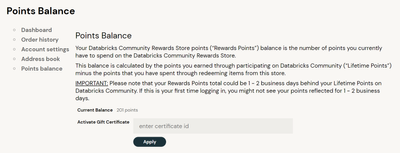
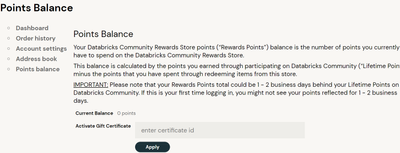
Hello all,Can anyone let me know about the "Activate Gift Certificate" option in Databricks Community Reward store? What is its purpose and how we can use it?
you earn points with forum interaction. Those points can be exchanged for 'credits'.With those credits you can buy Databricks swag.Your lifetime points (so the cumulated amount of points) are not affected by this.
I am using runtime 9.1LTSI have a R notebook that reads a csv into a R dataframe and does some transformations and finally is converted to spark dataframe using the createDataFrame function.after that when I call the display function on this spark da...
Hi @Manjusha Unnikrishnan Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question first. Or else bricksters will get back to you soon. Thanks.
@M Baig yes you need just to create service account for databricks and than assign storage admin role to bucket. After that you can mount GCS standard way:bucket_name = "<bucket-name>"mount_name = "<mount-name>"dbutils.fs.mount("gs://%s" % bucket_na...
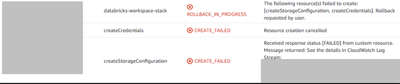
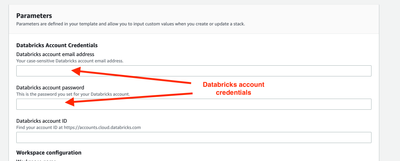
AWS quickstart - Cloudformation failureWhen deploying your workspace with the recommended AWS quickstart method, a Cloudformation template will be launched in your AWS account. If you experience a failure with the error message along the lines of ROL...
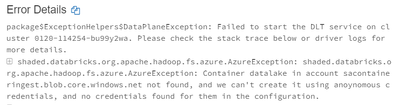
I am trying write data into Azure Datalake. I am reading files from Azure Blob Storage however when I try to create the Delta Live Table to Azure Datalake I get error the following errorshaded.databricks.azurebfs.org.apache.hadoop.fs.azurebfs.contrac...
@Kaniz Fatma I don't think you quite understand the question. I'm running into the same problem. When creating a Delta Live Table pipeline to write to Azure Data Lake Storage (abfss://etc...) as the Storage Location, the pipeline fails with the erro...
Hi Team,I have successfully passed the test after completion of the course. But i have not received any badge from your side. I have just been provided a certificate. Certificate ID:ID: E-E04YDVAs mentioned in the web portals i tried accessing "http...
Hi @Amarjeet Kumar , you will receive the badge in a day after completion. Even I received it a day after I cleared the exam. If you don't receive it the next day also, then you can raise a ticket at https://help.databricks.com/s/contact-us?ReqType...
it boils down to this:you earn points with forum interaction. Those points can be exchanged for 'credits'.With those credits you can buy Databricks swag.Your lifetime points (so the cumulated amount of points) are not affected by this.
So I was wondering who uses package cells in scala?We have this library (jar) which has some useful functions we use all over the place. But that's about it. So I think we can do the same thing without a jar but with package cells.But I never hear ...
Hi @Werner Stinckens Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help. We'd love to hear from you.T...
This is specific to creating new jobs, I understand that various permissions can be set on existing jobs using job access control. This seems to suggest no, I can't find anything in the Databricks docs either.
nope.Looked for that too, but it does not seem to be possible. Perhaps with Unity catalog, as there you have more permission controls.But using Unity is not an overnight decision.
Hi all,I have a quick currious. I know both query and dashboard page in Databricks SQL have refresh button to can them refresh. But one question it, when I'm in Dashboard page and click the refesh button. Does this thing also force every related quer...
The date field is getting changed while reading data from source .xls file to the dataframe. In the source xl file all columns are strings but i am not sure why date column alone behaves differentlyIn Source file date is 1/24/1947.In pyspark datafram...
how about using inferschema one single time to create a correct DF, then create a schema from the df-schema.something like this f.e.from pyspark.sql.types import StructType
# Save schema from the original DataFrame into json:
schema_json = df.s...
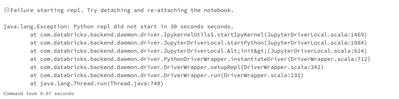
I have a Multi-Task Job that is running a bunch of PySpark notebooks and about 30-60% of the time, my jobs fail with the following error:I haven't seen any consistency with this error. I've had as many as all of the tasks in the job giving this error...
Hi. Did you ever got a resolution to this problem outside of rolling back to 10.4? I have recently moved some workloads over to runtime 11.3 and am experiencing intermittent "repl did not start in 30 seconds." errors.I have increased the repl timeout...
Hi @Ajay Pandey (Customer) , It would mean a lot if you could select the "Best Answer" to help others find the correct answer faster.This makes that answer appear right after the question, so it's easier to find within a thread.It also helps us m...