remote repository, you must have a Git provider username and...
Hi,I am getting FilereadException Error while reading JSON file using REST API Connector.It comes when data is huge in Json File and it's not able to handle more than 1 Lac records.Error details:org.apache.spark.SparkException: Job aborted due to sta...
Hi all, I am using Databricks and created a notebook and would like to run in Dashboard. It works correctly. I share the Dashboard with another user UserA with "Can Run" permission When I login as a UserA and login and accesses Dashboard then does a...
Hi @Koa, You’ve encountered a security concern related to Databricks and handling JWT tokens within notebooks.
Dashboard State Persistence:
When you share a dashboard with another user (in this case, UserA), any updates made by that user will re...
I'm seeking advice regarding Databricks bundles. In my scenario, I have multiple production environments where I aim to execute the same DLT. To simplify, let's assume the DLT reads data from 'eventhub-region-name,' with this being the only differing...
We have an integration flow where we want to expose databricks data for querying through odata(webapp). For this piecedatabricks sql API <- Delta tables :2 questions here:1. can you share link/documentation on how we can integrate databricks <-delta ...
Hi @Ruby8376 - can you please review the similar posts where the resolution is provided
https://community.databricks.com/t5/warehousing-analytics/databricks-sql-restful-api-to-query-delta-table/td-p/8617
https://www.databricks.com/blog/2023/03/07/da...
Hello,I am running a job that depends on the information provided in column storage_sub_directory in system.information_schema.tables .... and it worked until 1-2 weeks ago.Now I discovered in the doc that this column is deprecated and always null , ...
Same issue here - we were using this to join to our S3 inventory files to determine the top tables to optimize and vacuum. Started failing about 2 weeks ago
hi,I cannot install geopandas in my notebook, ive tried all different forms of generic fix, pip installs etc but always get this error:CalledProcessError: Command 'pip --disable-pip-version-check install geopandas' returned non-zero exit status 1.---...
Hi @vbvasa,
The error message indicates that a GDAL API version must be specified. You can address this by providing a path to gdal-config using a GDAL_CONFIG environment variable or by using a GDAL_VERSION environment variable1.To set the GDAL_CONF...
Hi @ChristopherQ1,
OData (Open Data Protocol) is a standard for building and consuming RESTful APIs. It provides a consistent way to expose and consume data over the web.While OData can be used for data integration, it’s essential to evaluate whethe...
I have encountered a technical issue on Databricks.While executing commands both in Spark and SQL within the Databricks environment, I’ve run into permission-related errors from selecting files from DBFS. "org.apache.spark.SparkSecurityException: [IN...
Hello Mounika, many thanks for your question, are you using a shared access cluster? If yes, shared clusters requires you to grant Select permission on Any file to be able to access DBFS as mentioned on this doc https://docs.databricks.com/en/data-go...
How do I impersonate a user? I can't find any documentation that explains how to do this or even hint that it's possible.Use case: I perform administrative tasks like assign grants and roles to catalogs, schemas, and tables for the benefit of busines...
Hello, many thanks for your question. Right now impersonation is not possible in the Databricks environment, one possible solution might be that if you are an account admin you can remove your admin permissions from the account console on the specifi...
We use a private PyPI repo (AWS CodeArtifact) to publish custom python libraries. We make the private repo available to DBR 12.2 clusters using an init-script as prescribed here in the Databricks KB. When we tried to upgrade to 13.2 this stopped wor...
I'm coming back to provide an updated solution that doesn't rely on the implementation detail of the user name (e.g., libraries) - which is not considered a contract and could potentially change and break in the future.The key is to use the --global ...
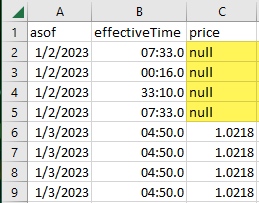
After running a sql script, when downloading the results to a csv file, the file includes a null string for blank cells (see screenshot). Is ther a setting I can change to simply get empty cells instead?
I'm getting tis error while running any cell in notebook. On the top middle it is coming like this. "Uncaught TypeError: Cannot redefine property: googletagReload the page and try again. If the error persists, contact support. Reference error code: 7...
Hi @_raman_ ,
Which DBR are you facing this issue?
Most likely the issue is related to this: https://github.com/shadcn-ui/ui/issues/2837
If you are having this issue might be because of some browserextension. A quick test to confirm this theory is to...
A critical issue has arisen that is impacting our deployment planning for our client. We have encountered a challenge with our Azure CI/CD pipeline integration, specifically concerning the deployment of Python files (.py). Despite our best efforts, w...
Experiencing a similar issue that we are looking to resolve except the files are .sql. We have a process that has 1 orchestration notebook , calling multiple .sql files. These .sql files are being converted to regular databricks notebooks when deploy...