Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Error: The spark driver has stopped unexpected...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2023 06:15 AM
What is the problem?
I am getting this error every time I run a python notebook on my Repo in Databricks.
Background
The notebook where I am getting the error is a notebook that creates a dataframe and the last step is to write the dataframe to a Delta table already created in Databricks.
The dataframe created has approximately 16,000,000 records.
In thenotebook I don't have any display(), print(), ... command, only the creation of this dataframe through other created dataframes.
This notebook with the same amount of records was working a few days ago but now I am getting that error. I have been reading in other discussions in the chat and have seen that it could be a memory problem so I have taken the following steps:
- I have changed the configuration of the Cluster where I am running it. This configuration includes:
- Worker type: Standard_DS4_V2 28GB Memory, 8 Cores
- Driver type: Standard_DS5_V2 56GB Memory, 16 Cores
- Min workers: 2 and Max workers:8
- spark.databricks.io.cache.enabled true
- spark.databricks.driver.disableScalaOutput true
- I have run the notebook as part of a Job in order to use a Job Cluster.
- I deleted the part of the code where the data is copied into the existing delta table to check that the problem was not in that part and I still got the same error.
- I have tried restarting the cluster, stop attaching it and attach it to my notebook.
Could you help me? I don't know if the problem comes from the cluster configuration or from where, because a few days ago I was able to run the notebook without any problem.
Thank you so much in advance, I look forward to hearing from you.
Labels:
- Labels:
-
Memory Size


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2023 05:21 AM
Please set this configuration spark.databricks.python.defaultPythonRepl pythonshell for "Fatal error: The Python kernel is unresponsive" error.
However, I expect that the original issue i.e "Error: The spark driver has stopped unexpectedly and is restarting" will not be resolved with this. But you can give it a try.
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-03-2023 09:56 AM
Hi @Sara Corral , The issue happens when the driver is under memory pressure. It is difficult to tell from the provided information what is causing the driver to be under memory pressure. But here are some options you can try:
- set spark.driver.maxResultSize=6g (The default value for this is 4g. Also try running by setting this to 0 if 6g doesn't work)
- Please make sure you are not doing a collect operation on a big data frame
- Increase the size of the driver and worker to a larger instance
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-07-2023 04:29 AM
Thank you for your quick response.
Unfortunately, I have tried all the changes you mentioned but it still doesn't work. I have also been reading more about the cluster size recommendations on your website (https://docs.databricks.com/clusters/cluster-config-best-practices.html) and I have followed them (I have tried with a smaller number of workers but with a larger size of these), but the result is still the same error.
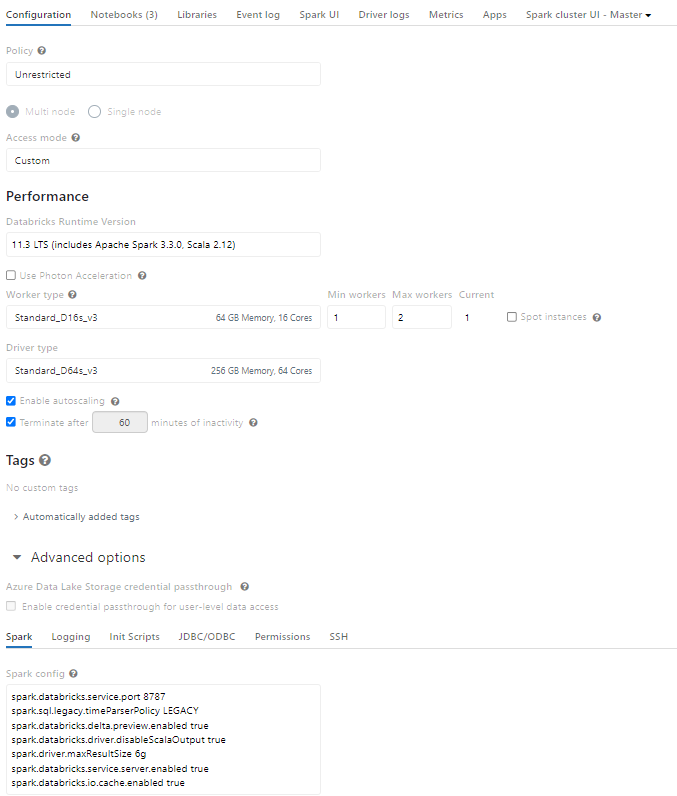
This is the current configuration I have in my cluster.

I have also tried to take a sample of only 5 records (so now our dataframe has 5 records and not 15.000.000) and surprisingly I'm having this error after more than 1h30 running:
Fatal error: The Python kernel is unresponsive.
During the modification of our original dataframe there is no problem, I get the error when I try to copy that data into a table (df.format("delta"). ... ).
In order to check if the problem was that write to the delta table, I have replaced that step by display(df) (which is now only 5 records) and I get exactly the same error.
Any idea what might be going on?
Thank you so much in advanced.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-09-2023 05:21 AM
Please set this configuration spark.databricks.python.defaultPythonRepl pythonshell for "Fatal error: The Python kernel is unresponsive" error.
However, I expect that the original issue i.e "Error: The spark driver has stopped unexpectedly and is restarting" will not be resolved with this. But you can give it a try.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-07-2023 01:10 PM
Hi! I'm on 12.2 LTS and getting a similar error. When I try this solution, I get an error ERROR PythonDriverWrapper: spark.databricks.python.defaultPythonRepl no longer supports pythonshell using ipykernel instead.
Any idea how I can fix?
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-10-2023 01:55 AM
Hi @Sara Corral
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?
This will also help other community members who may have similar questions in the future. Thank you for your participation and let us know if you need any further assistance!
Announcements





{kind=link}
Related Content
- MongoDB to databricks driver killed and compute re-attached in Data Engineering
- What is the most efficient way of running sentence-transformers on a Spark DataFrame column? in Machine Learning
- Driver terminated abnormally due to FORCE_KILL in Data Engineering
- Error : The spark driver has stopped unexpectedly and is restarting in Data Engineering
- Several executions of a single notebook lead to java.lang.OutOfMemoryError in Data Engineering